https://www.cnblogs.com/lin3615/p/5684891.html
文章来自整理:http://blog.jobbole.com/94606/
其中Amoeba for MySQL也是实现读写分离
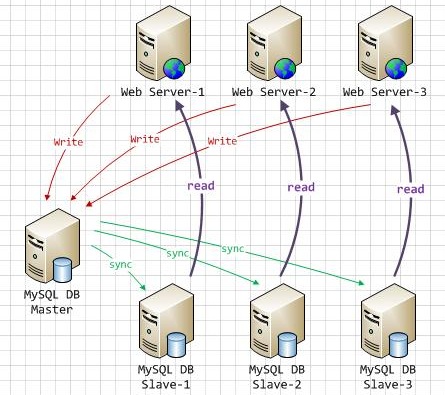
环境描述:
操作系统:CentOS6.5 32位
主服务器Master:192.168.179.146
从服务器Slave:192.168.179.147
调度服务器MySQL-Proxy:192.168.179.142
由于电脑配置不行,安装了三台虚拟机,就卡死了,只能将就一下,由于是一主
一从,所以,导致读写都在master上,有机会,再弄两台slave来测试
一.mysql主从复制,参考:http://www.cnblogs.com/lin3615/p/5679828.html
二、mysql-proxy实现读写分离
1、安装mysql-proxy
实现读写分离是有lua脚本实现的,现在mysql-proxy里面已经集成,无需再安装
下载:http://dev.mysql.com/downloads/mysql-proxy/ 一定要下载对应的版本
tar zxvf mysql-proxy-0.8.5-linux-glibc2.3-x86-32bit.tar.gz mv mysql-proxy-0.8.5-linux-glibc2.3-x86-32bit /usr/local/mysql-proxy
2、配置mysql-proxy,创建主配置文件

cd /usr/local/mysql-proxy mkdir lua #创建脚本存放目录 mkdir logs #创建日志目录 cp share/doc/mysql-proxy/rw-splitting.lua ./lua #复制读写分离配置文件 cp share/doc/mysql-proxy/admin-sql.lua ./lua #复制管理脚本 vi /etc/mysql-proxy.cnf #创建配置文件 [mysql-proxy] user=root #运行mysql-proxy用户 admin-username=lin3615 #主从mysql共有的用户 admin-password=123456 #用户的密码 proxy-address=192.168.179.142:4040 #mysql-proxy运行ip和端口,不加端口,默认4040 proxy-read-only-backend-addresses=192.168.179.147 #指定后端从slave读取数据 proxy-backend-addresses=192.168.179.146 #指定后端主master写入数据 proxy-lua-script=/usr/local/mysql-proxy/lua/rw-splitting.lua #指定读写分离配置文件位置 admin-lua-script=/usr/local/mysql-proxy/lua/admin-sql.lua #指定管理脚本 log-file=/usr/local/mysql-proxy/logs/mysql-proxy.log #日志位置 log-level=info #定义log日志级别,由高到低分别有(error|warning|info|message|debug) daemon=true #以守护进程方式运行 keepalive=true #mysql-proxy崩溃时,尝试重启 #保存退出! chmod 660 /etc/mysql-porxy.cnf
3、修改读写分离配置文件
vim /usr/local/mysql-proxy/lua/rw-splitting.lua
if not proxy.global.config.rwsplit then
proxy.global.config.rwsplit = {
min_idle_connections = 1, #默认超过4个连接数时,才开始读写分离,改为1
max_idle_connections = 1, #默认8,改为1
is_debug = false
}
end
4、启动mysql-proxy
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/etc/mysql-proxy.cnf netstat -tupln | grep 4000 #已经启动 killall -9 mysql-proxy #关闭mysql-proxy使用
5、测试读写分离
(1).在主服务器创建proxy用户用于mysql-proxy使用,从服务器也会同步这个操作
mysql> grant all on *.* to 'lin3615'@'192.168.179.142' identified by '123456';
(2).使用客户端连接mysql-proxy
mysql -u lin3615 -h 192.168.179.142 -P 4040 -p123456
接下来就按基本的 curd执行即可,由于只有一台slave,测试时,每次读写都是从master,电脑性能无法开四台虚拟机,所以有机会,再测试多台 slave,看下是否OK
读写分离,延迟是个大问题
在slave服务器上执行 show slave status,
可以看到很多同步的参数,要注意的参数有:
Master_Log_File:slave中的I/O线程当前正在读取的master服务器二进制式日志文件名.
Read_Master_Log_Pos:在当前的 master服务器二进制日志中,slave中的I/O线程已经读取的位置
Relay_Log_File:SQL线程当前正在读取与执行中继日志文件的名称
Relay_Log_Pos:在当前的中继日志中,SQL线程已读取和执行的位置
Relay_Master_Log_File:由SQL线程执行的包含多数近期事件的master二进制日志文件的名称
Slave_IO_Running:I/O线程是否被启动并成功连接到master
Slave_SQL_Running:SQL线程是否被启动
Seconds_Behind_Master:slave服务器SQL线程和从服务器I/O线程之间的差距,单位为秒计
slave同步延迟情况出现:
1.Seconds_Behind_Master不为了,这个值可能会很大
2.Relay_Master_Log_File和Master_Log_File显示bin-log的编号相差很大,说明bin-log在slave上没有及时同步,所以近期执行的 bin-log和当前I/O线程所读的 bin-log相差很大
3.mysql的 slave数据库目录下存在大量的 mysql-relay-log日志,该日志同步完成之后就会被系统自动删除,存在大量日志,说明主从同步延迟很厉害
mysql主从同步延迟原理
mysql主从同步原理
主库针对读写操作,顺序写 binlog,从库单线程去主库读"写操作的binlog",从库取到 binlog在本地原样执行(随机写),来保证主从数据逻辑上一致.
mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生 binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率比较高,下一步问题来了,slave的 slave_sql_running线程将主库的 DDL和DML操作在 slave实施。DML,DDL的IO操作是随即的,不能顺序的,成本高很多,还有可能slave上的其他查询产生 lock,由于 slave_sql_running也是单线程的,所以 一个 DDL卡住了,需求需求执行一段时间,那么所有之后的DDL会等待这个 DDL执行完才会继续执行,这就导致了延迟.由于master可以并发,Slave_sql_running线程却不可以,所以主库执行 DDL需求一段时间,在slave执行相同的DDL时,就产生了延迟.
主从同步延迟产生原因
当主库的TPS并发较高时,产生的DDL数量超过Slave一个 sql线程所能承受的范围,那么延迟就产生了,当然还有就是可能与 slave的大型 query语句产生了锁等待
首要原因:数据库在业务上读写压力太大,CPU计算负荷大,网卡负荷大,硬盘随机IO太高
次要原因:读写 binlog带来的性能影响,网络传输延迟
主从同步延迟解决方案
架构方面
1.业务的持久化层的实现采用分库架构,mysql服务可平行扩展分散压力
2.单个库读写分离,一主多从,主写从读,分散压力。
3.服务的基础架构在业务和mysql之间加放 cache层
4.不同业务的mysql放在不同的机器
5.使用比主加更了的硬件设备作slave
反正就是mysql压力变小,延迟自然会变小
硬件方面:
采用好的服务器
mysql主从同步加速
1、sync_binlog在slave端设置为0
2、–logs-slave-updates 从服务器从主服务器接收到的更新不记入它的二进制日志。
3、直接禁用slave端的binlog
4、slave端,如果使用的存储引擎是innodb,innodb_flush_log_at_trx_commit =2
从文件系统本身属性角度优化
master端
修改linux、Unix文件系统中文件的etime属性, 由于每当读文件时OS都会将读取操作发生的时间回写到磁盘上,对于读操作频繁的数据库文件来说这是没必要的,只会增加磁盘系统的负担影响I/O性能。可以通过设置文件系统的mount属性,组织操作系统写atime信息,在linux上的操作为:
打开/etc/fstab,加上noatime参数
/dev/sdb1 /data reiserfs noatime 1 2
然后重新mount文件系统
#mount -oremount /data
主库是写,对数据安全性较高,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置是需要的
而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog也可以设置为0来提高sql的执行效率
1、sync_binlog=1 o
MySQL提供一个sync_binlog参数来控制数据库的binlog刷到磁盘上去。
默认,sync_binlog=0,表示MySQL不控制binlog的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
如果sync_binlog>0,表示每sync_binlog次事务提交,MySQL调用文件系统的刷新操作将缓存刷下去。最安全的就是sync_binlog=1了,表示每次事务提交,MySQL都会把binlog刷下去,是最安全但是性能损耗最大的设置。这样的话,在数据库所在的主机操作系统损坏或者突然掉电的情况下,系统才有可能丢失1个事务的数据。
但是binlog虽然是顺序IO,但是设置sync_binlog=1,多个事务同时提交,同样很大的影响MySQL和IO性能。
虽然可以通过group commit的补丁缓解,但是刷新的频率过高对IO的影响也非常大。对于高并发事务的系统来说,
“sync_binlog”设置为0和设置为1的系统写入性能差距可能高达5倍甚至更多。
所以很多MySQL DBA设置的sync_binlog并不是最安全的1,而是2或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。
默认情况下,并不是每次写入时都将binlog与硬盘同步。因此如果操作系统或机器(不仅仅是MySQL服务器)崩溃,有可能binlog中最后的语句丢失了。要想防止这种情况,你可以使用sync_binlog全局变量(1是最安全的值,但也是最慢的),使binlog在每N次binlog写入后与硬盘同步。即使sync_binlog设置为1,出现崩溃时,也有可能表内容和binlog内容之间存在不一致性。
2、innodb_flush_log_at_trx_commit (这个很管用)
抱怨Innodb比MyISAM慢 100倍?那么你大概是忘了调整这个值。默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电池供电缓存(Battery backed up cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。
日志仍然会每秒flush到硬 盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统 挂了时才可能丢数据。
3、ls(1) 命令可用来列出文件的 atime、ctime 和 mtime。
atime 文件的access time 在读取文件或者执行文件时更改的
ctime 文件的create time 在写入文件,更改所有者,权限或链接设置时随inode的内容更改而更改
mtime 文件的modified time 在写入文件时随文件内容的更改而更改
ls -lc filename 列出文件的 ctime
ls -lu filename 列出文件的 atime
ls -l filename 列出文件的 mtime
stat filename 列出atime,mtime,ctime
atime不一定在访问文件之后被修改
因为:使用ext3文件系统的时候,如果在mount的时候使用了noatime参数那么就不会更新atime信息。
这三个time stamp都放在 inode 中.如果mtime,atime 修改,inode 就一定会改, 既然 inode 改了,那ctime也就跟着改了.
之所以在 mount option 中使用 noatime, 就是不想file system 做太多的修改, 而改善读取效能
4.进行分库分表处理,这样减少数据量的复制同步操作