对于巨型互联网公司来说,为了控制数据规模,降低训练开销,降采样几乎是通用的手段,facebook 实践了两种降采样的方法,uniform subsampling 和 negative down sampling。
1、uniform subsampling
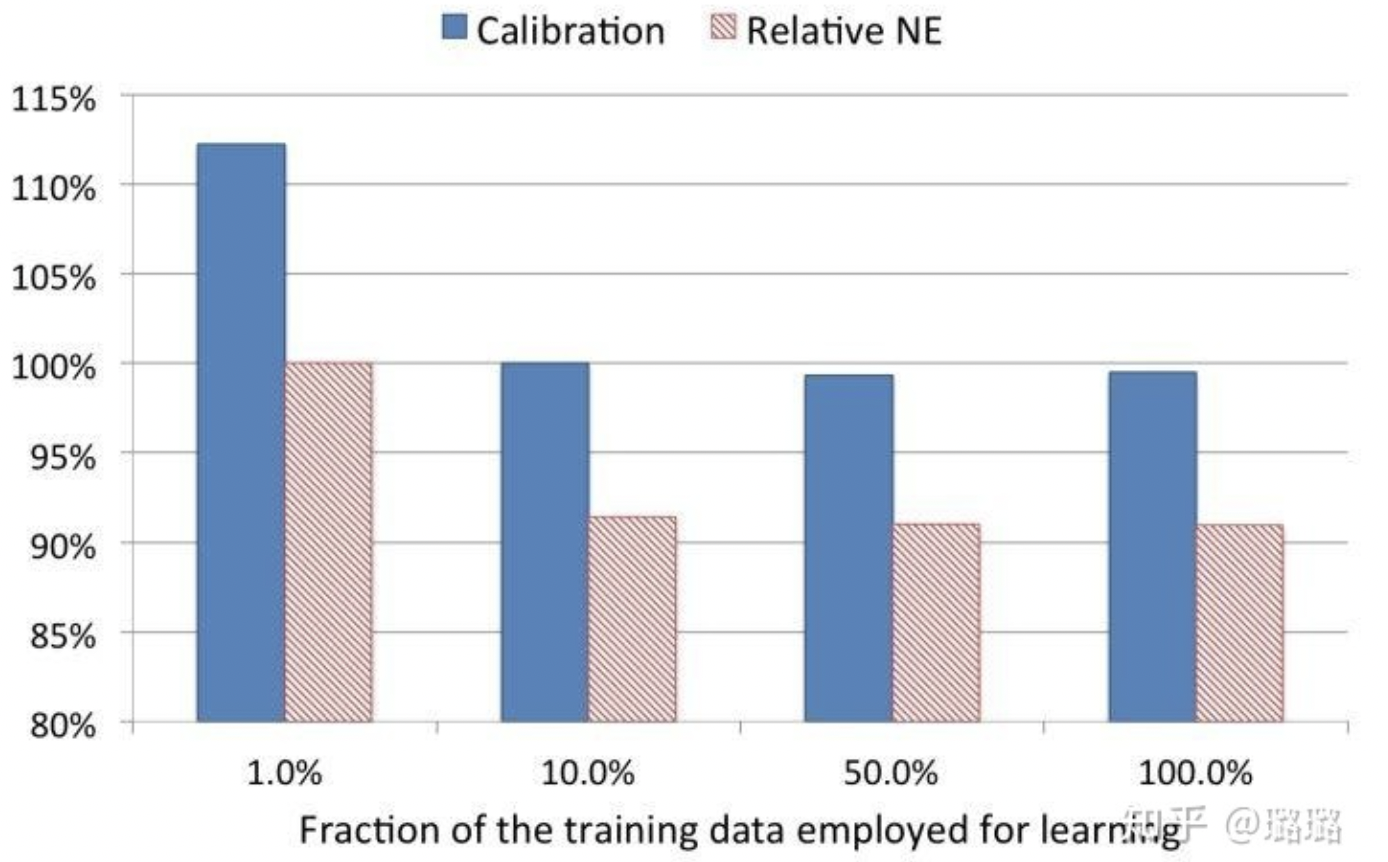
uniform subsampling 是对所有样本进行无差别的随机抽样,为选取最优的采样频率,facebook 试验了 0.001,0.01,0.1,0.5 和 1 五个采样频率,loss 的比较如下:当采样率是 10% 时,相比全量数据训练的模型,仅损失了不到 1% 的效果。
