脚本示例:
import io.gatling.core.Predef._
import io.gatling.http.Predef._
import scala.concurrent.duration._
class BaiduSimulation extends Simulation {
//读取配置文件
val conf = ConfigFactory.load()
//实例化请求方法
val httpProtocol = http.baseUrl(conf.getString("baseUrl"))
//包装请求接口
val rootEndPointUsers = scenario("信贷重构")
.exec(http("信贷重构-授信申请")
.post("/apply")
.header("Content-Type", "application/json")
.header("Accept-Encoding", "gzip")
.body(RawFileBody("computerdatabase/recordedsimulation/0001_request.json"))
.check(status.is(200)
.saveAs("myresponse") )
.check(bodyString.saveAs("Get_bodys")))
.exec{
session => println("这就是传说的值传递"+session("Get_bodys").as[String] )
session
}
}
配置文件(application.properties):
#新信贷通用接口
baseUrl = http://172.16.3.179:7800
脚本编写:
Gatling脚本的编写主要包含三个步骤:
1. http head配置
2. Scenario 执行细节
3. setUp 组装
编写实例:
//配置文件地址src/galting/resource/application.properties
//使用的时候 初始化配置文件的读
val conf = ConfigFactory.load()
报头定义:
//设置请求的根路径
val httpConf = http.baseURL(conf.getString("baseUrl"))
这里需要知道的是报头也可以在seniario中定义(有下列两种方式去设置Json和xml要求的报头)
