1. 环境变量PATH是告诉系统当我们在命令行输入一个命令时(如python,Scala),若当前目录下找不到这个程序,就去PATH里面找
2. echo $PATH查看当前系统环境变量
#注意设置环境变量时候的顺序
3. MapReduce
Hadoop体系里面用来计算的部分(数据存储,计算,工作协调)
Map做映射,Reduce做合并
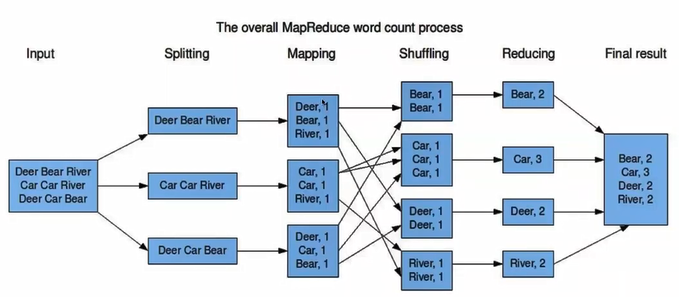
4. MapReduce特点:可以并行解决问题,即平行分布式解决问题,将结果合并
不需要关心容错处理等问题
5. Map将数据读取之后产生key-value对作为中间输出(如上图中的shuffling所示)
6. MapReduce的缺点(Spark的优点)
只适用于one-pass computation,即不可以来回调用中间结果,不可以进行迭代操作(iterative operations)
所有数据都存储在disk,需要重复调取。总要读写disk所以很慢
7. Spark的解决方案是将中间计算过程全存在内存里
Apache Spark也是开源的一个框架,也可以并行计算且以包含了容错率,不需要考虑
8. Spark Architecture
Driver Program是程序入口;cluster manager是调度资源的(判断哪个worker空闲可以使用);executor可以理解为线程,用来跑test
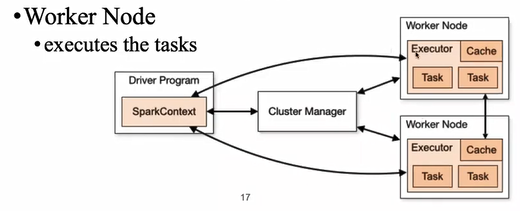
9. Spark RDD (Resilient Distributed Dataset)
RDD is where the data stays, the fundamental data structure of Apache Spark
可进行并行操作且已包含容错处理
10. RDD最重要的特点是in memory computation, fault tolerance以及lazy evaluation
11. Create RDDs两种方式
并行处理已经存储在driver program中的
在额外的存储系统中读进来
12. RDD Operations
a) transformations
一个RDD作为输入,一个或多个RDD作为输出
可分为Narrow以及Wide
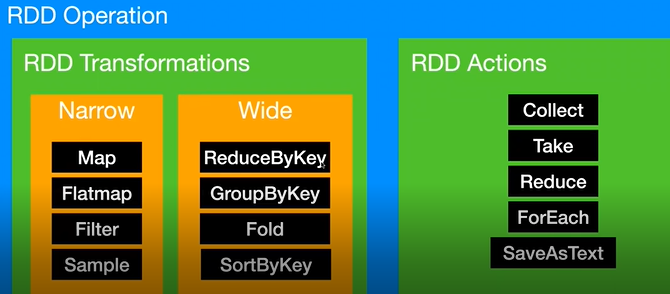
b) actions
即需要取得一个结果,collect为需要得到数据,take在collect基础上可以控制需要多少数据,Reduce作为合并结果,ForEach可以print出来看看效果
结果是RDD即为transformation,否则是action
13. setAppName是取的名字
14. map
rdd = sc.range(0,10)
rdd.map(lambda x : x+1)
[1,2,3,4,5,6,7,8,9,10]
15. flatmap扁平化
rdd2 = sc.parallelize([(1,5),(3,6),(4,99),(7,101)])
rdd2.flatMap(lambda x : x).collect()
[1,5,3,6,4,99,7,101]
将input打散并输出
16. Spark Lineage
为避免计算过程中数据分区的丢失,将记录RDD的Lineage(血统),一旦出现问题可以追溯其起源,以实现fault-tolerant
RDD lineage is the graph of all the ancestor RDDs of an RDD, 也被称作RDD operator graph或者RDD dependency graph
Nodes:RDDs
Edges:dependencies between RDDs
因为spark的计算全在内存中进行,没有中间文件也不可能重新读进文件,所以利用这种方式沿着Lineage重读文件
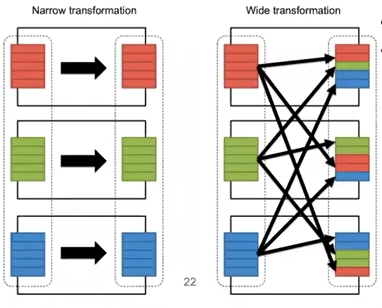
17. transformation不涉及到shuffling,narrow transformation;
涉及到data shuffling,wide transformation
或者从data分区的角度理解问题,如下图所示,wide transformation需要从别的分区调取数据
18. DAG是有向无环图,根据RDD之间的依赖关系将DAG分为不同的Stage
node: RDDs, results
edge: operations to be applied on RDD
不能有环的原因:RDD之间存在依赖关系,需要避免互相依赖陷入循环的情况
根据DAG的不同stage,stark可以分阶段的完成任务
划分根据宽依赖!!!(因为宽依赖中包含shuffle),窄依赖放在一个stage里面
划分好之后DAG scheduler将stages提交到task scheduler
number of tasks depends on the number of partitions