2、negative down sampling
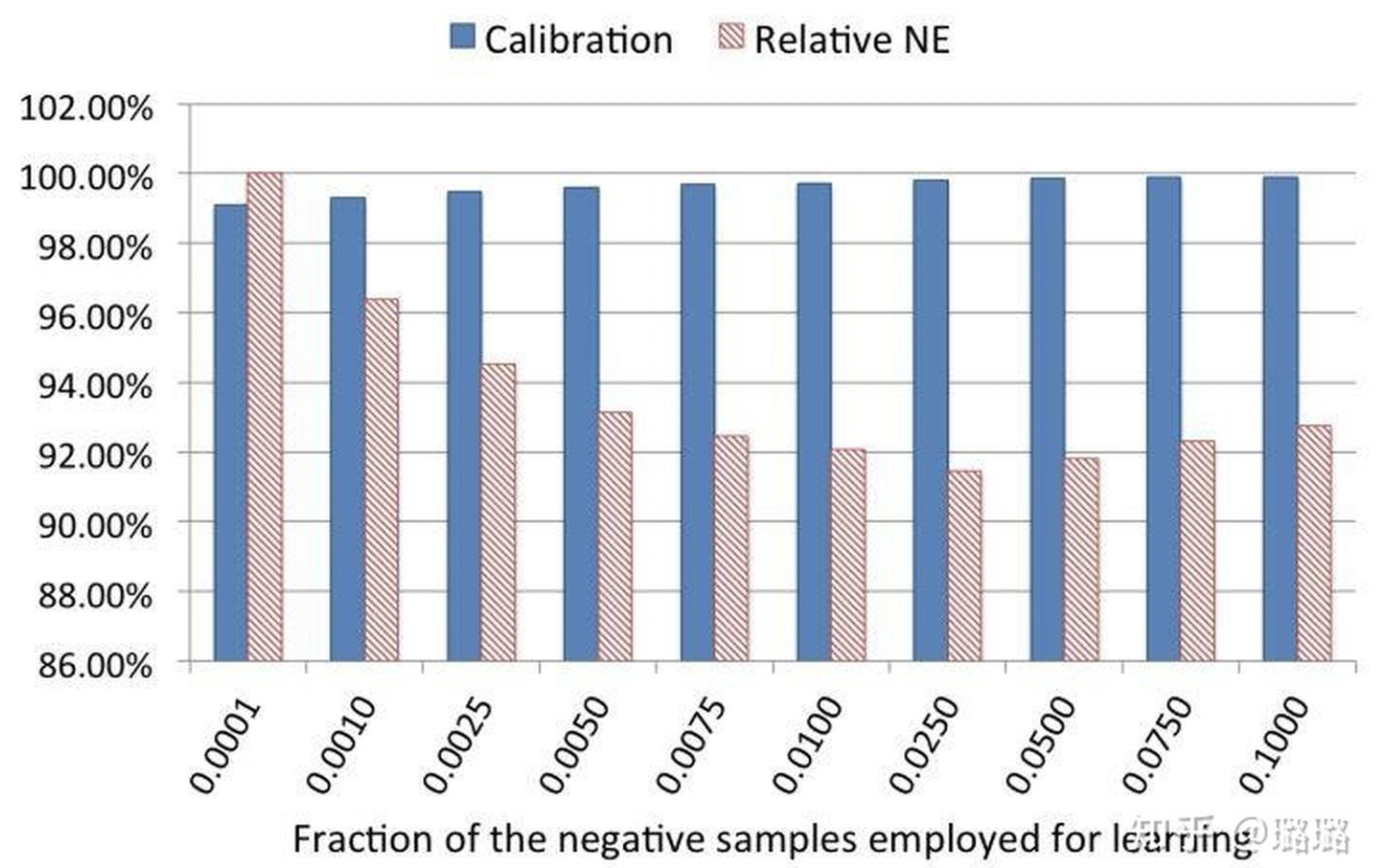
negative down sampling 保留全量正样本,对负样本进行降采样。除了提高训练效率外,负采样还直接解决了正负样本不均衡的问题,facebook 经验性的选择了从 0.0001 到 0.1 的一组负采样频率。当负采样频率在 0.025 时,loss 不仅优于更低的采样频率训练出来的模型,居然也优于负采样频率在 0.1 时训练出的模型。
