20155213 《信息安全系统设计基础》第十三周学习总结
| 本周重点学习了《深入理解计算机系统》的第10章——系统级I/O;同时本章介绍了三个级别的I/O的区别之处 |
内容
系统级I/O综述
- 所有语言的运行时系统都提供执行I/O的较高级别的工具。例如,标准I/O库;在UNIX系统中,是通过使用由内核提供的系统级I/O函数来实现这些较高级别的I/O函数的。介绍UNIX I/O和标准I/O的一般概念,展示在C程序中如何可靠地使用它们。
Unix I/O
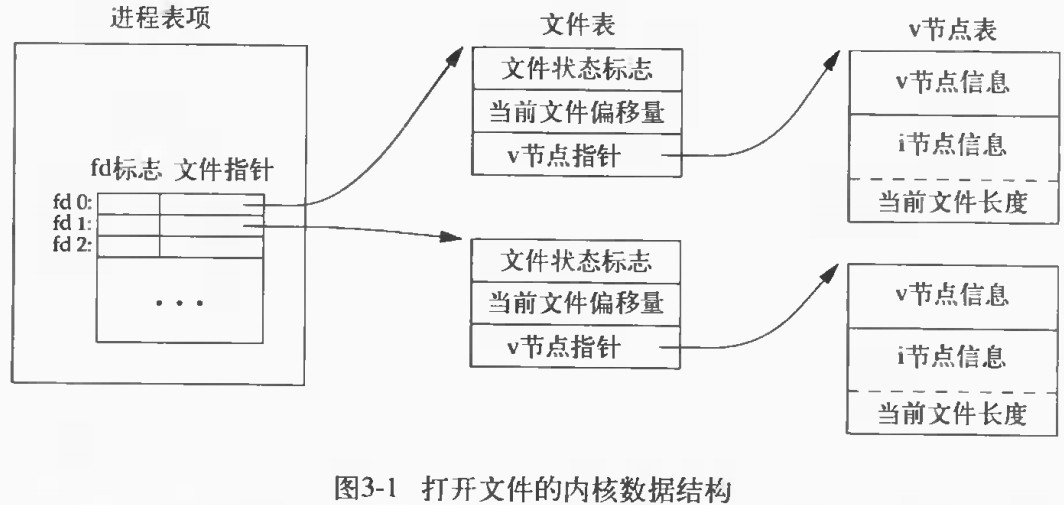
在UNIX系统中有一个说法,一切皆文件。所有的I/O设备,如网络、磁盘都被模型化为文件,而所有的输入和输出都被当做对相应文件的读和写来执行。这种将设备映射为文件的方式,允许UNIX内核引出一个简单、低级的应用接口,称为UNIX I/O,这使得所有的输入和输出都能以一种统一且一致的方式来执行。- 打开文件 打开文件操作完成以后才能对文件进行一系列的操作,打开完成过以后会返回一个文件描述符,它在后续对此文件的所有操作中标识这个文件,内核记录有关这个打开文件的所有信息。
-
打开文件的内核数据结构如下图:
-
打开文件的C中用的头文件及函数
-
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *name,int flags);
int open(const char *name,int flags,mode_t mode);
-
- 其中的flags必须是以下之一:O_RDONLY、O_WRONLY、O_RDWR,且mode的取值可参见下表:
| mode | 作用 |
|---|---|
| O_ASYNC | 当指定文件可写或者可读时产生一个信号(默认为SIGIO)。这个标志仅用于终端盒套接字,不能用于普通文件 |
| O_CREAT | 若此文件不存在,则创建它。使用此选项时,需要第三个参数mode,用其指定该新文件的访问权限位 |
| O_EXCL | 如果同时指定了O_CREAT,而文件已经存在,则会出错。用此可以测试一个文件是都存在,如果不存在,则创建此文件,这使此时和创建两者称为一个原子操作。 |
| O_TRUNC | 如果此文件存在,而且为只写或读写成功打开,则将其长度截短为0 |
| O_NONBLOC | 如果pathname值的是一个FIFO,一个块特殊文件或一个字符特殊文件,则此选项为文件的本次打开操作和后续的I/O操作设置非阻塞模式。 |
| O_NOCTTY | 如果pathname指的是终端设备,则不将该设备分配作为此进程的控制终端。 |
| O_DSYNC | 使每次write等待物理I/O操作完成,但是如果写操作并不影响读取放写入的数据,则不等待文件属性被更新 |
| O_RSYNC | 使每一个以文件描述符作为参数的read操作等待,直至任何对文件同一部分进行未决写操作都完成。 |
| O_SYNC | 使每次write都等到物理I/O操作完成,包括由write操作引起的文件属性更新所需的I/O |
- 改变当前的文件位置。
- 这既是系统修改i-node的行为
- 读写文件
- 读文件
#include <unistd.h>
ssize_t read(int fd,void *buf,size_t len);
-
-
- 该系统调用从有fd指向的文件的当前偏移量至多读len个字节到buf中,成功后,将返回写入buf中的字节数。出错则返回-1,并设置errno。有些错误时可以恢复的,例如,当read()调用在未读取任何字符前被一个信号打断,它会返回-1(如果是0,则可能和EOF混),并设置errno为EINTR。在这种情况下,可以重新提交读取请求。
