1. 数据本地化的级别:
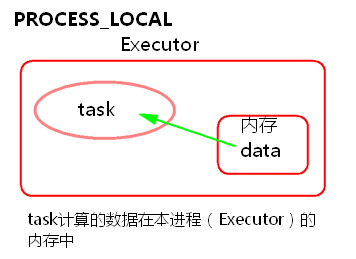
① PROCESS_LOCAL
task要计算的数据在本进程(Executor)的内存中。
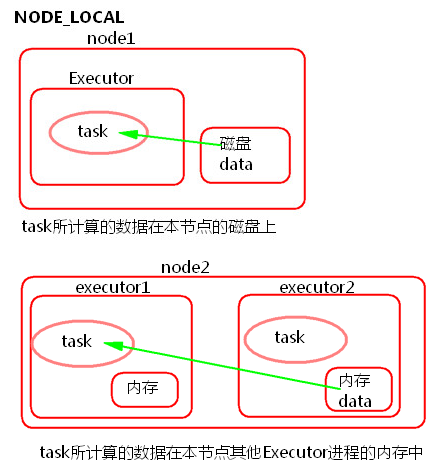
② NODE_LOCAL
a) task所计算的数据在本节点所在的磁盘上。
b) task所计算的数据在本节点其他Executor进程的内存中。
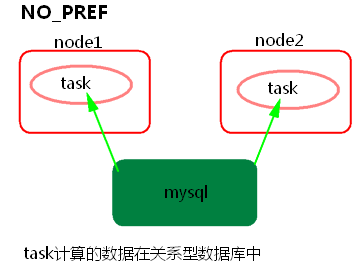
③ NO_PREF
task所计算的数据在关系型数据库中,如mysql。
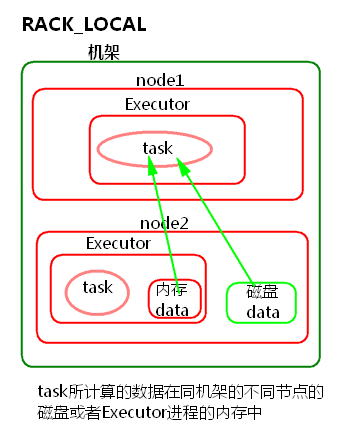
④ RACK_LOCAL
task所计算的数据在同机架的不同节点的磁盘或者Executor进程的内存中
⑤ ANY
跨机架。
2. Spark数据本地化调优:
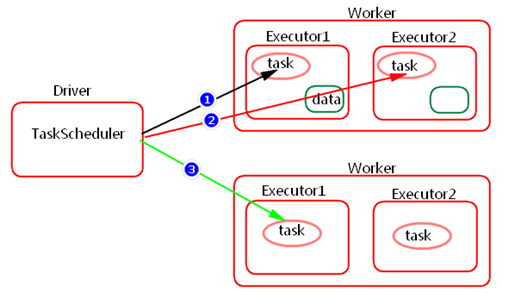
Spark中任务调度时,TaskScheduler在分发之前需要依据数据的位置来分发,最好将task分发到数据所在的节点上,如果TaskScheduler分发的task在默认3s依然无法执行的话,TaskScheduler会重新发送这个task到相同的Executor中去执行,会重试5次,如果依然无法执行,那么TaskScheduler会降低一级数据本地化的级别再次发送task。
如上图中,会先尝试1,PROCESS_LOCAL数据本地化级别,如果重试5次每次等待3s,会默认这个Executor计算资源满了,那么会降低一级数据本地化级别到2,NODE_LOCAL,如果还是重试5次每次等待3s还是失败,那么还是会降低一级数据本地化级别到3,RACK_LOCAL。这样数据就会有网络传输,降低了执行效率。
① 如何提高数据本地化的级别?
可以增加每次发送task的等待时间(默认都是3s),将3s倍数调大, 结合WEBUI来调节:
• spark.locality.wait
• spark.locality.wait.process
• spark.locality.wait.node
• spark.locality.wait.rack
注意:等待时间不能调大很大,调整数据本地化的级别不要本末倒置,虽然每一个task的本地化级别是最高了,但整个Application的执行时间反而加长。
② 如何查看数据本地化的级别?
通过日志或者WEBUI