本篇主要针对scrapy的基本运作进行一个展示说明,这里不再介绍scrapy的安装部署,如果有需要的朋友可以自行百度。
首先,我们要先创建一个爬虫项目:
1.创建scrapy爬虫步骤
我这里用了python3.5的解释器,所以我指定了解释器哦
python35 -m scrapy startproject project_name
这里执行完了之后会有提示要进入项目目录!然后执行下面操作
python35 -m scrapy genspider spider_name 域名
2.然后我们配置pycharm的启动脚本,方便直接从pycharm启动爬虫项目
我们在项目根目录创建一个名为begin的脚本

在begin脚本中写入如下命令:
from scrapy import cmdline import os cmdline.execute("scrapy crawl gj_crawler --nolog".split())
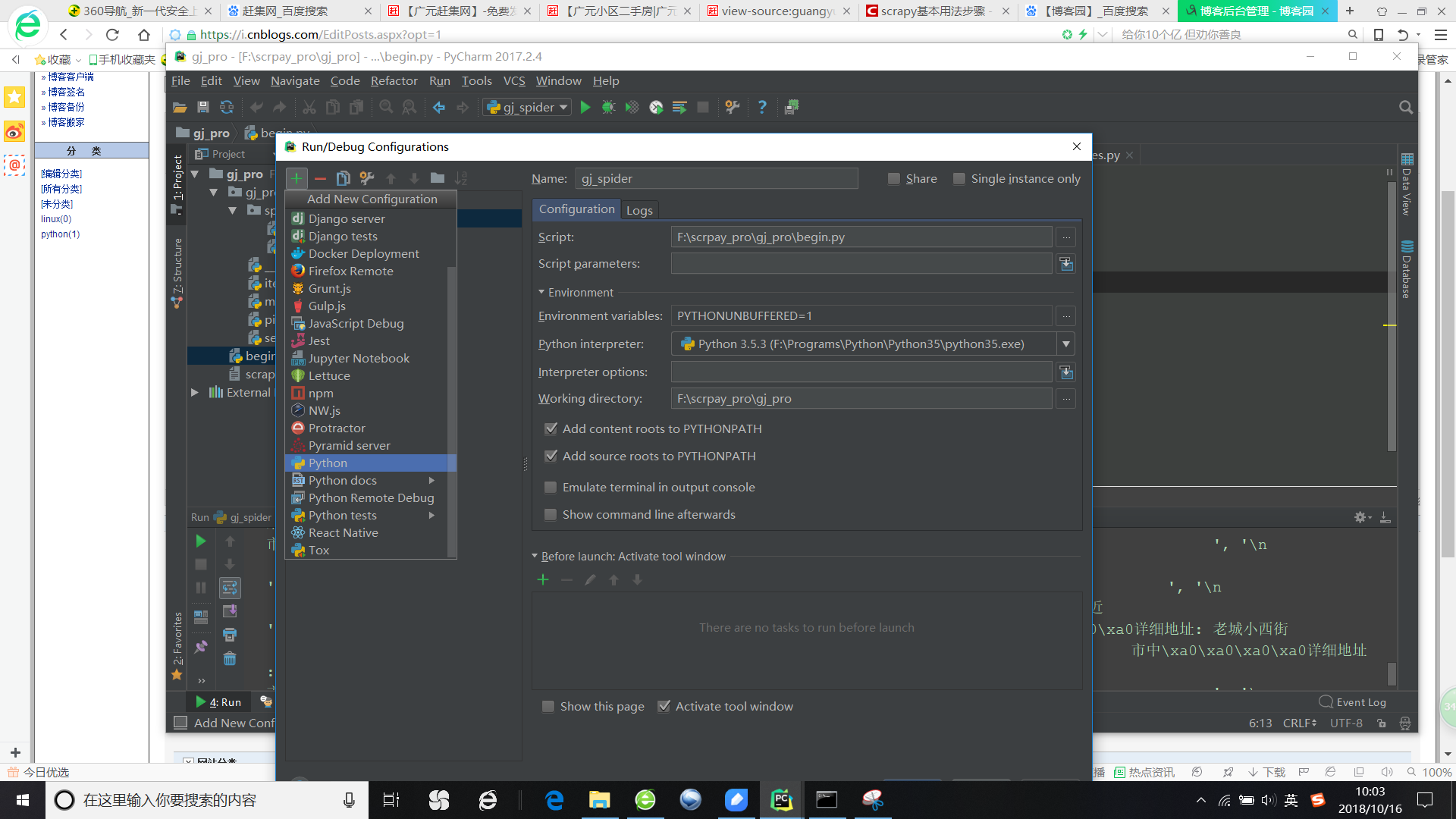
3.配置pycharm
点击如图位置编辑脚本启动路径,新建一个python执行程序,然后照下图设置路径即可
4.开始配置scrapy
首先,我们要知道一个scrapy爬虫常用的几个文件作用:
items.py该文件用于生产一个数据容器,用来存放爬取的数据(以字典形式)。
pipelines.py该文件用于处理爬取的数据,当然数据处理也可以不在这里使用,注意!要开启pipelines.py必需要在setting.py文件中开启
settings.py该文件用于设置scrapy的一些基本配置信息。
spiders/home_spider.py该文件生成与前面创建爬虫项目后,创建的爬虫文件,是运行爬虫的核心。
5.爬虫Xpath表达式介绍
正则表达式和Xpath表达式
Xpath是基于对应的标签来提取的,所以效率可观的角度而言优于正则表达式,但是注意了,不是说Xpath能够替代正则表达式哦!正则是很有用的,只不过xpath很方便罢了。
下面我们来看Xpath表达式
/ ------提取某个标签下的所有内容
text() ------- 提取标签所包含的文本内容
@ ---------- 提取标签属性的信息
// ---------- 寻找所有的标签
[@属性=值] ------ 定位标签
使用举例:
/html -----代表提取html标签内的所有内容
/html/head/title -----代表提取title下面的所有信息