- 写文件
-
#include <unistd.h>
ssize_t write(int fd,const void *char,ssize_t len);
-
-
- write调用从由文件描述符fd引用文件的当前位置开始,将buf中至多count个字节写入文件中,成功时,返回写入字节数,并更新文件位置。错误时,返回-1,并将errno设置为响应的值。一个write()可以返回0,只是表示写入了另个字节。write()不太可能返回一个部分写的结果。而且,对write()系统掉哟个来说没有EOF情况,对于普通文件,除非发生一个错误,否则write()将保证写入所有的请求,但是write返回出现-1情况也有可能是应为EINTR的中断的原因。
-
- 关闭文件 应用完成了对文件的访问之后,就通知内核关闭这个文件,内核释放文件打开时创建的数据结构,并将这个描述符恢复到可用的描述符池中。进程终止,内核也会关闭所有打开的文件并释放他们的存储器资源。
用RIO包健壮地读写
简介
RIO,全称 Robust I/O,即健壮的IO包。它提供了与系统I/O类似的函数接口,在读取操作时,RIO包加入了读缓冲区,一定程度上增加了程序的读取效率。另外,带缓冲的输入函数是线程安全的,这与Stevens的 UNP 3rd Edition(中文版) P74 中介绍的那个输入函数不同。UNP的那个版本的带缓冲的输入函数的缓冲区是以静态全局变量存在,所以对于多线程来说是不可重入的。RIO包中有专门的数据结构为每一个文件描述符都分配了相应的独立的读缓冲区,这样不同线程对不同文件描述符的读访问也就不会出现并发问题(然而若多线程同时读同一个文件描述符则有可能发生并发访问问题,需要利用锁机制封锁临界区)
- RIO数据结构
#define RIO_BUFSIZE 4096
typedef struct
{
int rio_fd; //与缓冲区绑定的文件描述符的编号
int rio_cnt; //缓冲区中还未读取的字节数
char *rio_bufptr; //当前下一个未读取字符的地址
char rio_buf[RIO_BUFSIZE];
}rio_t;
-
- 这个是rio的数据结构,通过
rio_readinitb(rio_t *, int)可以将文件描述符与rio数据结构绑定起来。注意到这里的rio_buf的大小是4096,这个参考了上图,为linux中文件的块大小——4k。
- 这个是rio的数据结构,通过
- RIO的输入输出函数源代码
void rio_readinitb(rio_t *rp, int fd)
/**
* @brief rio_readinitb rio_t 结构体初始化,并绑定文件描述符与缓冲区
*
* @param rp rio_t结构体
* @param fd 文件描述符
*/
{
rp->rio_fd = fd;
rp->rio_cnt = 0;
rp->rio_bufptr = rp->rio_buf;
return;
}
static ssize_t rio_read(rio_t *rp, char *usrbuf, size_t n)
/**
* @brief rio_read RIO--Robust I/O包 底层读取函数。当缓冲区数据充足时,此函数直接拷贝缓
* 冲区的数据给上层读取函数;当缓冲区不足时,该函数通过系统调用
* 从文件中读取最大数量的字节到缓冲区,再拷贝缓冲区数据给上层函数
*
* @param rp rio_t,里面包含了文件描述符和其对应的缓冲区数据
* @param usrbuf 读取的目的地址
* @param n 读取的字节数量
*
* @returns 返回真正读取到的字节数(<=n)
*/
{
int cnt;
while(rp->rio_cnt <= 0)
