1. Bias-Variance Decomposition
bias:模型真实值与预测值之间的差距(模型本身问题)
variance:由于训练数据不同导致的误差
2. stability
variance小,bias大的模型
同一个数据集产生两个set,同一个training algorithm对其训练;若两个结果很像,则为stable,否则为unstable
stable:KNN,K越大越stable
unstable:decision tree
3. Ensemble methods:把几种方法组合起来
simple ensemble:
a) 少数服从多数
b) a基础上添加weight
mixture of experts:
a) 不同维度用不同方法做
b) 采取不同权重
4. Bagging method
针对unstable模型(low bias, high variance), 降低variance
不训练所有数据,有放回的从全部数据里抽取与原数据相同数量的数据
得到多个训练集,用其训练同一种算法,得到不同的模型,然后采取major vote
即:同一个机器学习算法,仍产生差异化
5. Random Forest
随机性更强,不仅data set是随机的,每个set里选取哪些features也是随机的
6. boosting
针对weak learner(high bias,low variance)效果仅比随机预测好一点
给每一个data增加了一个weight,先训练一个model,下一个model用来解决第一个model中没有解决的问题
对做错的部分,增加weight;做错的地方,减小weight
7. MLP

8. 7中采用sigmoid function是因为求导很简单
a(x) = 1 / (1 + e^-x)
a(x)的导数是a(x)(1-a(x))
td为真实值,od预测值,希望预测与真实差值的平方尽量小,利用这个不断更新w
故而利用error对w求导

9. MLP for classification(loss function)

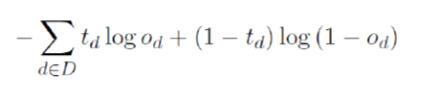
10. Deep learning---CNNs
1) Conv Layer: window遍历,对应相乘相加,直至遍历结束
但多数情况下不是只有一个channel
原图像的每一层与filter的每一层逐层进行操作,然后每一层加起来只得到一个结果
stride指步长,即filter移动时移动多少
zero-padding:周围补零,使output与input的size相同
output size:

weights per neuron: bias+F*F*3(默认情况下为3)
neurons:output size*output size
connections:neurons*weights per neuron
independent parameters:weights per neuron*number of filter
2) Pooling layer
downsampling,减小size
mean pool/max pool
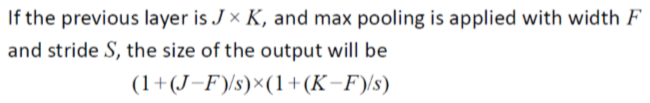
no independent parameters does this add to the model!!!
3) ReLU Layer(Rectified Linear Unit)
f(x) = max(0, x)
4) FC layer
将卷积层输出拉成一维形式.
11. Dropout
随机禁用一些节点,每一轮采用不同的禁用节点,避免overfitting
12. Loss Function
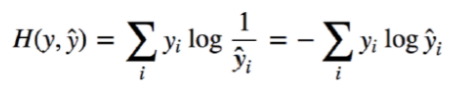
13. data augumentation
对一个图像进行物理变化,使其可以在不同的情况下也能进行实别
14. unsupervised learning
数据没有label信息
15. cluster analysis
a) hierarchical methods
a.1) K-means: 随机初始化k个中心点,将剩下的点都归到距离最近的中心点中
选取每个cluster的mean值作为新的中心点,不断重复
可以去除outliers,如那些距离中心点太远的
a.2) expectation maximization(EM)
有K个高斯分布,选取一个,产生一个数据点,,不断重复产生set。但是不知道产生数据的高斯分布的means都是什么以及哪个点是由哪个产生的
如两百个学生的身高数据已知,但是不知道学生性别信息
E step中,任选两个数字作为两个性别的mean值,根据mean判断每个数据由两个高斯分布产生的概率:p1/(p1+p2), p2/(p1+p2)
M step中,将概率作为已知值,更新μ1,μ2(前者对男生身高的均值)
对于200个数据,每个数据乘其是男生的概率,相加,再除以这些概率的和得到μ1;同时再乘是女生的概率,相加
新的μ作为新的mean,不断重复
每个数据都有一定概率属于两个cluster,不是一定属于某个cluster
a.3) Hierarchical Clustering
有bottom up以及top down两种形式
bottom up常见有三种方法:Single linkage, complete linkage, average linkage
single linkage即两个cluster之间的距离用两个cluster之间距离最近的两个点表示
complete linkage即用距离最远的两个点表示
average link: 平均值表示
centroid distance:用两个cluster之间的中心点之间的距离表示
对于single link来讲,先找最大的两个点合并,然后其对于本身的距离为1,别的点到其距离为别的店到原始两个点最近的,即更大的(数字代表相似度)
group average:即根据原始的数据,如12与3的关系,则求1 2 3三者之间的数据均找到求均值
想要几个cluster就在对应位置划开;几个cluster最好的确定方法有Elbow method
Elbow method即计算所有点到其中心点的距离的平方求和,将其与number of cluster对应图片画出来,拐点即为所求
或者采用silhouette plot,针对每一点计算a(i),即该点到同一cluster所有点距离的均值
d(i, c)即计算这个点到其他cluster所有点距离的均值,b(i)是其中的最小值
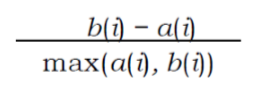
最好的情况是b(i)远大于a(i)
b) partitioning methods
16. PCA
降维的
17. autoencoders
将input dataencoder成features。再decoder成原始data,计算其与真实值之间的loss function,降低loss function,做到信息压缩