1. data structure包含term,document frequency以及pointer to postings list
对dictionary的存储首先考虑hashtable,给每一个term一个integer,查找时的复杂度为O(1)
问题是不能进行模糊查询(minor variants),有新的单词加入字典后要重新赋予单词新的编号即rehashing。且没有prefix search(tolerant retrieval),即做一些简单的预处理如筛选所有以某一个前缀开头的单词
2. 为了可以进行prefix search首先考虑的是trees,比较常用的是B-trees,最简单的是binary trees。B-trees会将A到Z划分成几个区间,根据term的首字母在第几个区间进行一次prefix,然后继续细分直到找到对应的term。时间复杂度大于O(1)但是可以进行prefix。类似的还有tries,时间复杂度略快但是所占用的空间更大,所以没有trees常用
3. wild-card queries
mon*:找到前缀为mon的单词,即在mon≤w<moo范围内的单词
*mon:找到后缀为mon的单词,即从后向前重新创立一个B-trees,找到范围在nom≤w<non的单词
co*tion:即前缀后缀都规定好了,分别查找co*以及*tion,然后求两者交集。但是这种方法费时费力,所以可以采用permuterm index
4. permuterm index:在每一个term后面添加$,然后将单词不断旋转得到不同的形式,不同的几种形式都指向原本的单词,如下图所示,tree的大小与之前相比会增加4倍
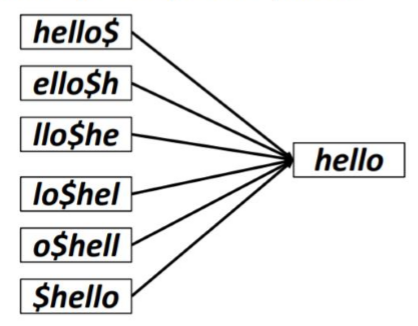
保证 * 一直在term的最后,如图所示,更加顺应B-tree的构架,以处理任何位置的模糊查询

5. 另一种方式是Bigarm indexes,从字母的角度来考虑问题。对于每一个单词,在它的开头和结尾各加上一个$,然后两个两个的组合在一起,如:

以此构建新的inverted index。在检索中,若查找mon*,即$m AND mo AND on,然后对其进行合并,最后还要做post-filter以确保即为所求。好处是很快且节省空间(不需要扩大4倍)
6. hardware basics
在memory里access data要比disk里面快很多;寻址时不能在disk里写入或读取数据。在disk里读取一整块的数据的速度也是很快的,相比于很多小块数据
7. BSBI:blocked sort-based indexing
每一个record是12bytes(term4+doc4+freq4),其中term与doc均为ID形式
文件很大的时候,可以定义10M的block,对每个block进行sort,然后合并。合并的时候可以进行binary merge,用一个merge tree进行
更高效的方法是multi-way merge,即对每个block首先只读取前几行数据,放入memory里进行读取。合并结束之后放回disk中,然后不断重复
8. I/O指input/output

number of passes计算需要多少层的合并,即merge tree的层数,NR是总共record的数量,BM是内存的大小,NR/BM即需要在内存里merge几次
input与output的总量一定,total里代表input+output两次,NR/B单位为block

summary of BSBI:将data分成多个block,每个block都刚好可以放进memory中进行排序。排序之后重新放回disk,等全部排序进行完毕后,merge。
9. BSBI的问题是term ID要一直存储在memory中,造成维护困难,所以引入SPIMI(SIngle-pass in-memory indexing)
不需要保存term与term ID之间的mapping,每一个block使用不用的dictionary;posting list不需要进行排序
实现方式是:当memory还有空间时,获取新的token(erm),判断新加进来的term是否在dictionary中,不在dictionary则加入;已经有了则找到它的位置,将term对应的posting ID增加到list中
每次memory满了之后进行排序,写入disk,然后merge(同上)
10. 还有一种方式为dynamic indexing,包含immediate merge(index很大,小的index加进来merge到大的里面);no merge(memory满了之后,在disk里写入sub-index,访问block就可以而不是整体进行访问,但是速度很慢);logarithmic indexing
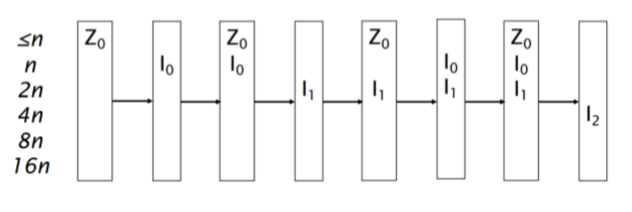
logarithmic indexing:小于等于n的时候,存在memory里面,即Z0,内存满了之后移入disk,I0,继续增加memory中的term。memory再次满了之后,由于已经有一个I0,两个I0merge成I1,综合了上面两点的优点