{
rp->rio_cnt = read(rp->rio_fd, rp->rio_buf, sizeof(rp->rio_buf));
if(rp->rio_cnt < 0)
{
if(errno != EINTR) //遇到中断类型错误的话应该进行读取,否则就返回错误
return -1;
}
else if(rp->rio_cnt == 0) //读取到了EOF
return 0;
else
rp->rio_bufptr = rp->rio_buf; //重置bufptr指针,令其指向第一个未读取字节,然后便退出循环
}
cnt = n;
if((size_t)rp->rio_cnt < n)
cnt = rp->rio_cnt;
memcpy(usrbuf, rp->rio_bufptr, n);
rp->rio_bufptr += cnt; //读取后需要更新指针
rp->rio_cnt -= cnt; //未读取字节也会减少
return cnt;
}
ssize_t rio_readnb(rio_t *rp, void *usrbuf, size_t n)
/**
* @brief rio_readnb 供用户使用的读取函数。从缓冲区中读取最大maxlen字节数据
*
* @param rp rio_t,文件描述符与其对应的缓冲区
* @param usrbuf void *, 目的地址
* @param n size_t, 用户想要读取的字节数量
*
* @returns 真正读取到的字节数。读到EOF返回0,读取失败返回-1。
*/
{
size_t leftcnt = n;
ssize_t nread;
char *buf = (char *)usrbuf;
while(leftcnt > 0)
{
if((nread = rio_read(rp, buf, n)) < 0)
{
if(errno == EINTR) //其实这里可以不用判断EINTR,rio_read()中已经对其处理了
nread = 0;
else
return -1;
}
leftcnt -= nread;
buf += nread;
}
return n-leftcnt;
}
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
/**
* @brief rio_readlineb 读取一行的数据,遇到'
'结尾代表一行
*
* @param rp rio_t包
* @param usrbuf 用户地址,即目的地址
* @param maxlen size_t, 一行最大的长度。若一行数据超过最大长度,则以'�'截断
*
* @returns 真正读取到的字符数量
*/
{
size_t n;
int rd;
char c, *bufp = (char *)usrbuf;
for(n=1; n<maxlen; n++) //n代表已接收字符的数量
{
if((rd=rio_read(rp, &c, 1)) == 1)
{
*bufp++ = c;
if(c == '
')
break;
}
else if(rd == 0) //没有接收到数据
{
if(n == 1) //如果第一次循环就没接收到数据,则代表无数据可接收
return 0;
else
break;
}
else
return -1;
}
*bufp = 0;
return n;
}
ssize_t rio_writen(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nwritten;
char *bufp = (char *)usrbuf;
while(nleft > 0)
{
