之前一直在学习关于滑块验证码的爬虫知识,最接近的当属于模拟人的行为进行鼠标移动,登录页面之后在获取了,由于一直找不到滑块验证码的原图,无法通过openCV获取当前滑块所需要移动的距离。
1.机智如我开始找关系通过截取滑块图片,然后经过PS,再进行比较(就差最后的验证了)
2.Selenium+Scrapy:登录部分--自己操作鼠标通过验证,登录之后页面--爬取静态页面
给大家讲了答题思路,现在就来拿实例验证一下可行性,拿自己博客开刀--"https://i.cnblogs.com"
二、先给大家看下效果,我不坑人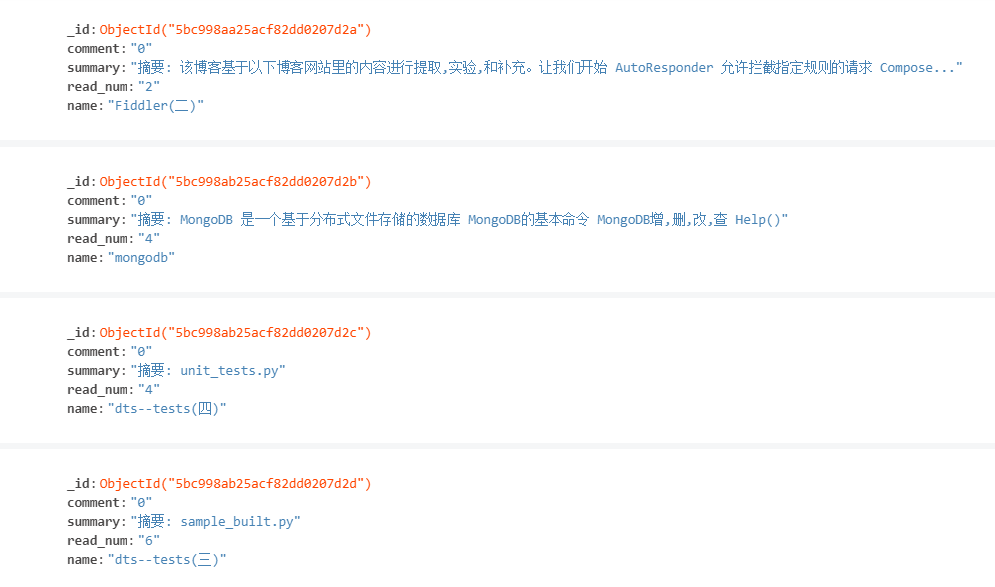
一、配置代码
1.1_items.py
import scrapy class BokeItem(scrapy.Item): name = scrapy.Field() summary = scrapy.Field() read_num = scrapy.Field() comment = scrapy.Field()
1.2_middlewares.py(设置代理)
class BokeSpiderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. def __init__(self,ip=''): self.ip = ip def process_request(self,request,spider): print('http://10.240.252.16:911') request.meta['proxy']= 'http://10.240.252.16:911'
1.3_pipelines.py(存储mongodb)
import scrapy import pymongo from scrapy.item import Item class BokePipeline(object): def process_item(self, item, spider): return item class MongoDBPipeline(object): #存储到mongodb中 @classmethod def from_crawler(cls,crawler): cls.DB_URL = crawler.settings.get("MONGO_DB_URL",'mongodb://localhost:27017/') cls.DB_NAME = crawler.settings.get("MONGO_DB_NAME",'scrapy_data') return cls() def open_spider(self,spider): self.client = pymongo.MongoClient(self.DB_URL) self.db = self.client[self.DB_NAME] def close_spider(self,spider): self.client.close() def process_item(self,item,spider): collection = self.db[spider.name] post = dict(item) if isinstance(item,Item) else item collection.insert(post) return item
1.4_settings.py(重要设置)
import random BOT_NAME = 'Boke' SPIDER_MODULES = ['Boke.spiders'] NEWSPIDER_MODULE = 'Boke.spiders' MONGO_DB_URL = 'mongodb://localhost:27017/' MONGO_DB_NAME = 'myboke' USER_AGENT =[ #设置浏览器的User_agent "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" ] FEED_EXPORT_FIELDS = ['name','summary','read_num','comment'] ROBOTSTXT_OBEY = False CONCURRENT_REQUESTS = 10 DOWNLOAD_DELAY = 0.5 COOKIES_ENABLED = False
# Crawled (400) <GET https://www.cnblogs.com/eilinge/> (referer: None)
DEFAULT_REQUEST_HEADERS = { 'User-Agent': random.choice(USER_AGENT), 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', }
DOWNLOADER_MIDDLEWARES = {
#'Boss.middlewares.BossDownloaderMiddleware': 543,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':543,
'Boke.middlewares.BokeSpiderMiddleware':123, }
ITEM_PIPELINES = {
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware':1,
'Boke.pipelines.MongoDBPipeline': 300, }
1.5_spiders/boke.py
#-*- coding:utf-8 -*- import time from selenium import webdriver import pdb from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.keys import Keys from lxml import etree import re from bs4 import BeautifulSoup import scrapy from Boke.items import BokeItem from Boke.settings import USER_AGENT from scrapy.linkextractors import LinkExtractor import random import re chrome_options = Options() driver = webdriver.Chrome() class BokeSpider(scrapy.Spider): name = 'boke' allowed_domains = ['www.cnblogs.com','passport.cnblogs.com'] start_urls = ['https://passport.cnblogs.com/user/signin'] def start_requests(self): driver.get( self.start_urls[0] ) time.sleep(3) driver.find_element_by_id('input1').send_keys(u'xxx') time.sleep(3) driver.find_element_by_id('input2').send_keys(u'xxx') time.sleep(3) driver.find_element_by_id('signin').click() time.sleep(20) new_url = driver.current_url.encode('utf8') print(driver.current_url.encode('utf8')) yield scrapy.Request(new_url) def parse(self, response): bokeitem = BokeItem() sels = response.css('div.day') for sel in sels: bokeitem['name'] = sel.css('div.postTitle>a ::text').extract()[0] bokeitem['summary'] = sel.css('div.c_b_p_desc ::text').extract()[0] summary = sel.css('div.postDesc ::text').extract()[0] bokeitem['read_num'] = re.findall(r'((d{0,5})',summary)[0] bokeitem['comment'] = re.findall(r'((d{0,5})', summary)[1] print bokeitem yield bokeitem