1. 数据拼接分为纵向拼接和横向拼接
(1)纵向拼接,字面意思,将另一张表的数据填充到原始数据的下面。纵向拼接,可以使用 data 步中的 set,也可以使用 proc 步中的 append。
原始数据1:
data Mysas.data1; input name $ age sex $; cards; zhou 25 f wang 28 m li 27 f wu 23 m ; run;
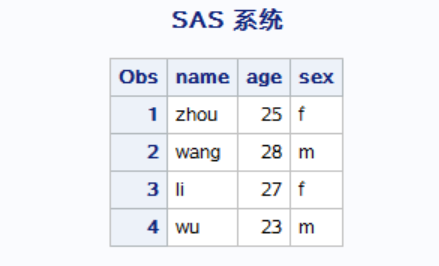
原始数据2:
data Mysas.data2; input name $ age sex $; cards; zhao 32 f sun 31 m qian 30 f zhen 37 m ;

使用 data 步中的 set 拼接:
data Mysas.data1; input name $ age sex $; cards; zhou 25 f wang 28 m li 27 f wu 23 m ; run; data Mysas.data2; input name $ age sex $; cards; zhao 32 f sun 31 m qian 30 f zhen 37 m ; data Mysas.result; set Mysas.data1 Mysas.data2; run; proc print data = Mysas.result; run;
结果为: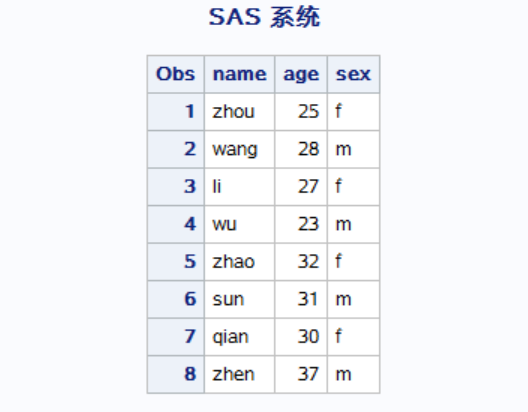
使用 proc 步中的 append 来拼接,虽然效率比 set 高,但是不建议,因为 append 拼接数据,会损坏原始数据:
data Mysas.data1; input name $ age sex $; cards; zhou 25 f wang 28 m li 27 f wu 23 m ; run; data Mysas.data2; input name $ age sex $; cards; zhao 32 f sun 31 m qian 30 f zhen 37 m ; /* 这里的 force 是强制拼接 */ proc append base=Mysas.data1 data=Mysas.data2 force; run; proc print data = Mysas.result; run;
(2)横向拼接,只是数据按照变量来横向排列,对于重复的变量名,SAS 会自动覆盖。横向拼接又分为:by 变量、无 by 变量。
原始数据为: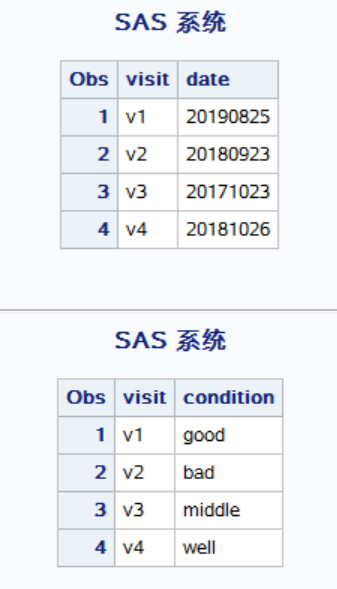
无 by 变量的代码:
data data3; input visit $ date $; cards; v1 20190825 v2 20180923 v3 20171023 v4 20181026 ; run; proc print data = data3; run; data data4; input visit $ condition $; cards; v1 good v2 bad v3 middle v4 well ; run; proc print data = data4; run; data result; merge data3 data4; run; proc print data = result; run;
结果为
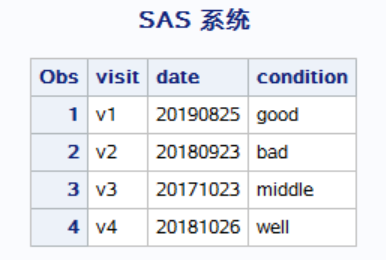
有 by 变量的代码:
data data3; input visit $ date $; cards; v1 20190825 v2 20180923 v3 20171023 v4 20181026 ; run; proc print data = data3; run; data data4; input visit $ condition $; cards; v1 good v2 bad v3 middle v4 well ; run; proc print data = data4; run; data result; merge data3 data4; by visit; run; proc print data = result; run;
结果为:
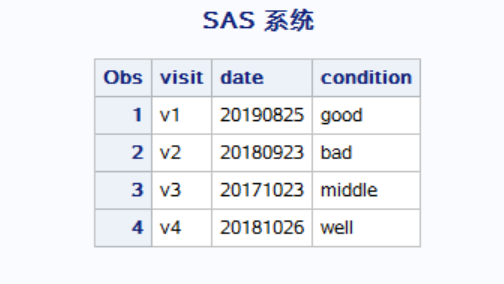
虽然结果是一样的,但是对于有无 by 还是有很大的区别的
无 by 而言,merge 是按照一行一行来的,就是左边一行,右边一行,直接 merge
有 by 而言,merge 是按照 by 的变量来 merge 的,而不是按照一行一行来的