if((nwritten = write(fd, bufp, nleft)) <= 0)
{
if(errno == EINTR)
nwritten = 0;
else
return -1;
}
bufp += nwritten;
nleft -= nwritten;
}
return n;
}
-
- 以上便是rio的基本输入输出函数。注意到
rio_writen(int fd, void *, size_t)代表文件描述符的参数是int类型,而不是rio_t类型。因为rio_writen不需要写缓冲。
- 以上便是rio的基本输入输出函数。注意到
-
RIO包会自动处理读写文件值出现的不足值。其提供了两类不同的函数:
- 无缓冲的输入输出函数:这些函数直接存在存储器和文件之间传送数据,没有应用级缓冲·。它们将对二进制数据读写到网络和从网络中读写二进制数据尤其有用。
- 带缓冲的输入函数:这些函数允许高效地从文件中读取文本行和二进制数据,这些文件的内容缓存在应用级缓冲区内,类似于为像printf这样的标准I/O函数提供的缓冲区
读取文件元数据
文件的元数据简介
-
什么是元数据
- 任何文件系统中的数据分为数据和元数据。数据是指普通文件中的实际数据,而元
数据指用来描述一个文件的特征的系统数据,诸如访问权限、文件拥有者以及文件数据
块的分布信息(inode...)等等。在集群文件系统中,分布信息包括文件在磁盘上的位置以及磁盘在集群中的位置。用户需要操作一个文件必须首先得到它的元数据,才能定位到文件的位置并且得到文件的内容或相关属性。
- 任何文件系统中的数据分为数据和元数据。数据是指普通文件中的实际数据,而元
-
通过
man 2 stat得到以下结论:- 截图
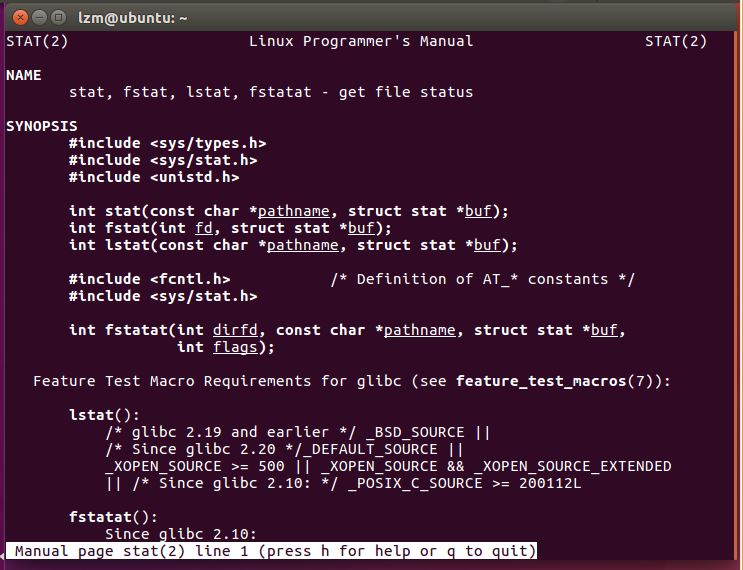
- 截图
-
linux C中可用函数声明:
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
int stat(const char *path, struct stat *buf);
int fstat(int fd, struct stat *buf);
int lstat(const char *path, struct stat *buf);
注意:stat和lstat不同之处在于如果是link文件,stat获取的是link文件信息,lstat获取的是link文件指向文件的信息
*
* 函数参数:1.文件描述符或者文件路径 2.stat结构体
stat结构体定义:
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* inode number */
mode_t st_mode; /* protection */
nlink_t st_nlink; /* number of hard links */
uid_t st_uid; /* user ID of owner */
gid_t st_gid; /* group ID of owner */
dev_t st_rdev; /* device ID (if special file) */
off_t st_size; /* total size, in bytes */
blksize_t st_blksize; /* blocksize for filesystem I/O */
blkcnt_t st_blocks; /* number of 512B blocks allocated */
time_t st_atime; /* time of last access */
time_t st_mtime; /* time of last modification */