//http(...).get(...).asJSON等同于:
http(...).get(...)
.header(HttpHeaderNames.ContentType,HttpHeaderValues.ApplicationJson)
.header(HttpHeaderNames.accept,HttpHeaderValues.ApplicationJson)
//http(...).get(...).asXML等同于
http(...).get(...)
.header(HttpHeaderNames.ContentType,HttpHeaderValues.ApplicationXml)
.header(HttpHeaderNames.accept,HttpHeaderValues.ApplicationXml)
场景定义:
val rootEndPointUsers = scenario("信贷重构").exec(http("信贷重构-授信申请").post("/apply"))
场景的定义要有名称,原因是同一个模拟器中可以 定义多个场景,场景通常被存储在Scala的变量中
场景的基本机构有两种
exec :用来描述行动,通常是发送到待测应用的一个请求
pause: 用来模拟连续请求的用户思考时间
模拟器的定义:
//设置线程数
setUp(rootEndPointUsers.inject(atOnceUsers(10)).protocols(httpConf))
模拟器的参数:
setUp( rootEndPointUsers.inject(
nothingFor(4 seconds), // 1
atOnceUsers(10), // 2
rampUsers(10) over(5 seconds), // 3
constantUsersPerSec(20) during(15 seconds), // 4
constantUsersPerSec(20) during(15 seconds) randomized, // 5
rampUsersPerSec(10) to 20 during(10 minutes), // 6
rampUsersPerSec(10) to 20 during(10 minutes) randomized, // 7
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds), // 8
splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy atOnceUsers(30), // 9
heavisideUsers(1000) over(20 seconds) // 10
).protocols(httpConf)
)
| 函数 | 解释 |
| nothingFor(4 seconds) | 等待一个指定的时间 |
| atOnceUsers(10) | 一次性注入指定数量的用户 |
| ampUsers(10) over(5 seconds) | 在指定的时间内,以线性增长的方式注入指定数量的用户 |
| constantUsersPerSec(20) during(15 seconds) | 在指定的时间内,以固定频率注入用户,以每秒的多少用户的方式。固定时间间隔 |
| constantUsersPerSec(20) during(15 seconds) randomized | 在指定时间段内,用固定的频率注入用户,以每秒多少个用户的方式定义。用户以随机间隔注 |
| ampUsersPerSec(10) to 20 during(10 minutes) | 在指定时间段内,从起始频率到目标频率注入用户,以每秒多少个用户的方式定义。用户以固定间隔注入 |
| rampUsersPerSec(10) to 20 during(10 minutes) randomized | 在指定时间段内,从起始频率到目标频率注入用户,以每秒多少个用户的方式定义。用户以随机间隔注入 |
| splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy(10 seconds) | 在指定时间内,重复执行定义好的 注入步骤,间隔指定时间,直到达到最大用户数nbUsers |
| splitUsers(1000) into(rampUsers(10) over(10 seconds)) separatedBy atOnceUsers(30) | 在指定时间内,重复执行定义好的 第一个注入步骤,间隔定义好的 第二个注入步骤,直到达到最大用户数nbUsers |
设置场景属性的时候 需要注意以下两点:
开放的负载:
封闭系统,您可以控制并发的使用数量
封闭系统是并发用户数量有上限的系统。在满负荷运行时,新用户只能在另一个用户退出时才能有效地进入系统
