ApacheFlink起源于Stratosphere项目,Stratosphere是在2010~2014年由3所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目,2014年4月Stratosphere的代码被复制并捐赠给了Apache软件基金会,参加这个孵化项目的初始成员是Stratosphere系统的核心开发人员,2014年12月,Flink一跃成为Apache软件基金会的顶级项目。

在德语中,Flink一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为logo,这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,而Flink的松鼠logo拥有可爱的尾巴,尾巴的颜色与Apache软件基金会的logo颜色相呼应,也就是说,这是一只Apache风格的松鼠。
图 Flink Logo


Flink虽然诞生的早(2010年),但是其实是起大早赶晚集,直到2015年才开始突然爆发热度。
在Flink被apache提升为顶级项目之后,阿里实时计算团队决定在阿里内部建立一个 Flink 分支 Blink,并对 Flink 进行大量的修改和完善,让其适应阿里巴巴这种超大规模的业务场景。
Blink由2016年上线,服务于阿里集团内部搜索、推荐、广告和蚂蚁等大量核心实时业务。与2019年1月Blink正式开源,目前阿里70%的技术部门都有使用该版本。
Blink比起Flink的优势就是对SQL语法的更完善的支持以及执行SQL的性能提升。
2 Flink的重要特点
2.1 事件驱动型(Event-driven)
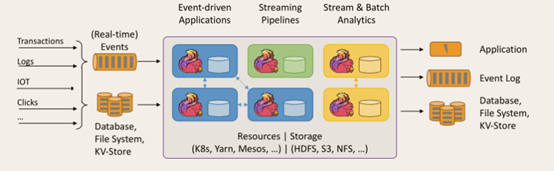
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。
与之不同的就是SparkStreaming微批次,如图:

事件驱动型:

2.2 流与批的世界观
批处理的特点是有界、持久、大量,非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。
流处理的特点是无界、实时, 无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在spark的世界观中,一切都是由批次组成的,离线数据是一个大批次,而实时数据是由一个一个无限的小批次组成的。
而在flink的世界观中,一切都是由流组成的,离线数据是有界限的流,实时数据是一个没有界限的流,这就是所谓的有界流和无界流。
无界数据流:无界数据流有一个开始但是没有结束,它们不会在生成时终止并提供数据,必须连续处理无界流,也就是说必须在获取后立即处理event。对于无界数据流我们无法等待所有数据都到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)获取event,以便能够推断结果完整性。
有界数据流:有界数据流有明确定义的开始和结束,可以在执行任何计算之前通过获取所有数据来处理有界流,处理有界流不需要有序获取,因为可以始终对有界数据集进行排序,有界流的处理也称为批处理。
这种以流为世界观的架构,获得的最大好处就是具有极低的延迟。
2.3 分层api
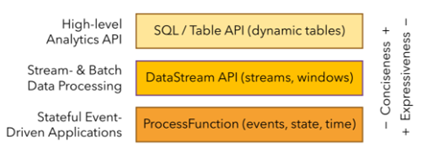
最底层级的抽象仅仅提供了有状态流,它将通过过程函数(Process Function)被嵌入到DataStream API中。底层过程函数(Process Function) 与 DataStream API 相集成,使其可以对某些特定的操作进行底层的抽象,它允许用户可以自由地处理来自一个或多个数据流的事件,并使用一致的容错的状态。除此之外,用户可以注册事件时间并处理时间回调,从而使程序可以处理复杂的计算。
实际上,大多数应用并不需要上述的底层抽象,而是针对核心API(Core APIs) 进行编程,比如DataStream API(有界或无界流数据)以及DataSet API(有界数据集)。这些API为数据处理提供了通用的构建模块,比如由用户定义的多种形式的转换(transformations),连接(joins),聚合(aggregations),窗口操作(windows)等等。DataSet API 为有界数据集提供了额外的支持,例如循环与迭代。这些API处理的数据类型以类(classes)的形式由各自的编程语言所表示。
Table API 是以表为中心的声明式编程,其中表可能会动态变化(在表达流数据时)。Table API遵循(扩展的)关系模型:表有二维数据结构(schema)(类似于关系数据库中的表),同时API提供可比较的操作,例如select、project、join、group-by、aggregate等。Table API程序声明式地定义了什么逻辑操作应该执行,而不是准确地确定这些操作代码的看上去如何 。 尽管Table API可以通过多种类型的用户自定义函数(UDF)进行扩展,其仍不如核心API更具表达能力,但是使用起来却更加简洁(代码量更少)。除此之外,Table API程序在执行之前会经过内置优化器进行优化。
你可以在表与 DataStream/DataSet 之间无缝切换,以允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
Flink提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以SQL查询表达式的形式表现程序。SQL抽象与Table API交互密切,同时SQL查询可以直接在Table API定义的表上执行。
2.4 支持有状态计算
Flink在1.4版本中实现了状态管理,所谓状态管理就是在流失计算过程中将算子的中间结果保存在内存或者文件系统中,等下一个事件进入算子后可以让当前事件的值与历史值进行汇总累计。
2.5 支持exactly-once语义
在分布式系统中,组成系统的各个计算机是独立的。这些计算机有可能fail。
一个sender发送一条message到receiver。根据receiver出现fail时sender如何处理fail,可以将message delivery分为三种语义:
At Most once: 对于一条message,receiver最多收到一次(0次或1次).
可以达成At Most Once的策略:
sender把message发送给receiver.无论receiver是否收到message,sender都不再重发message.
At Least once: 对于一条message,receiver最少收到一次(1次及以上).
可以达成At Least Once的策略:
sender把message发送给receiver.当receiver在规定时间内没有回复ACK或回复了error信息,那么sender重发这条message给receiver,直到sender收到receiver的ACK.
Exactly once: 对于一条message,receiver确保只收到一次
2.6 支持事件时间(EventTime)
目前大多数框架时间窗口计算,都是采用当前系统时间,以时间为单位进行的聚合计算只能反应数据到达计算引擎的时间,而并不是实际业务时间