time_t st_ctime; /* time of last status change */
};
-
- 返回值:成功返回0,失败返回-1
I/O重定向
I/O重定向简介
- 在Unix系统中,每个进程都有
STDIN、STDOUT和STDERR这3种标准I/O,它们是程序最通用的输入输出方式。几乎所有语言都有相应的标准I/O函数,比如,C语言可以通过scanf从终端输入字符,通过printf向终端输出字符。熟悉Shell的朋友都知道,我们可以方便地对Shell命令进行I/O重定向,比如find -name "*.java" >testfile.txt把当前目录下的Java文件列表重定向到testfile.txt。多数情况下,我们只需要了解I/O重定向的使用就够了,但是如果要编程实现类似Shell的I/O重定向以及管道功能,那么就需要清楚它的原理和实现。
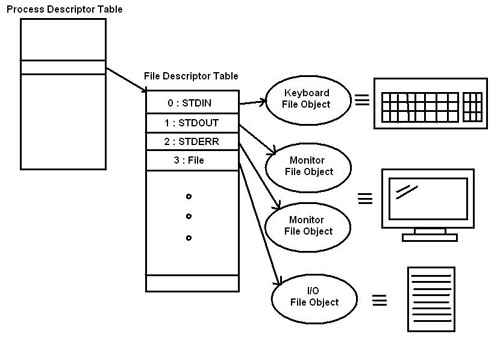
文件描述表
理解I/O重定向的原理需要从Linux内核为进程所维护的关键数据结构入手。对Linux进程来讲,每个打开的文件都是通过文件描述符(File Descriptor)来标识的,内核为每个进程维护了一个文件描述符表,这个表以FD为索引,再进一步指向文件的详细信息。在进程创建时,内核为进程默认创建了0、1、2三个特殊的FD,这就是STDIN、STDOUT和STDERR,如下图所示意:
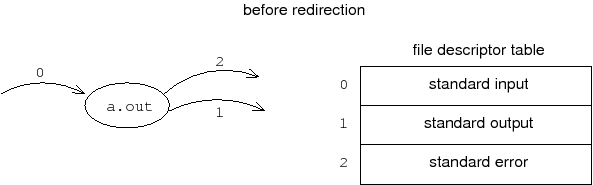
所谓的I/O重定向也就是让已创建的FD指向其他文件。比如,下面是对STDOUT重定向到testfile.txt前后内核文件描述符表变化的示意图
重定向前
重定向后
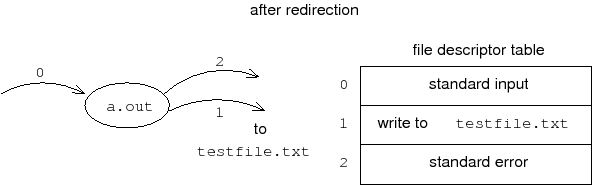
C中如何I/O重定向
-
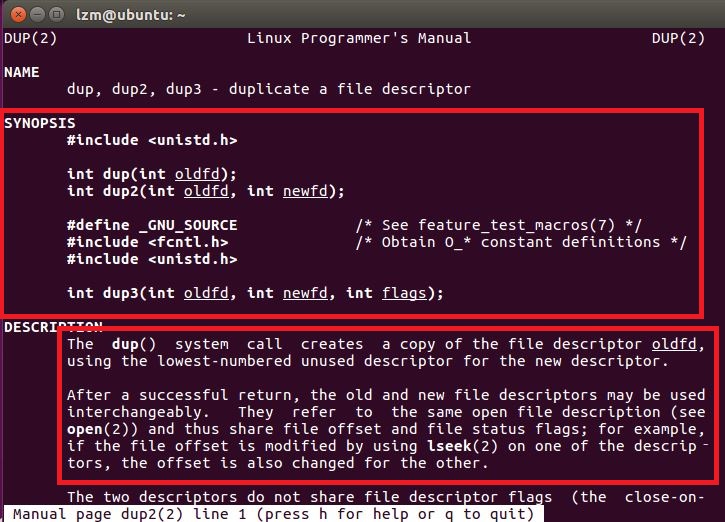
上面介绍了文件描述符表和I/O重定向的原理,那么在Linux系统中如何通过C程序实现I/O重定向呢?主要用到了dup2()这个系统调用,man中关于dup2是这样说的:
-
这里我们通过一个实际的问题来说明它的使用方法:
编写一个C程序,通过调用sort这个Shell命令进行排序,要求把in.txt和out.txt分别重定向到sort的STDIN,STDOUT。
int main() {
int pid = 0;
// fork a worker process
if (pid = fork()) {
// wait for completion of the child process
int status;
waitpid(pid, &status, 0);
}
else {
// open input and output files
int fd_in = open("in.txt", O_RDONLY);
int fd_out = open("out.txt", O_CREAT | O_RDWR, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
if (fd_in > 0 && fd_out > 0) {
// redirect STDIN/STDOUT for this process
dup2(fd_in, 0);
dup2(fd_out, 1);
// call shell command
system("sort");
close(fd_in);
close(fd_out);
}
else {
// ... error handling
}
}
return 0;
}
- 运行截图


课后习题
10.6
下面程序输出是什么?
