1. information retrieval:为了从大量资料中寻找满足条件的unstructured nature的文件(非结构化)的文件
举例来讲,从电脑中的很多文件中寻找含有某个单词的文件,可以使用Unix中的grep,经过逐行扫描,寻找目标单词并将含有该单词的文件返回。为了加速可以预先进行index,即将含有对应目标单词的文件标记为1,不包含的标记为0,再进行query的时候直接访问表格
2. Ad hoc retrieval: 根据客户需求提供符合要求的文件,这个query过程是一次性的且由客户决定query的内容
由于客户不会直白的发起query,所以需要information need。若文件符合客户的需要,称其为relevant
3. 评价标准
precision:返回文件中多少是我想要的
recall:返回文件中我想要的文件占应返回的所有文件的比例
4. 提前做出index的方法存在的问题:占用空间很大,matrix中含有大量的0,解决方法是inverted index
5. 建立inverted index
1)collect the documents to be indexed
2)将句子划分成一个个单词
3)将单词转化成更加通用的形式,如统一大小写,复数形式恢复成单数形式
4)index the documents that each term occurs in by creating an inverted index, consisting of a dictionary and postings
不考虑重复的将所有单词列出来,根据出自那篇文件对应给出docID,然后按照字母顺序进行排序,增加freq对几个文件中出现了该单词进行统计,matrix中删除多次出现的单词
posting lists链表形式记录在哪些文件中出现过
#doc,freq代表在几个文件中出现过,posting lists中1-2代表该单词在1、2中均出现过
6. inverted index分为dictionary与postings,可以节省内存空间(posting list是posting中的一条,实际操作中在dictionary中找到所需要的单词,然后调取相关的postings)内存中进存放dictionary,posting存放在硬盘中
含有两个个query条件的时候,如文件中既要有A又要有B,则找到AB分别对应的posting,用两个指针分别指向链条第一个元素,所相同则记录,若不同则将所指的文件数更小的那个指针往右移动一位,继续进行比较,直到两个指针走向末尾
7. query optimization优化:有多个query的时候,若执行and操作,执行的顺序是对freq小的优先进行合并
or则进行直接合并,所以and与or都有的情况下,先执行or,并得到新的freq,然后再根据freq小的优先原则执行and
8. skip pointers可以进一步提升速度,即在正常链表基础上增加skip的指令,pointers中包含了其指向的下一个数是多少
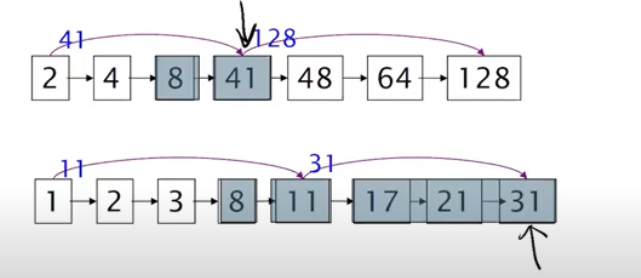
当第一个指针指向2时第二个指针指向1,更小的数字1上有一个指针指向11,111比2大故而不能skip,指针指向2,继续比较。当第一个指针指向41,第二个指针指向11时,11可以skip到31,31依然比41小,所以可以执行skip,从而节省时间
比较常用的skip的间距为根号P,P为链表的长度
9. Phase queries
即几个term作为整体必须按照一定顺序出现,如Stanford university
解决方法1:Biword indexes,将组合作为新的term
方法1的优化:extended Biwords,即上一种方法的升级版,POST(perform part-of-speech-tagging)标出单词词性,对形如NX*N的统称为extended biwords(即两个我们想要的名词之间夹着介词)
解决方法2:positional indexes,解决方法1中的false positive,即经过POST之后中间的内容被去掉了,可能由于中间夹杂着过多内容导致跟本来的意思相差很多
表示to的freq为993427,其中在doc ID为1的文件中出现16次,2中出现5次,1中出现的位置分别为7、18、33、72、86、231
有两个指针指向doc ID,当这两个指针所指doc ID相同时,看里面指向具体位置的新指针,记录两个指针差值小于等于规定值的情况,若差值已经大于规定值则直接break掉这个循环看下一个文件。
positional index的expected entries会随着document size的增加而增加
上面两个解决方法可以进行结合