神经网络训练过程的窗口能不弹出来吗?
net.trainParam.showWindow = false;
net.trainParam.showCommandLine = false;
------------------------
net.trainParam.show=NaN (经过测试,此方法不行)
------------------------
newrb.m文件里是这样显示的
function [net,tr]=newrb(p,t,goal,spread,mn,df)
。。。
% DISPLAY
if isfinite(df) & (~rem(k,df))
fprintf('NEWRB, neurons = %g, MSE = %g\n',k,MSE);
flag_stop=plotperf(tr,eg,'NEWRB',k);
end
。。。
它不用showwindow这样的参数控制,要不显示注释掉最方便了
------------------------
net.trainParam.showWindow = false; (经过测试,此方法不行)
------------------------
可以把显示的刷新次数设置的很大很大(经过测试,此方法不行)
------------------------
------------------------
DISABLE NNTRAINTOOL WINDOW
How to hide nntraintool window
http://www.mathworks.com/matlabcentral/newsreader/view_thread/288528
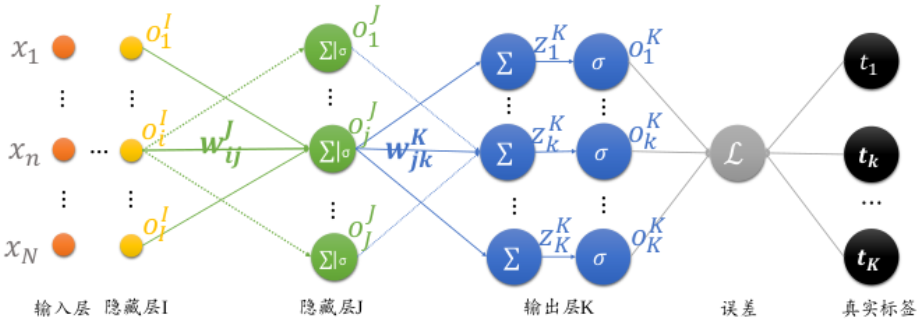
神经网络的训练主要包括两个部分:正向传播和反向传播两个过程。正向传播得到损失值,反向传播得到梯度。最后通过梯度值完成权值更新。所谓梯度其实就是一个偏导数向量,但是我们经常说的仍是‘x的梯度’而不是‘x的偏导数’。
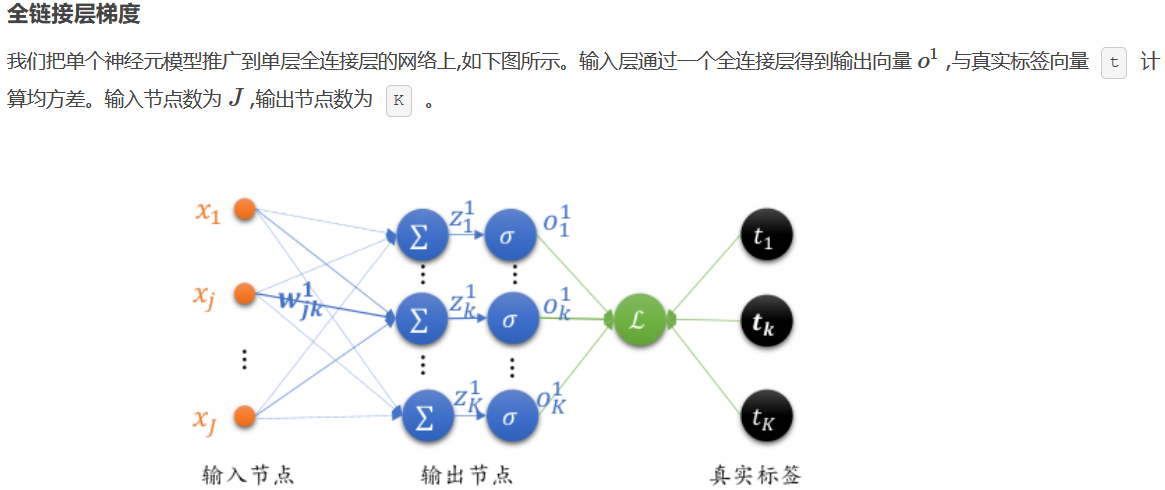
整个网络的输出值为 ak, 这个输出值将与期望的目标值 tk 比较,得到一个误差,神经网络训练的目的,就是找到参数w,b使得误差最小。取误差平方和作为目标函数,定义如下:

寻找这个参数的方法采用梯度下降法,即计算所有参数的梯度(偏导数)
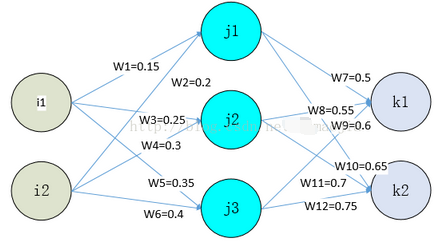
输入数据:i1=0.05, i2=0.1
输出数据:k1=0.01, k2=0.99
偏置 bj=1, 所对应的初始权重为0.45
bk=1, 所对应的初始权重为0.85
激活函数: sigmoid函数
初始权重为上述所标识的
一. 前向传播
1 .输入层到隐藏层:

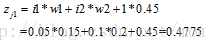
神经元j1的输出值为:

同理,可以计算
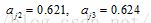
2.隐藏层到输出层:
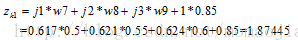
神经元k1的输出值为:
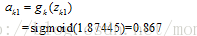
同理,可以计算

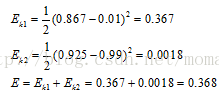
接下来进行反向传播,通过求梯度,更新权值。

yk为常数;


下面我们来计算均方差算是函数的梯度
由于单个神经元只有一个输出,那么损失函数可以表示为

因为 z=x1w1+x2w2+...+xjwj+...+b ,所以 






REF
GOOD
https://blog.csdn.net/momaojia/article/details/76269468 (正向传播)
https://www.cnblogs.com/jsfantasy/p/12177275.html (反向传播)
https://blog.csdn.net/qq_29407397/article/details/90599460
https://zhuanlan.zhihu.com/p/26765585
https://zhuanlan.zhihu.com/p/45190898
https://www.jianshu.com/p/74bb815f612e
https://segmentfault.com/a/1190000021529971