Python 3中的默认编码
Python3中默认是UTF-8
可查看Python3的默认编码。
>>> import sys >>> >>> sys.getdefaultencoding() 'utf-8' >>>
系统默认编码 指:
在python 3编译器读取.py文件时,若没有头文件编码声明,则默认使用“utf-8”来对.py文件进行解码。并且在调用 encode()这个函数时,不传参的话默认是“ utf-8 ”。(这与下面的open( )函数中的“encoding”参数要做区分)
本地默认编码 指:
在你编写的python 3程序时,若使用了 open( )函数 ,而不给它传入 “ encoding ” 这个参数,那么会自动使用本地 Windows 或 Linux 的默认编码。没错,如果在Windows系统中,就是默认用gbk格式!所以请大家在这里注意:linux中可以不用传“ encoding” 的参数, 而win中不能忘了“ encoding” 的参数)
utf-8是可变长的的编码,有1个字节的英文字符,也有2个字节的阿拉伯文,也有3个字节的中文和日文。utf-8是有严格定义的,一个字节的字符高位必须是0;三个字节的字符中,第一个字节的高位是1110开头。
gbk对英文是使用单字节编码(也就意味着兼容ascii),而gbk对中文部分是采取定长的2字节,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间。所以说它只要没有碰到尾字节在40之内的字符,都会一股脑地按照2字节去解码成中文。而中文在 utf-8 编码后,一般是三字节的。当解码的字节数和编码的字节数不匹配时,自然会造成全是乱码的局面。
实际上unicode就是一个字符集,一个字符与数字一一对应的映射关系,因为它一律以2个字节编码(或者也有4个字节的,这里不讨论),所以占用空间会大一些,一般只用于内存中的编码使用。
而 utf-8 是为了实现unicode 的传输和存储的。因为它可变长,存英文时候可以节省大量存储空间。传输时候也节省流量。
进程在内存中的表现是“ unicode ”的编码;当python3编译器读取磁盘上的.py文件时,是默认使用“utf-8”的;当进程中出现open(), write() 这样的存储代码时,需要与磁盘进行存储交互时,则是默认使用操作系统的默认编码。
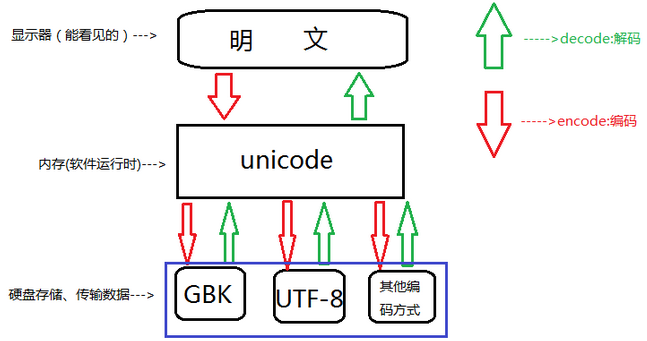
Python 3中的encode和decode
Python3中字符编码经常会使用到decode和encode函数。特别是在抓取网页中,这两个函数用的熟练非常有好处。encode的作用,使我们看到的直观的字符转换成计算机内的字节形式。decode刚好相反,把字节形式的字符转换成直观的形式。
>>> "西安".encode() b'\xe8\xa5\xbf\xe5\xae\x89' >>> b'\xe8\xa5\xbf\xe5\xae\x89'.decode() '西安'
\x表示后面是十六进制
在Python 3中, 以字节形式表示的字符串则必须加上前缀b,也就是写成上文的b'xxxx'形式。
UTF-8兼容ASCII
Python3中的编码转换
字符以Unicode的字节形式表现出来
>>> "西安".encode('unicode-escape') b'\\u897f\\u5b89' >>> b'\\u897f\\u5b89'.decode('unicode-escape') '西安'
如果我们知道一个Unicode字节码,怎么变成UTF-8的字节码,先decode,再encode。
>>> "西安".encode('unicode-escape') b'\\u897f\\u5b89' >>> "西安".encode('unicode-escape').decode('unicode-escape') '西安' >>> "西安".encode('unicode-escape').decode('unicode-escape').encode() b'\xe8\xa5\xbf\xe5\xae\x89'
源代码文件中,如果有用到非ASCII字符,则需要在文件头部进行字符编码的声明,如下:
#-*- coding: UTF-8 -*-
python3中的字符序列也有两种类型:bytes和str。python3中的bytes和python2中的str相似,str和python2中的unicode相似。这里要注意,str类型在python3和python2中都有,但含义完全变了。