3、ctr预估漂移&模型校正
负采样带来的问题是 CTR 预估值的漂移,比如真实 CTR 是 0.1%,进行 0.01 的负采样之后,CTR 将会攀升到 10% 左右。而为了进行准确的竞价以及 ROI 预估等,CTR 预估模型是要提供准确的有物理意义的 CTR 值的,因此在进行负采样后需要进行 CTR 的校正,使 CTR 模型的预估值的期望回到 0.1%。校正的公式如下:
![]()

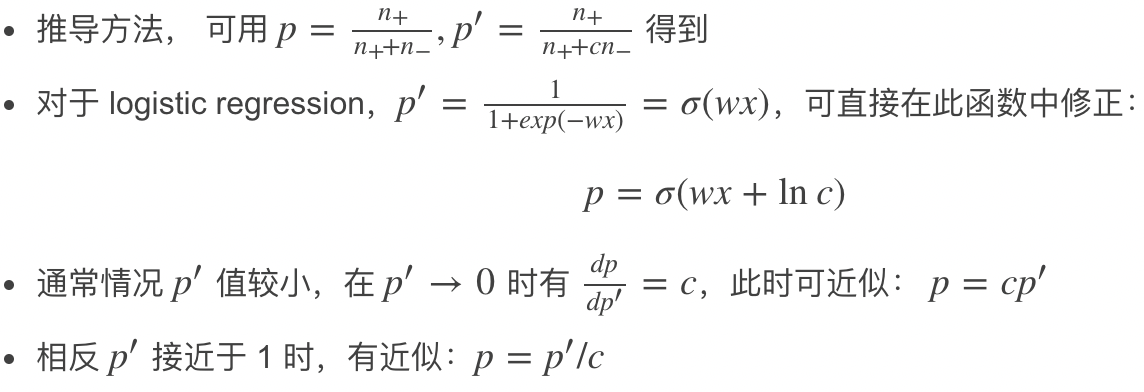
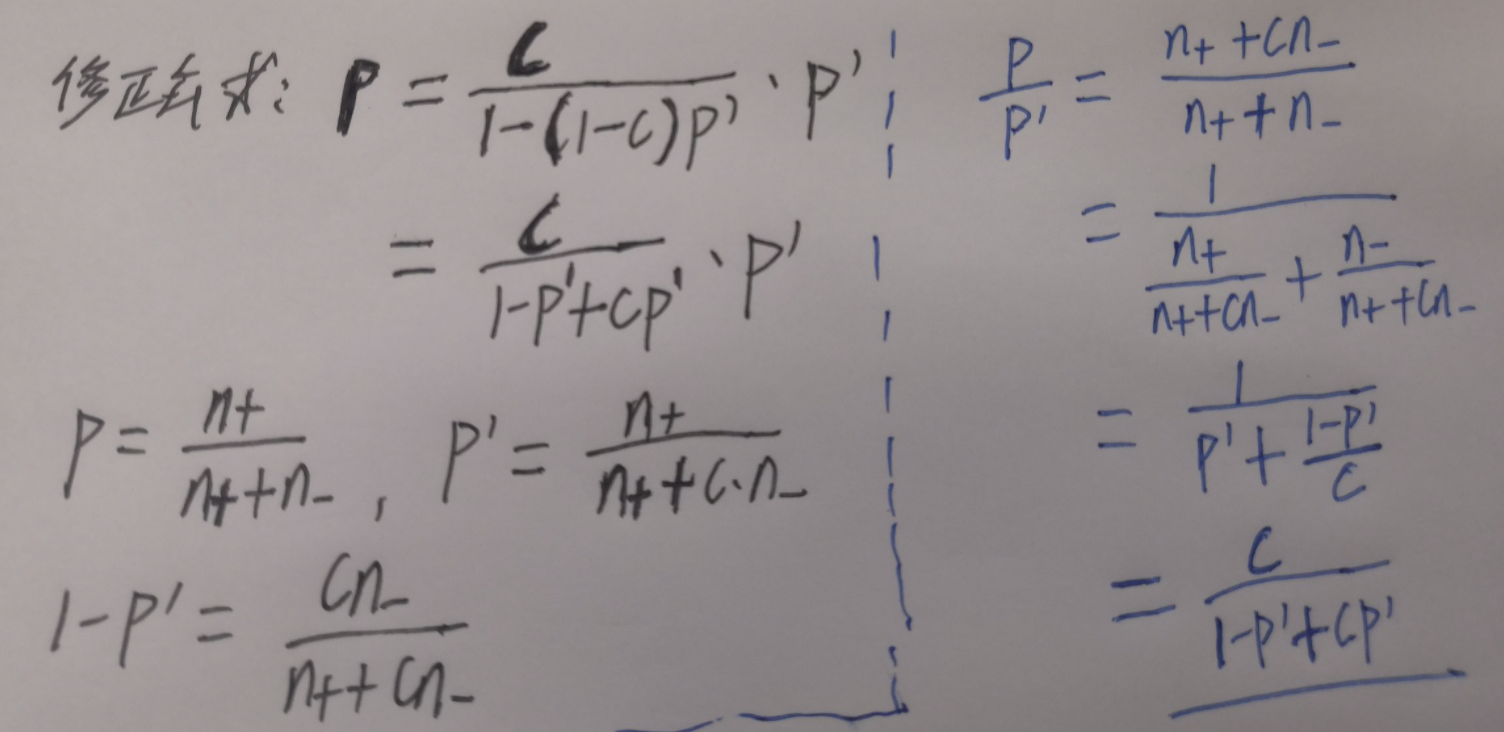
对于逻辑回归,参考文献3计算方式:
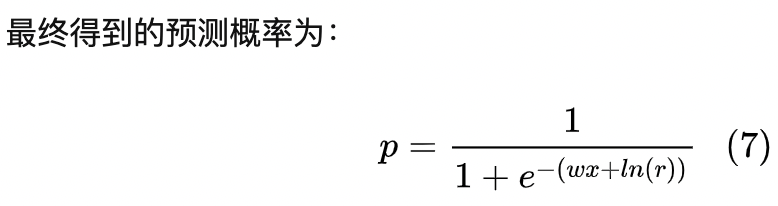
4、小经验
对于样本采样的一点心得,如果不是为了优化任务的复杂度或者优化训练的耗时,尽量不对样本进行采样,因为采样过后和原始数据的分布差异有变化,在线应用效果往往不好,即使通过变换,近似还原回原始分布,依然效果会比不采样有损失。很早以前训练展现时长模型就踩过坑,尝试过各种对负样本花式采样,一顿操作猛如虎,最后效果还是原始的好,当然为了优化任务的复杂度和训练耗时而进行的采样 是另外一回事了。