#include "csapp.h"
int main()
{
int fd1,fd2;
fd1=Open("foo.txt",O_RDONLY,0);
fd2=Open("foo.txt",O_RDONLY,0);
Close(fd2);
fd2=Open("baz.txt",O_RDONLY,0);
printf("fd2=%d
",fd2);
exit(0);
}
问题解答:
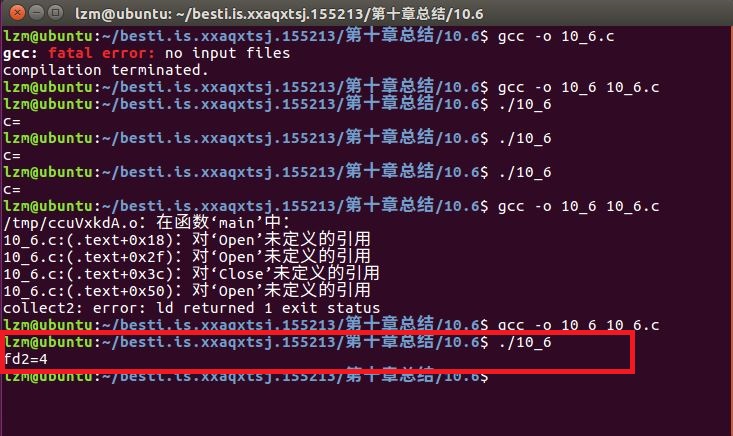
由图分析得:输出 fd2 = 4
已经有0 1 2被打开,fd1是3,fd2是4,关闭fd2之后再打开,还是4。
10.7
修改图10-5中所示的cpfile程序,使得它用RIO函数从标准输
入复制到标准输出,一次MAX-BUF个字节。
问题解答:
- 根据要求写得算法程序:
#include "csapp.h"
int main(int argc, char **argv)
{
int n;
rio_t rio;
char buf[MAXBUF];
Rio_readinitb(&rio, STDIN_FILENO);
while((n = Rio_readnb(&rio, buf, MAXBUF)) != 0)
Rio_writen(STDOUT_FILENO, buf, n);
}
解答:STDIN_FILENO属于系统API接口库,其声明为 int 型,是一个打开文件句柄,对应的函数主要包括 open/read/write/close 等系统级调用。
操作系统一级提供的文件API都是以文件描述符来表示文件。STDIN_FILENO就是标准输入设备(一般是键盘)的文件描述符。
所以所得出的结论就是:输入输出改为了键盘的输入,由屏幕输出,使用RIO输入输出提高其健壮性。
-
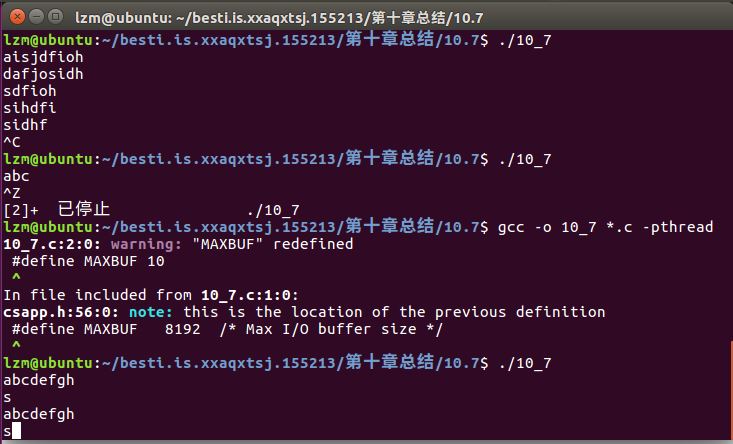
题目运行出现的问题:
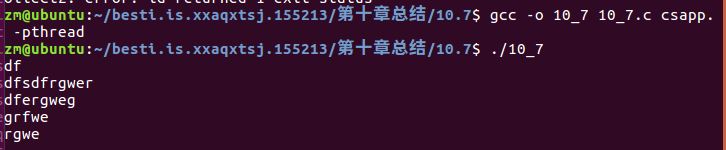
-
- 问题解决:出现的这个问题在于MAXBUF的宏定义上,因为宏定义是8192个字节,故在短短的输入一点的字符是不会有相应的输出的,将宏定义改为10就好了。
10.8
- 问题解决:出现的这个问题在于MAXBUF的宏定义上,因为宏定义是8192个字节,故在短短的输入一点的字符是不会有相应的输出的,将宏定义改为10就好了。
编写图10-10中的statcheck程序的一个版本,叫做fstatcheck
,它从命令行上取得一个描述符数字而不是文件名。
问题解答:
- 依据要求写得如下代码:
/* $begin statcheck */
#include "csapp.h"
int main (int argc, char **argv)
{
struct stat stat;
char *type, *readok;
/* $end statcheck */
