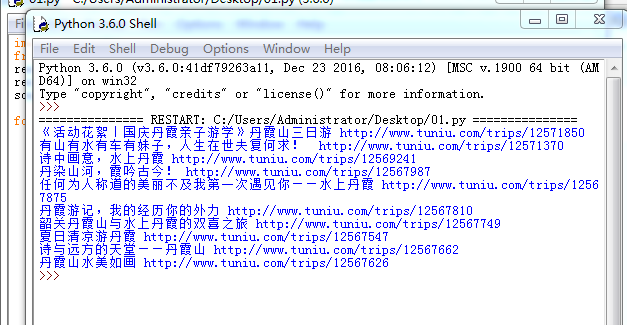
1.选一个自己感兴趣的主题。我选的是途牛网,并定位到自己家乡韶关。
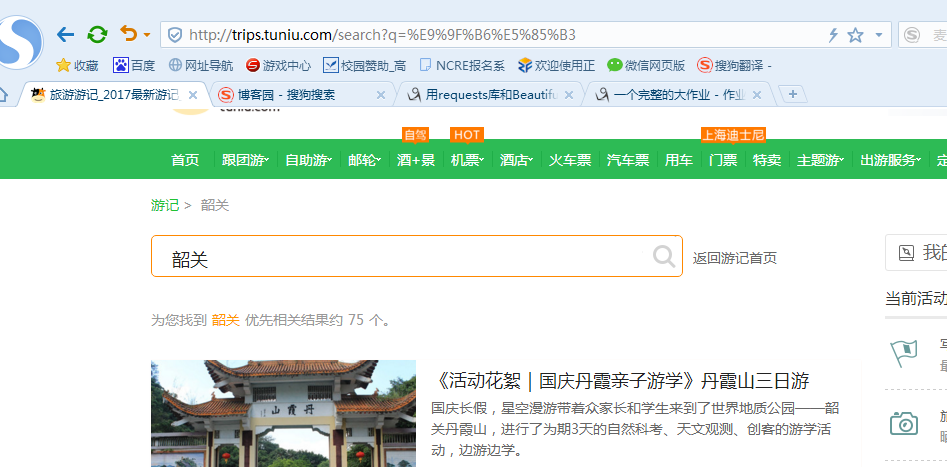
2.网络上爬取相关的数据,截取网站的标题以及来源。
import requests
from bs4 import BeautifulSoup
res=requests.get('http://trips.tuniu.com/search?q=%E9%9F%B6%E5%85%B3')
res.encoding='utf-8'
soup=BeautifulSoup(res.text,'html.parser')
for trips in soup.select('li'):
if len(trips.select('.list-name'))>0:
title=trips.select('.list-name')[0].text
url=trips.select('a')[0]['href']
print(title,url)
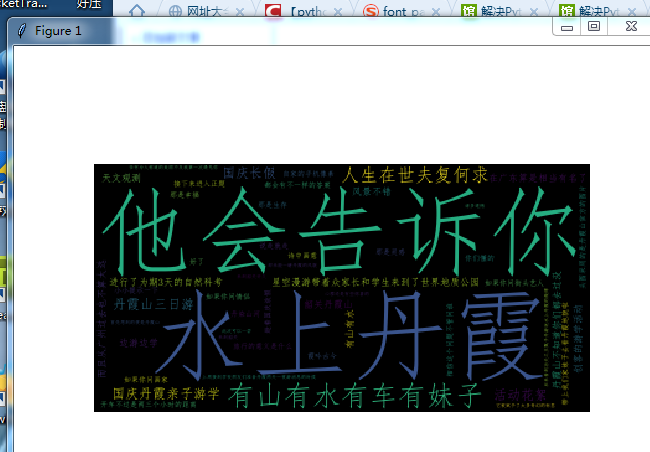
3.进行文本分析,生成词云。我将网站复制下来,使用字典的方法统计出出现次数最多的20个词,并去掉一些符号。
import jieba
fr=open("tuniu.txt",'r',encoding='utf-8')
s=list(jieba.cut(fr.read()))
exp={',','
','.','。','”','“',':','…',' ','?','(',')','*',':','1',';'}
key=set(s)-exp
dic={}
for i in key:
dic[i]=s.count(i)
wc=list(dic.items())
wc.sort(key=lambda x:x[1],reverse=True)
for i in range(20):
print(wc[i])
fr.close()

生成词云。生成词云中遇到很多问题,其中找字体就是一个最麻烦的事。用中文制作词云必须设置字体,否则词云中的中文会变成方框。
#coding:utf-8
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
text =open("tuniu.txt",'r',encoding='utf-8').read()
print(text)
wordlist = jieba.cut(text,cut_all=True)
wl_split = "/".join(wordlist)
mywc = WordCloud(
font_path="simfang.ttf"
).generate(text)
plt.imshow(mywc)
plt.axis("off")
plt.show()