封闭的负载:
开放系统,您可以控制用户的到达率
相反,开放系统无法控制并发用户的数量:即使应用程序无法为用户提供服务,用户也会不断地到达。大多数网站都是这样的
重点注意:
如果您希望根据每秒请求数而不是并发用户数进行推理,那么可以考虑使用constantUsersPerSec()来设置用户的到达率,从而设置请求数,而不需要进行节流,因为在大多数情况下这是多余的
技巧篇:
对于测试中的数据构造 往往是我们比较痛苦的地方 虽然Gatling中提供了参数生成 但是并不能满足我们的测试需求 ,凭借之前对其他工具的理解 同时Gatling
也是运行在java虚拟机中这两点 我尝试了将自己的java工具类放到Gatling中调用 从而进行参数的构造。
下面开始介绍我的做法:
1、在Gatling 工程中的resource 目录下创建一个lib 目录
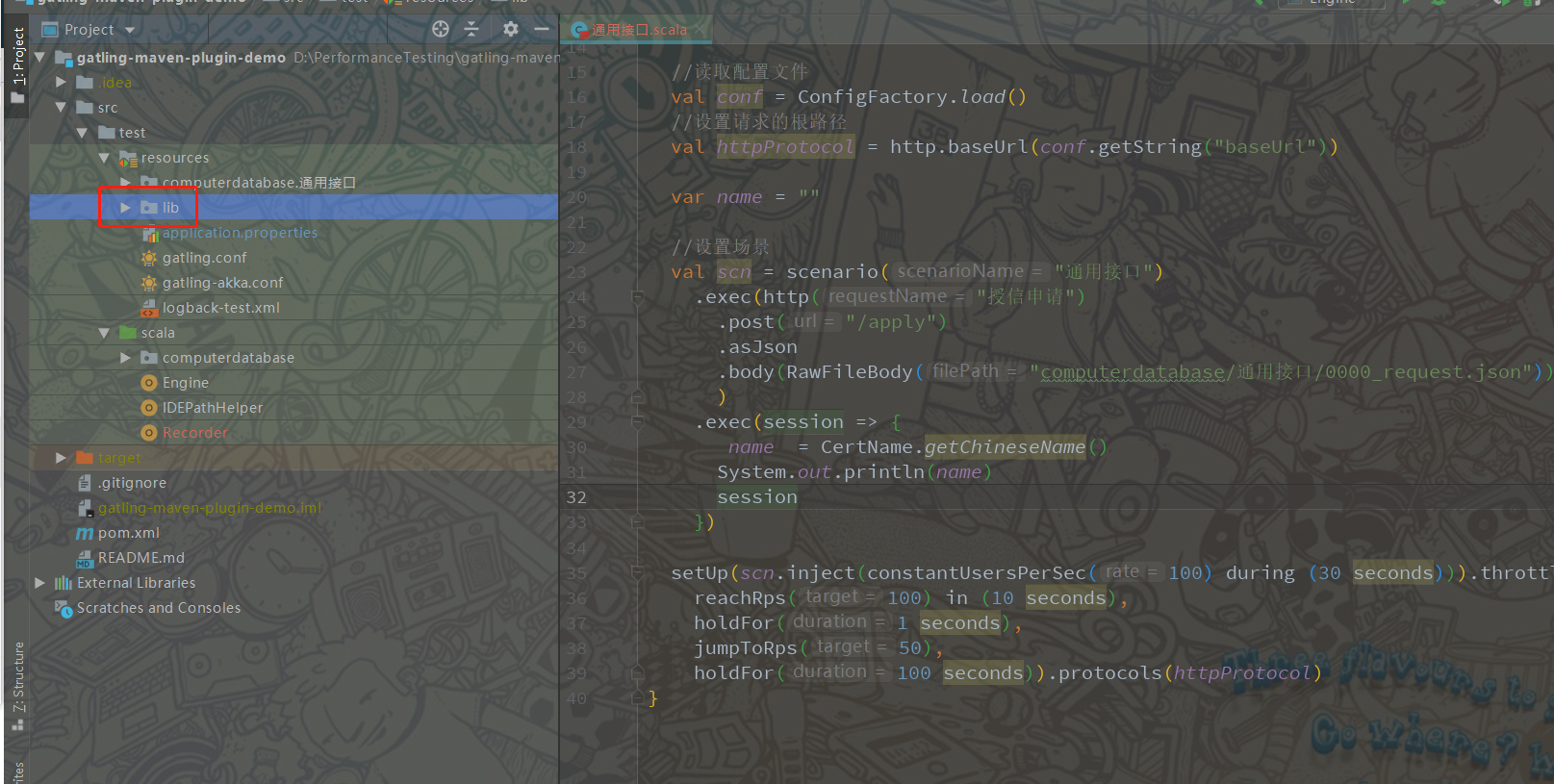
2、将自己生成的工具类jar包放到lib目录下
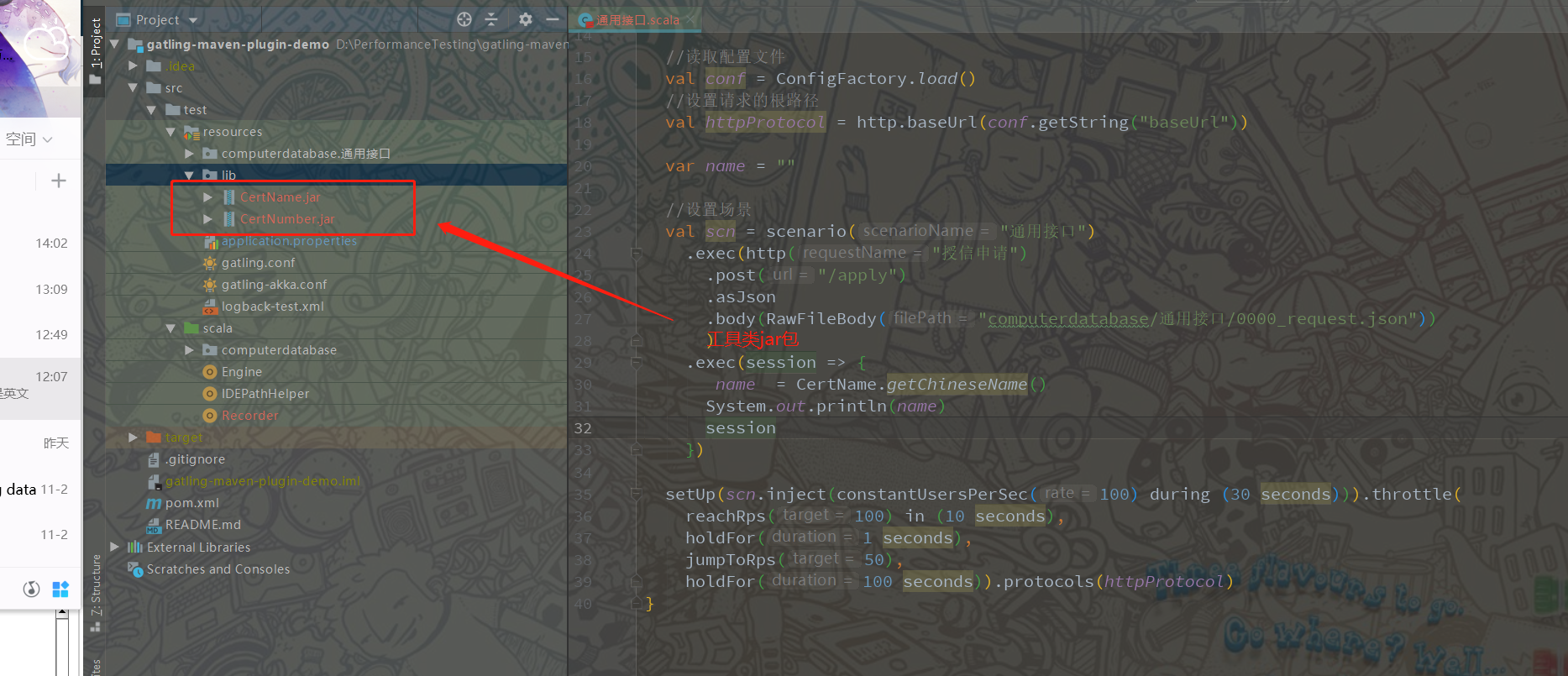
3、将jar包载入System Library库中