unicode_string=u'中国' print(len(unicode_string)) print( type(unicode_string)) str_string = unicode_string.encode('utf-8') print(len(str_string)) str_string print(type(str_string)) >>> unicode_string=u'中国' >>> print(len(unicode_string)) 2 >>> print( type(unicode_string)) <class 'str'> >>> str_string = unicode_string.encode('utf-8') >>> print(len(str_string)) 6 >>> str_string b'\xe4\xb8\xad\xe5\x9b\xbd' >>> print(type(str_string)) <class 'bytes'>
UnicodeEncoderError
将文本转化为字节序列时,若有字符在目标编码中没有定义,则会出现UnicodeEncoderError。
由于中文字符在ascii编码中无定义,则会报出编码错误。对于此类问题,需选择合适的编码类型,比如含有中文字符,一般用UTF-8编码类型对unicode字符串编码。
>>> unicode_string=u'平国' >>> unicode_string.encode('ascii') Traceback (most recent call last): File "<stdin>", line 1, in <module> UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
UnicodeDecodeError
把二进制序列转化为文本时,遇到无法转换的字节序列,则会发生此异常。比如用UTF-8编码后的二进制序列,用GB2312解码,由于两种编码不兼容,用GB2312不能识别字节序列,则会出现异常。
unicode_string=u'中国' utf8_string=unicode_string.encode('utf-8') utf8_string.decode('GB2312')
碰到这种异常,是由于decode使用的编码和字节序列的编码不一致,可以用字符编码侦测包chardet检测字节序列的编码,然后再用此编码解码。
import chardet ### pip install chardet utf8_string=u"中国" str_type=chardet.detect(utf8_string) str_type
#python 3,str和bytes类型相互转换工具类 #file:python3_endecode_helper.py def to_str(bytes_or_str): if isinstance(bytes_or_str,bytes): value = bytes_or_str.decode('UTF-8') else: value = bytes_or_str return value def to_bytes(bytes_or_str): if isinstance(bytes_or_str,str): value = bytes_or_str.encode('UTF-8') else: value = bytes_or_str return value if __name__=='__main__': str_string = u'中国' value = to_bytes(str_string) print(type(value)) #<class 'bytes'> value = to_str(value) print(type(value)) #<class 'str'>
# coding:gbk import sys import locale def p(f): print('%s.%s(): %s' % (f.__module__, f.__name__, f())) # 返回当前系统所使用的默认字符编码 p(sys.getdefaultencoding) # 返回用于转换Unicode文件名至系统文件名所使用的编码 p(sys.getfilesystemencoding) # 获取默认的区域设置并返回元组(语言, 编码) p(locale.getdefaultlocale) # 返回用户设定的文本数据编码 # 文档提到this function only returns a guess p(locale.getpreferredencoding) # 在笔者的Windows上的结果 # sys.getdefaultencoding(): utf-8 # sys.getfilesystemencoding(): utf-8 # locale.getdefaultlocale(): ('en_US', 'cp936') # locale.getpreferredencoding(): cp936
REF
https://www.cnblogs.com/killianxu/p/9746545.html
https://www.cnblogs.com/huxi/archive/2010/12/05/1897271.html
https://blog.csdn.net/ym01213/article/details/89083428
https://zhuanlan.zhihu.com/p/40834093