//li ------ 代表提取所有的li标签
//li[@class='hidden-xs'] -------- 直接定位到满足条件的标签
//li[@class='hidden-xs']/a/@href ---------- 提取到class = hidden-cs的li标签下面的a标签的href的值
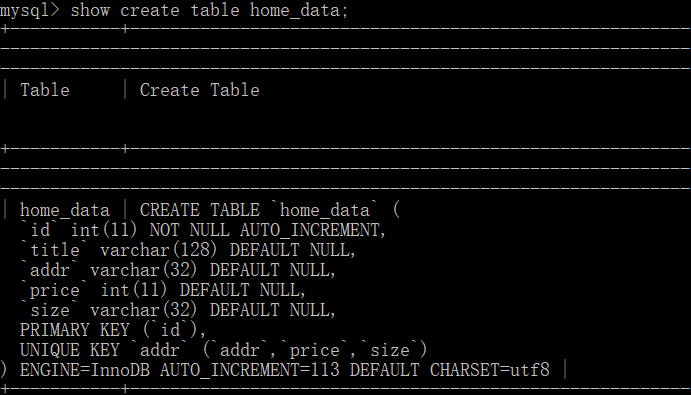
6.创建数据库存放数据
这里提一句,因为很多房价信息存在重复数据(各种炒房的.....),所以我们要过滤这些信息,为了保证数据的基本准确,需要设置一些自动或者多个字段为唯一字段或者联合唯一
7.核心代码详解
爬虫最主要的就是如何反爬,这里没有特别说明,因为58没有太多反扒机制,设置伪装头即可,然后我们就要解析网页那,无非就是那些div、h、a、span标签嘛,不明白的朋友可以任意打开一个页面查看下页面源码哦。
def parse(self, response): item = CrawlerHomeItem() item["title"] = response.xpath("//h2[@class='title']/a/text()").extract() item["addr"] = response.xpath("//p[@class='baseinfo']/span/a/text()").extract() item["price"] = response.xpath("//div[@class='price']/p[@class='unit']/text()").extract() item["size"] = response.xpath("//p[@class='baseinfo']/span").extract() yield item for i in range(2,71): url_redirect = r'https://guangyuan.58.com/ershoufang/pn%s/?PGTID=0d30000c-0261-56a9-4b14-ed8eeaf03e93&ClickID=1' % i yield scrapy.Request(url_redirect, callback=self.parse)
接下来就是附上实例代码了,主要我们在设置伪装浏览器头的时候,为了防爬,可以使用动态伪装,说白了就是设置一个列表,设置许多通用的请求头,然后每一次爬取都随机选择一个头。