- 又称在线联机日志/在线归档重做日志
- 特点
- 记录数据库的变化
- 用于数据块的恢复
- 以日志组的方式进行管理,至少有两组且每组至少有两个成员
- 一般情况下和数据文件放在不同的磁盘中
- 在线重做日志是循环覆盖写的
- 数据字典
- v$log;
- v$logfile
- v$archived_log
- 日志组
- 日志组切换
- 在归档模式下:执行日志切换命令,LGWR进程将打开下一个日志组进行记录,并通知ARCn进程将前一个日志组的日志进行归档保存。
- 在非归档模式下:执行日志切换命令,LGWR进程将打开下一个日志组进行记录,对于历史日志组的记录将覆盖。
- 日志组成员 member---每组的日志成员,内容都是完全一致的
- 查看日志组及成员
1 SQL> select a.group#,a.members,a.status,a.bytes/1024/1024 M,b.member from v$log a,v$logfile b where a.group#=b.group# order by 1;
- 添加日志组
1 SQL> alter database add logfile group 4('/u01/app/oracle/oradata/PROD1/redo04.log','/u01/app/oracle/oradata/PROD1/redo04a.log') size 200M reuse;
- 添加日志组成员
1 SQL> alter database add logfile member '/u01/app/oracle/oradata/PROD1/redo04b.log' to group 4; ----单独添加日志组成员时,状态为INVALID,手工切换日志进行同步组成员 2 SQL> alter system switch logfile;
- 日志组状态
- UNUSED:新创建的日志组状态,一旦被使用,就不存在这个状态了
- CURRENT:当前数据库正在使用的日志组,不允许被覆盖
- ACTIVE:数据缓冲区里面的数据还没有刷入到磁盘,不允许被覆盖-----当发出alter system checkpoint;命令后,会从ACTIVE变成INACTIVE
- INACTIVE:非活动状态,可以被覆盖
- 删除日志组
1 SQL> alter database drop logfile group 1(2,3,4,5); ------删除的是控制文件里的元数据,但是物理文件仍然是存在的
- 清除日志(不是删除日志,而是重建日志)
1 SQL> alter database clear logfile group 1;------隐含的条件是日志已归档 SQL> alter database clear unarchived logfile group 1;-------未归档的日志清除时,使用此命令
- 备份、还原、恢复的概念
- 备份:backup
- 还原:restore 把原来备份的东西重新拿过来,这个过程(动作)叫还原。
- 恢复:recover 利用重做日志把数据库恢复到指定的时间点(完全恢复、不完全恢复)
- 在线日志组恢复
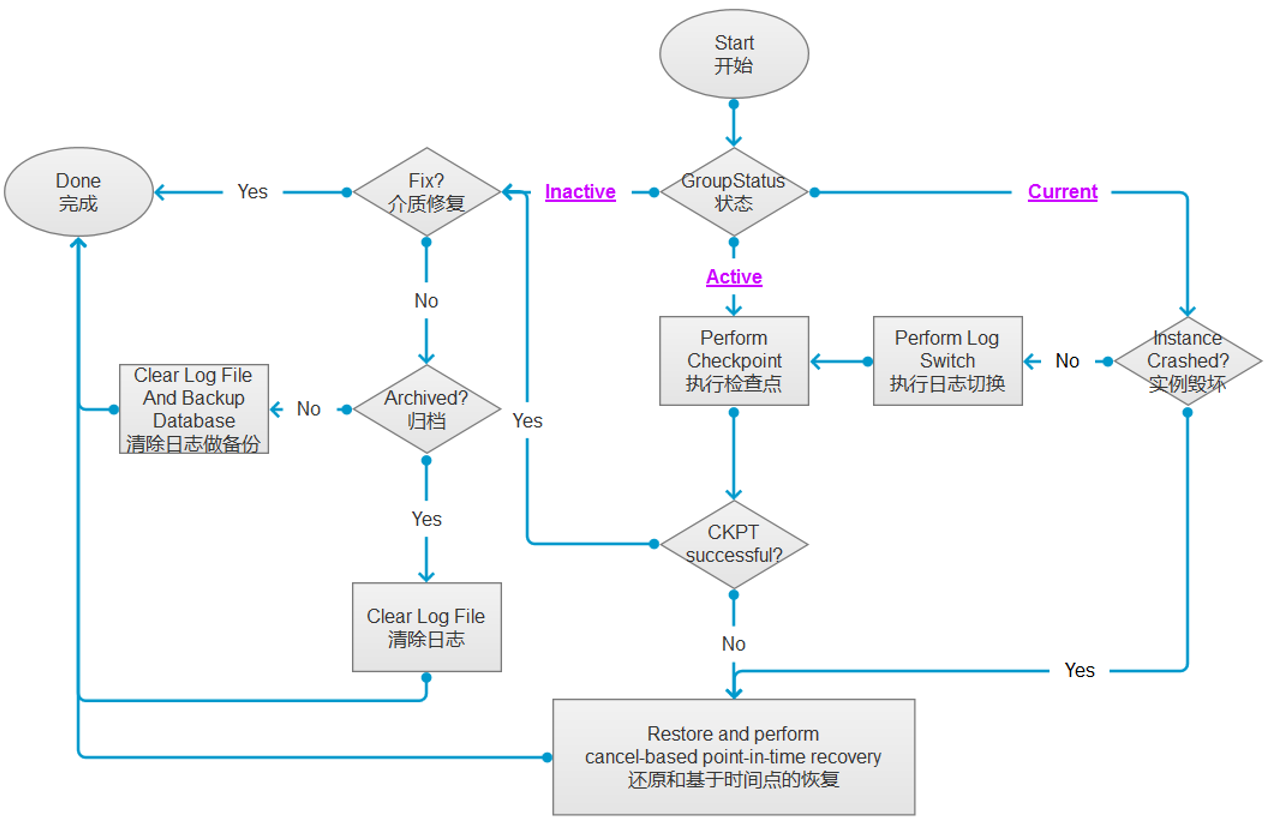
- CURRENT日志组丢失
- 非归档模式
- 如果Current日志组丢失,只能借助备份文件进行完全还原,无法进行实例恢复,即将丢失一部分数据。 非归档模式下,不管实例有没有崩溃,都只能进行完全还原。
- 步骤
- 关闭数据库;
- 将备份文件覆盖现有文件;
- 开启数据库;
- 归档模式
- 实例没有崩溃
- 执行切换日志组----SQL> alter system switch logfile;
- 执行完全检查点----SQL> alter system checkpoint;
- 强制清除日志组----SQL> alter database clear unarchived logfile group 1;----在归档模式下,清除日志组命令隐含着要将当前的日志组归档,但当前日志组所对应的物理文件已被删除,无法进行归档,所以报错。因此需用UNARCHIVED进行强制清除。
- 实例崩溃
- 实例崩溃必须通过还原和基于cancel-based时间点恢复来处理
- 情况一:还原了所有的数据文件、控制文件和日志文件。因为是一致性的,所以可以直接startup启动
- 情况二:还原了所有的数据文件、控制文件 ----SQL> startup mount; SQL> recover database until cancel using backup controlfile
- 情况三:仅还原所有的数据文件----SQL> startup mount; SQL> recover database until cancel;
- 情况一:还原了所有的数据文件、控制文件和日志文件。因为是一致性的,所以可以直接startup启动
- 实例崩溃必须通过还原和基于cancel-based时间点恢复来处理