1、建立slot和jedisPool的对应关系
2、每一个master Node会建立一个jedisPool
3、扩展和伸缩节点特别容易
4、hash一致性算法
5、gossip算法(最终一致性)
Redis持久化:
RDB持久化需要fork子进程,先写临时文件,再替换掉源文件(save配置)
AOF持久化就是redis主进程做的,只是AOF会写入AOF缓冲区,这个操作是非常快的;然后就是每隔1s把AOF缓冲区中的数据刷新到磁盘中去。追加方式
AOF重写:根据内存数据重新生成AOF文件,需要fork子进程,至少配置5G
如果两个机制都开启,优先使用AOF
集群中必须开启RDB
缓和持久化:
Redis优点:
基于内存
单线程
IO多路复用
Redis删除策略:
被动删除
定时删除
定期删除
主动删除
淘汰策略
Redis逐出算法:
LRU策略:最近最少使用
TTL策略:最近使用系数最少的
即将要过期的数据淘汰选择
随机淘汰策略
缓冲的三大问题:
缓冲与数据库的一致性问题:1、双删策略;2、串行化(队列) 3、分布式读写锁
redis的位运算
布隆过滤器
主从复制原理:rbd和aof命令缓冲区
集群中的master只能存储自己slot的那部分资源,否则的话会抛出maved error的错误,并告诉客户端应该到那个master上去操作
hash tag
三级缓冲:nginx缓冲+redis缓冲+jvm缓冲
redLock解决了什么问题,相比其它分布式锁的优点
redis 的MurMurHash算法

CRC16(KEY)&16383

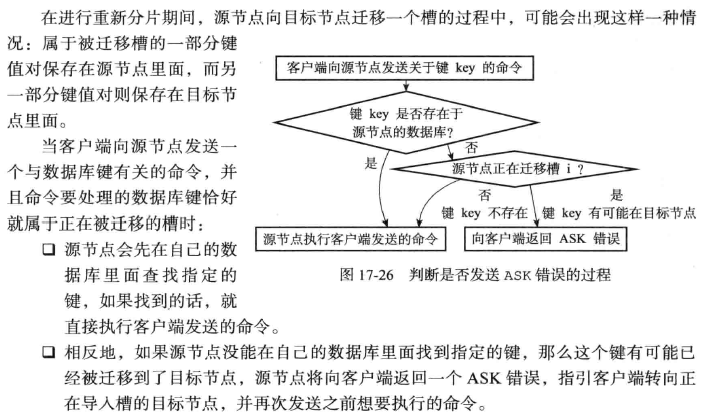
ASK错误
redis的持久化RDB机制:
1、redis是需要fork出子进程来保存RDB文件的,但是其实这个过程也是会有时间很短的一段阻塞,就是fork期间会进行阻塞,然后这段时间也会应用Linux的写时复制机制进行操作,所以这段时间写请求的话会性能慢一些的。
2、AOF重写机制是通过遍历读取数据库的健值来实现的,
注意AOF缓冲区和AOF重写缓冲区的区别
AOF重写缓冲区可以保证AOF子进程在重写AOF文件期间,主进程不会有任何的阻塞
3、集群复制部分同步机制实现(复制积压缓冲区的实现)

redis的数据结构的底层原理实现:
redis的对象结构:

redisObject的基础属性是这三个,还有其他的属性:
(1)、引用计数值
(2)、lru记录了最后一次被命令访问的时间
具体的类型如下:

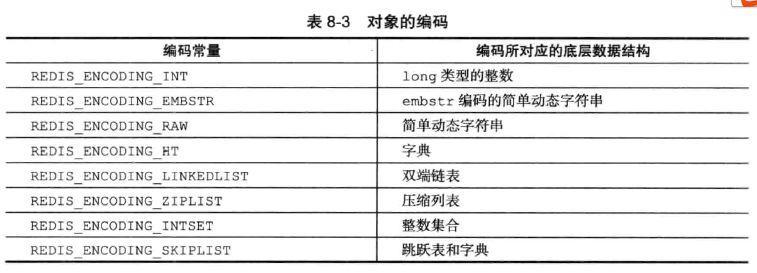
具体的编码如下:
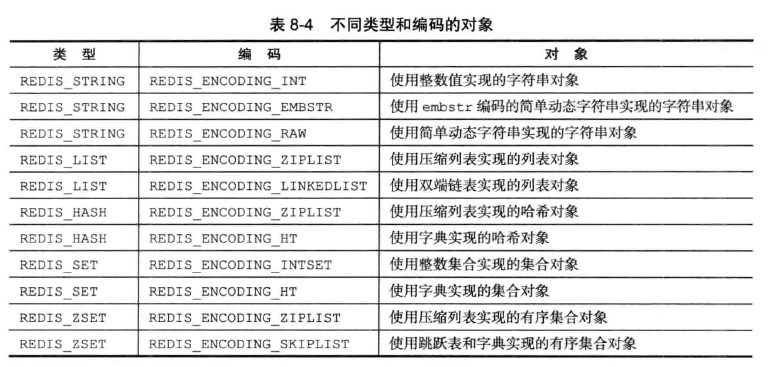
具体的类型和编码对应关系如下:
1、字符串的底层实现原理
字符串对象的编码可以是int,raw和embstr
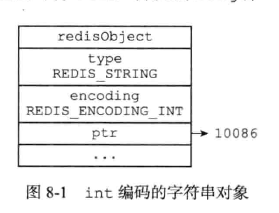
(1)、int编码的字符串对象
(2)、raw编码的字符串对象
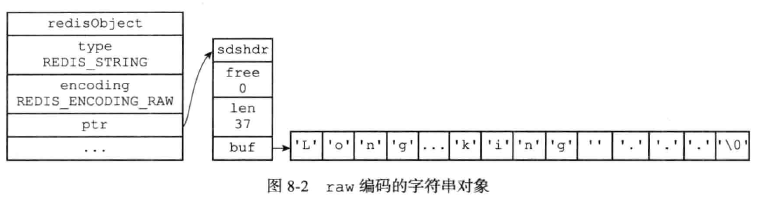
(3)、embstr编码的字符串对象
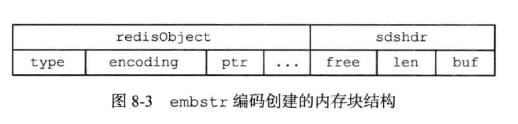
2、列表健的底层实现原理
列表对象的编码可以是ziplist或者linkedlist
(1)、ziplist的编码实现:
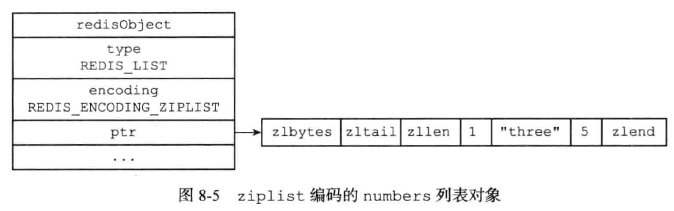
具体的压缩列表结构:
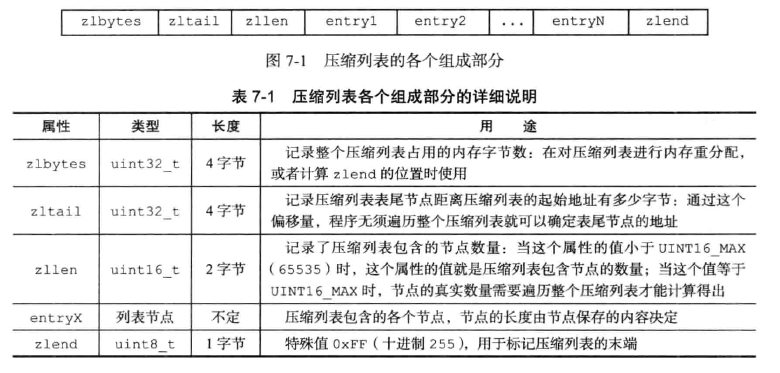
具体的元素结构:

注意压缩列表的连锁更新
(2)、linkedlist的编码实现
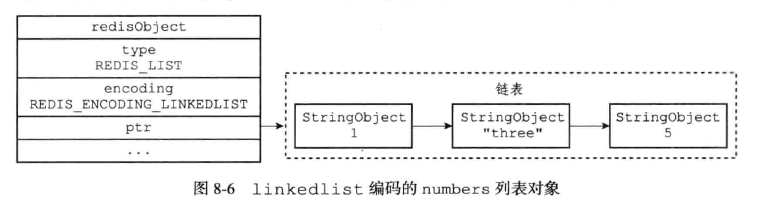
具体的链表结构:
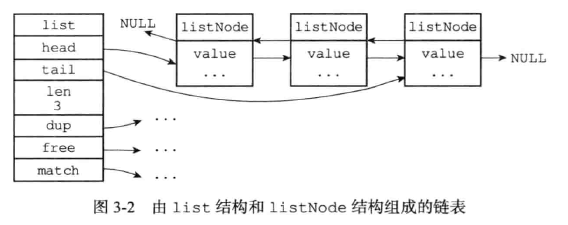
具体的元素的实现:

3、哈希健的底层原理实现
哈希对象的编码实现ziplist和hashtable
(1)、ziplist 的实现

具体的存储方式:

(2)、hashtable的编码实现
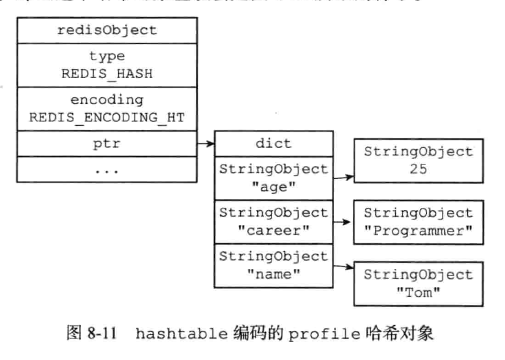
具体的对象:
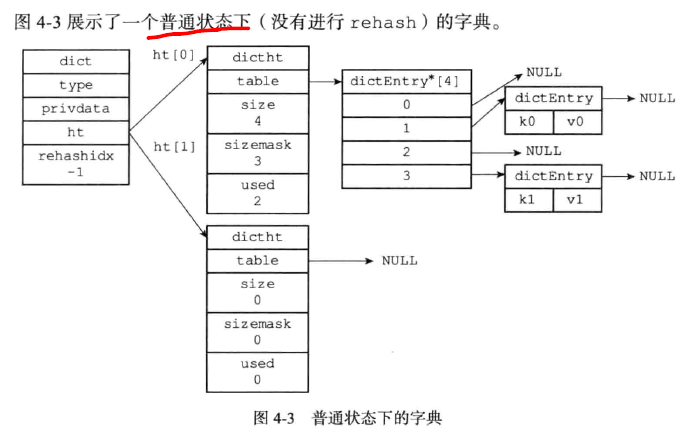
①、Murmurhash算法
②、使用链式地址法解决hash冲突问题(单向链表,并且使用链表的头插法添加元素)
③、rehash:渐进式hash,注意是为了防止在rehash的过程中阻碍正常的服务流程
渐进式hash的过程以及注意的点(redisidx变量的值的变化)

4、有续集合健的底层实现原理
有序集合的编码方式可以是ziplist和skiplist
(1)、ziplist的编码实现
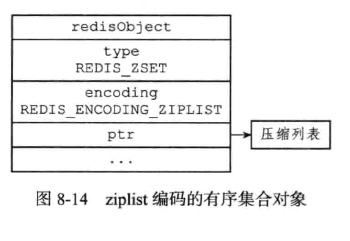
具体的元素存储结构:

(2)、skiplist的编码实现
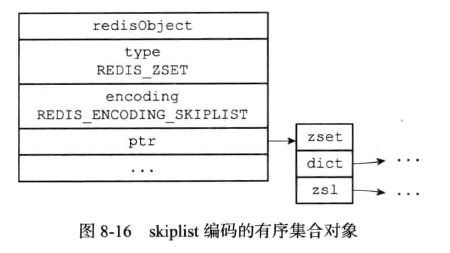
具体的元素实现:

具提的元素结构:
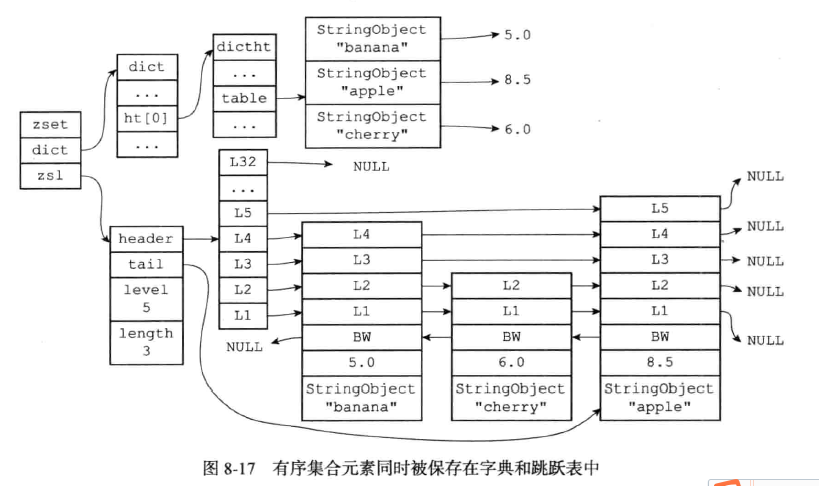
跳表的结构如下:
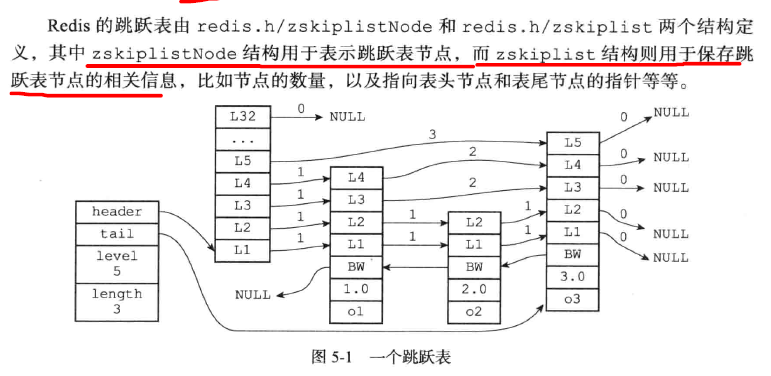
具体的元素结构:

5、普通集合健的底层实现原理
集合对象的编码可以是intset或者是hashtable
(1)、intset编码的实现
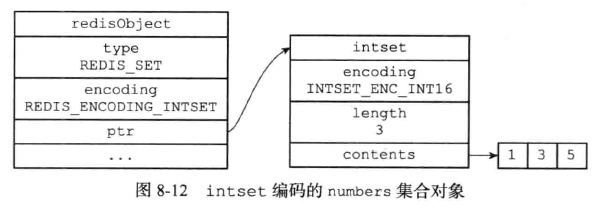
具体的元素结构:

注意一点就是整数集合健的升级
(2)、hashtable编码的实现(key为字符串,值为null的结构)
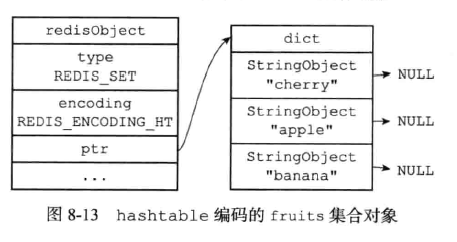
Redis数据库的底层实现
1、redis删除数据库过期键的策略
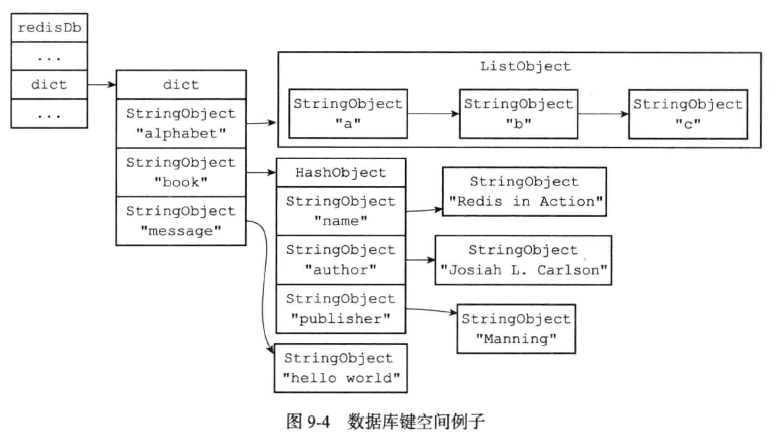
存储有过期时间的Redis数据库:
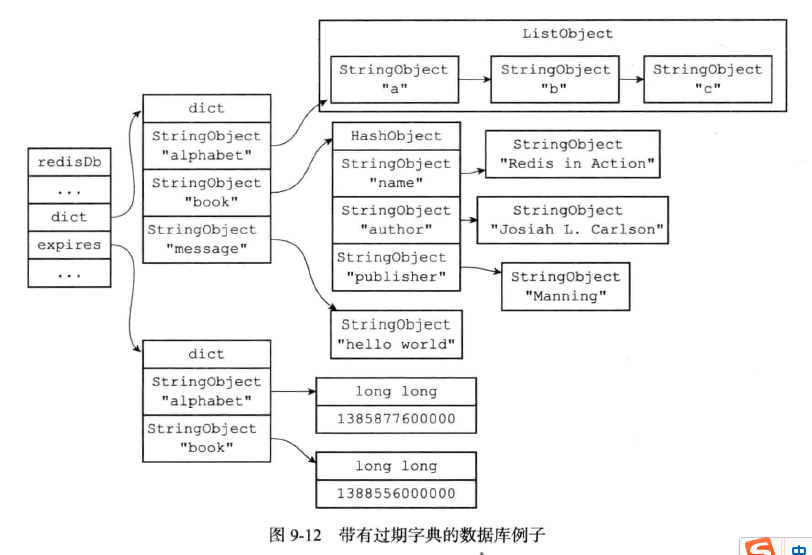
主要是分为两种策略:惰性删除策略和定期删除策略