if (argc != 2) {
fprintf(stderr, "usage: %s <filename>
", argv[0]);
exit(0);
}
/* $begin statcheck */
fstat(atoi(argv[1]), &stat);
if (S_ISREG(stat.st_mode)) /* Determine file type */
type = "regular";
else if (S_ISDIR(stat.st_mode))
type = "directory";
else
type = "other";
if ((stat.st_mode & S_IRUSR)) /* Check read access */
readok = "yes";
else
readok = "no";
printf("type: %s, read: %s
", type, readok);
exit(0);
}
/* $end statcheck */
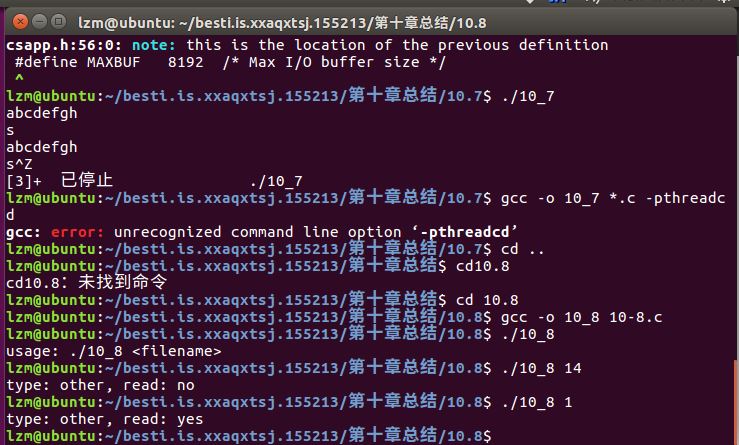
解答:其实整个我们只需要将stat那句话改为: fstat(atoi(argv[1]), &stat);
但当然,如果需要加其他处理的话(比如判断参数对错,fd是否存在等等)。
10.9

- 问题解决:
- 这里应该是表明,输入重定向到了foo.txt,然而3这个描述符是不存在的。
说明foo.txt并没有单独的描述符3。
所以Shell执行的代码应该是这样的:
- 这里应该是表明,输入重定向到了foo.txt,然而3这个描述符是不存在的。
if (Fork() == 0) {/* Child */
int fd = open("foo.txt", O_RDONLY, 0);
dup2(fd, 1);
close(fd);
Execve("fstatcheck", argv, envp);
}
10.10

- 问题解决:
- 依据问题写出来的代码
int main(int argc, char **argv)
{
int n;
rio_t rio;
char buf[MAXLINE];
if(argc == 2){
int fd = open(argv[2], O_RDONLY, 0);
dup2(fd, STDIN_FILENO);
close(fd);
}
Rio_readinitb(&rio, STDIN_FILENO);
while((n = Rio_readlineb(&rio, buf, MAXLINE)) != 0)
Rio_writen(STDOUT_FILENO, buf, n);
}

-
- 解答:这里使用一个重定向的技术即可。如果参数个数为2,那么就将标准输入重定向到文件。
程序并没有检测各种错误。
- 解答:这里使用一个重定向的技术即可。如果参数个数为2,那么就将标准输入重定向到文件。