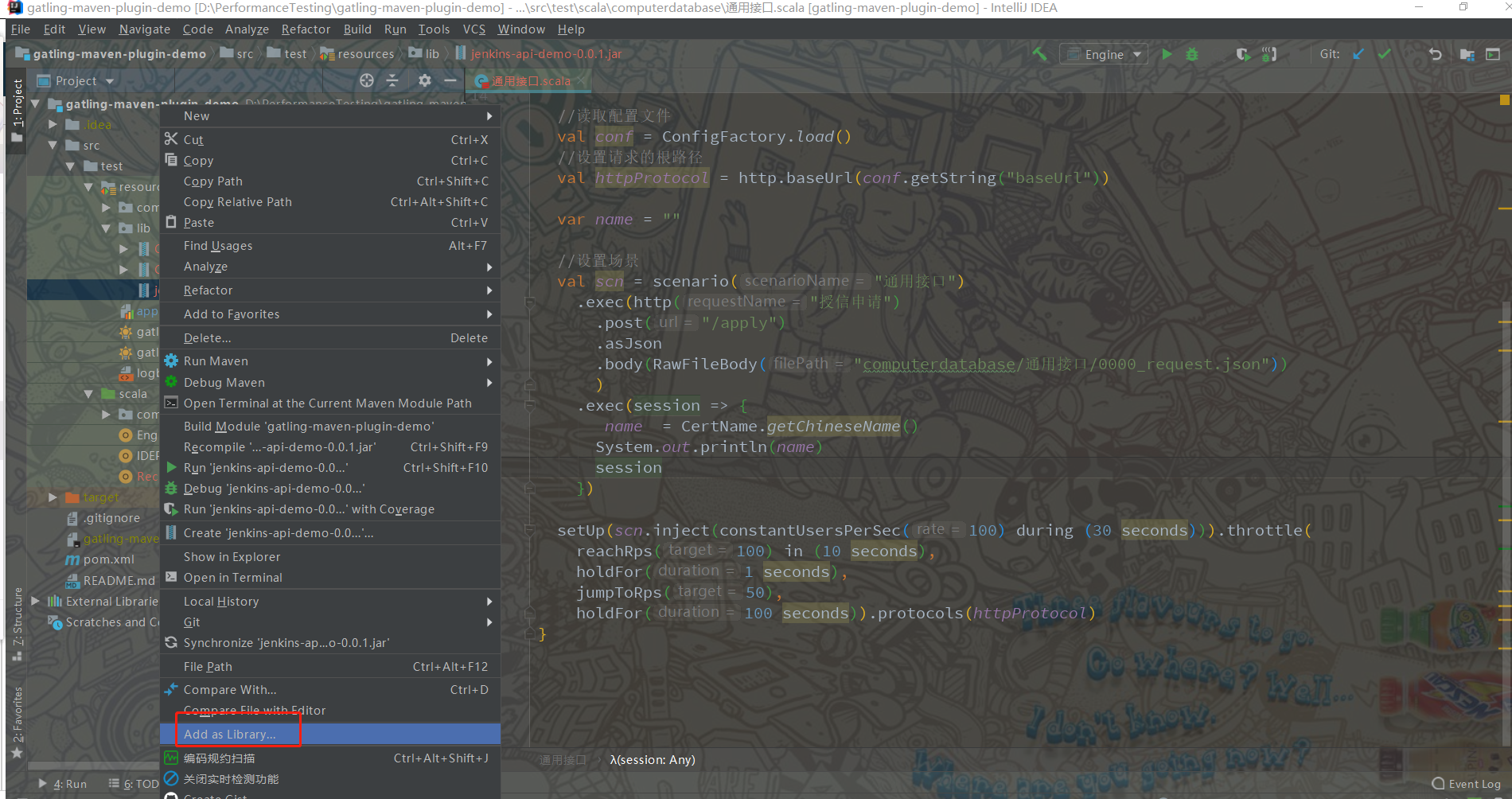
4、引入工具类
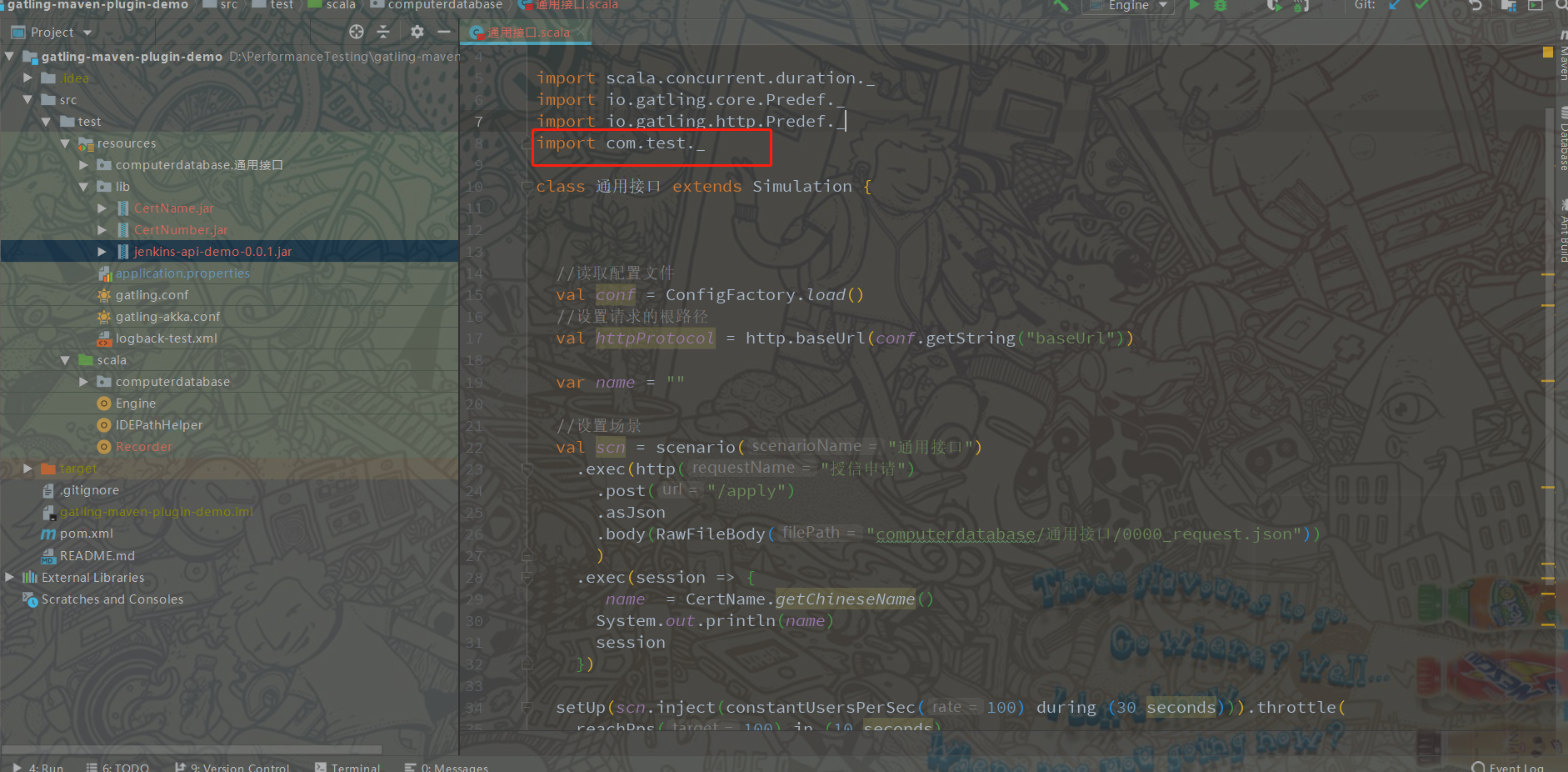
5、测试工具类 方法调用
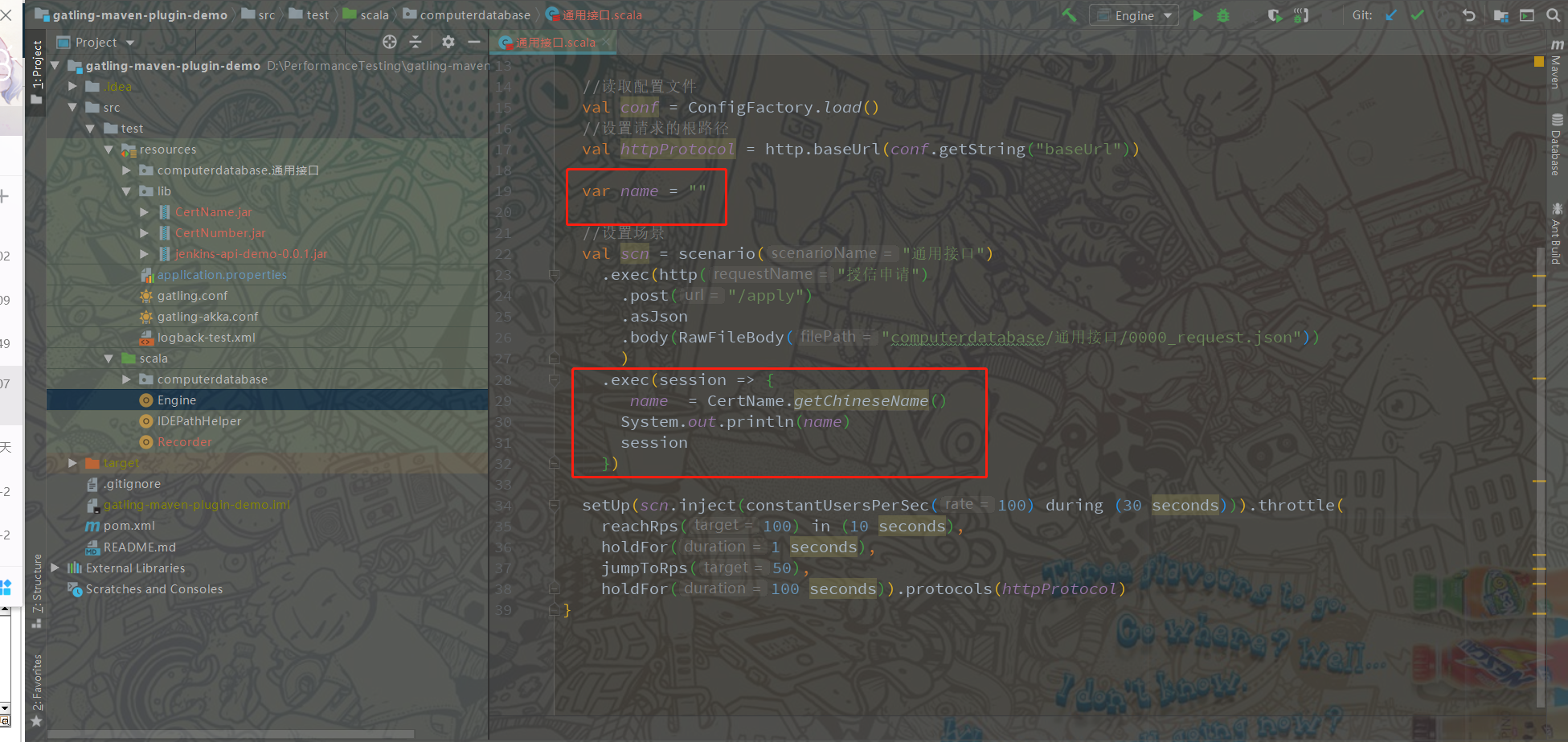
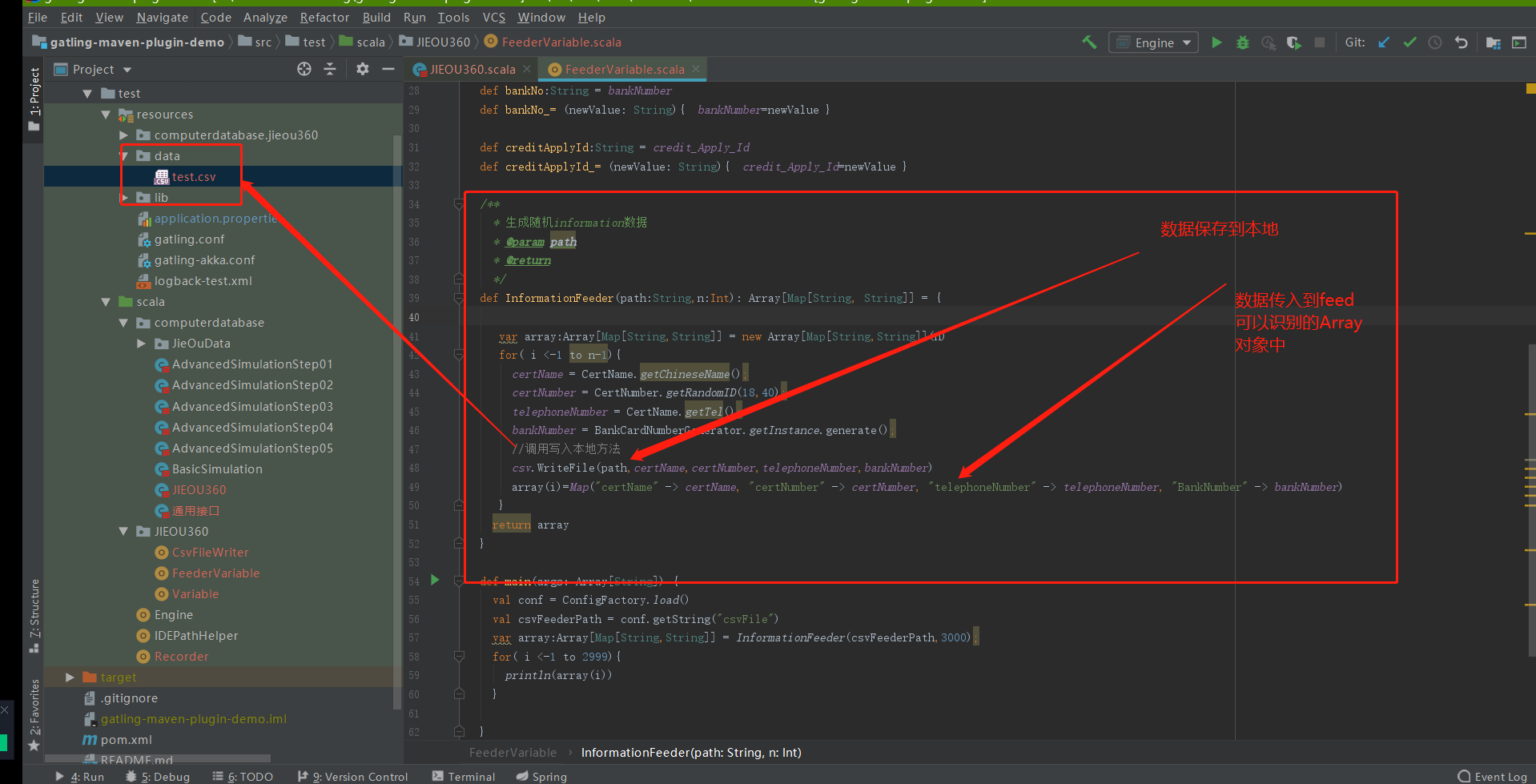
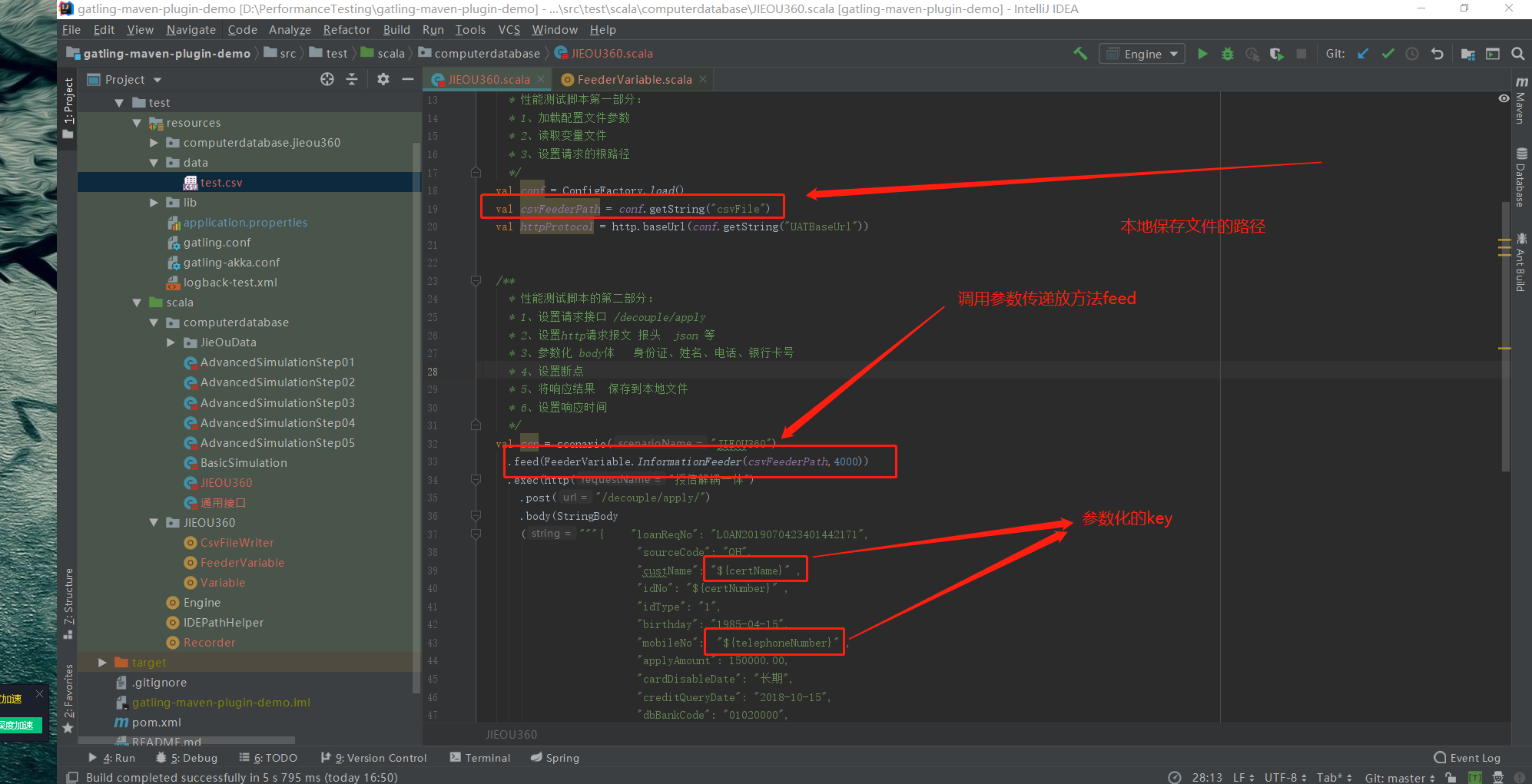
这里要注意的是Feeder这个函数,在加载参数的时候或者通过我这种方法,函数调用的外部jar包 都只会生效一次。因此要想灵活运用外部jar包工具类还需要在工程中再次加工,例如:我会调用jar包工具类一次性生成3000个数据,
然后在调用封装的方法即可。
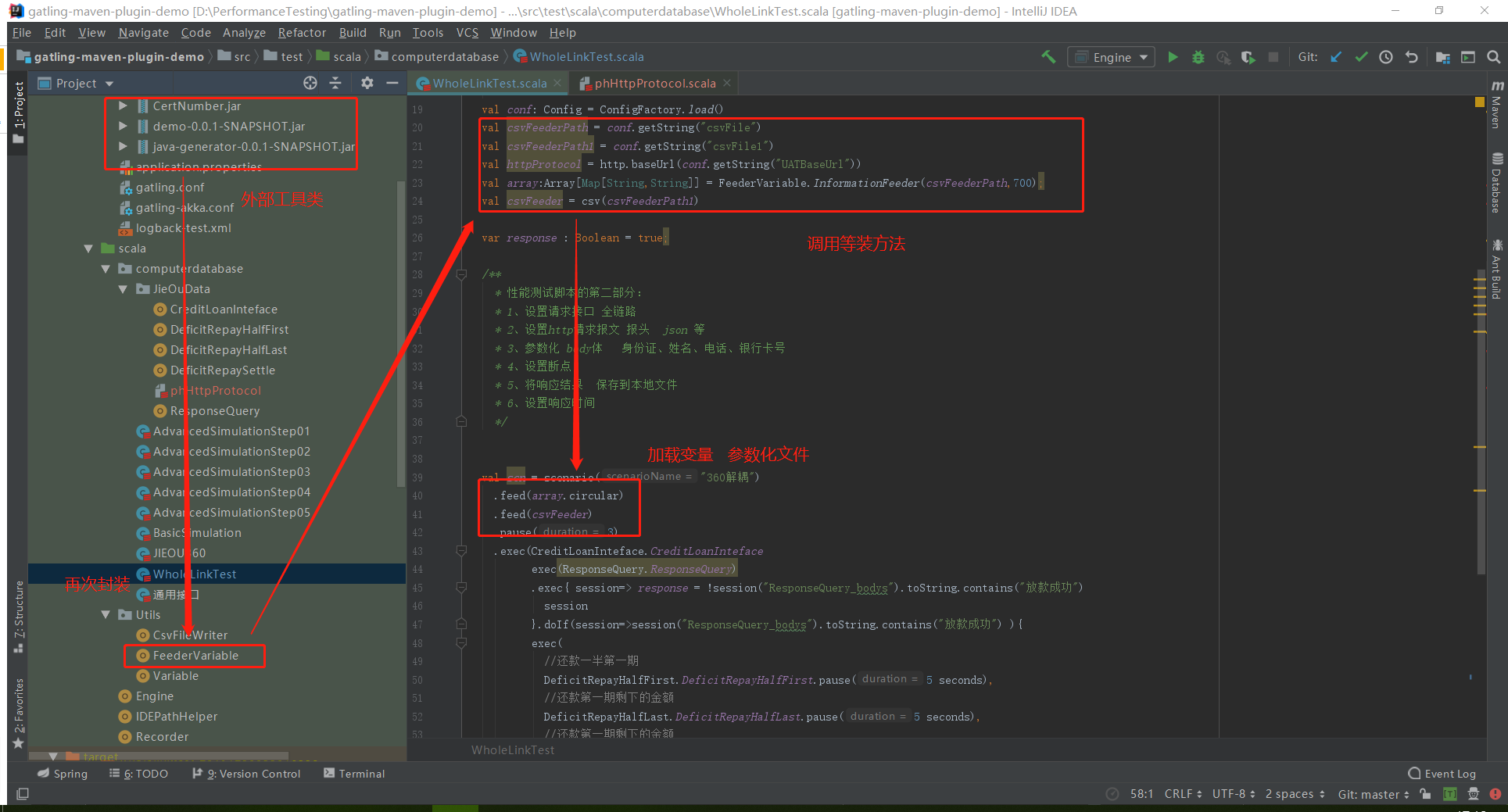
1、需要注意的是feed在整个请求过程中只加载一次传递参数的文件 也就是谁所有的传递的参数需要提前构造好 然后一次性加载到场景中
2、创建一个构造数据的脚本
实现两个功能:
随机生成的参数保存到本地
留作备用定位问题使用 随机生成的参数传递到Array中