检查阶段
运行部署前检查的时候
# ansible-playbook -vv playbooks/prerequisites.yml
需要看看play recap是否全过,如果不过需要定位原因,反复执行
之前在检查阶段,因为node1,node2经常连接不上master(设置为yum源)的repo/base,也就是RHEL7.6的包,暂时解决办法是在repo中分别挂在自己本地的源绕开错误。
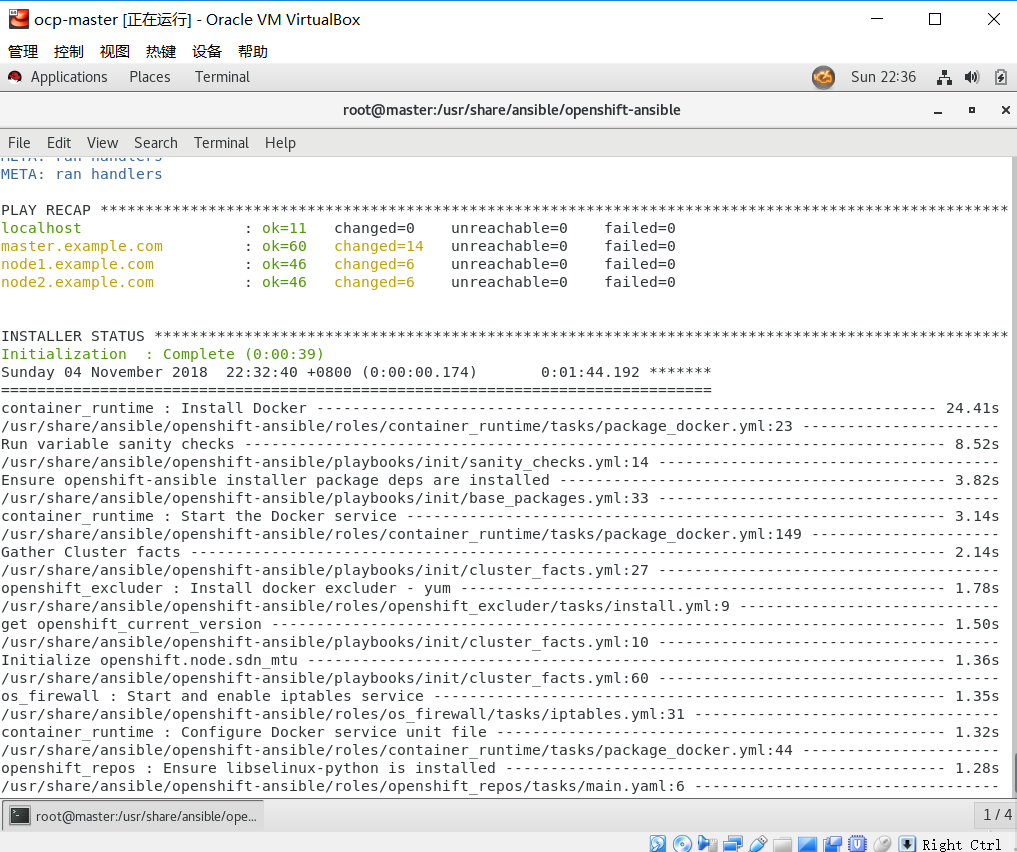
部署阶段
# ansible-playbook -vv /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml
安装完成后的提示,如果有不成功,解决问题以后反复执行。

检查安装
[root@master yum.repos.d]# oc login -u system:admin Logged into "https://master.example.com:8443" as "system:admin" using existing credentials. You have access to the following projects and can switch between them with 'oc project <projectname>': * default kube-public kube-system management-infra openshift openshift-console openshift-infra openshift-logging openshift-metrics-server openshift-monitoring openshift-node openshift-sdn openshift-web-console Using project "default". [root@master yum.repos.d]# oc get nodes NAME STATUS ROLES AGE VERSION master.example.com Ready master 23m v1.11.0+d4cacc0 node1.example.com Ready infra 18m v1.11.0+d4cacc0 node2.example.com Ready compute 18m v1.11.0+d4cacc0
[root@master yum.repos.d]# oc get pods --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE default docker-registry-1-9q962 1/1 Running 0 17m default registry-console-1-4mb7d 1/1 Running 0 17m default router-1-74pr6 1/1 Running 0 17m kube-system master-api-master.example.com 1/1 Running 0 22m kube-system master-controllers-master.example.com 1/1 Running 1 22m kube-system master-etcd-master.example.com 1/1 Running 0 22m openshift-console console-5896bbb547-df6p2 1/1 Running 0 15m openshift-infra hawkular-cassandra-1-k5bg2 1/1 Running 0 12m openshift-infra hawkular-metrics-6ldrw 0/1 Pending 0 6m openshift-infra hawkular-metrics-858mh 0/1 Preempting 0 12m openshift-infra hawkular-metrics-schema-sd7c5 0/1 Completed 0 13m openshift-infra heapster-tvn6t 1/1 Running 0 12m openshift-logging logging-es-data-master-4g5tbuou-1-bcnsx 0/2 Pending 0 5m openshift-logging logging-es-data-master-4g5tbuou-1-deploy 1/1 Running 0 5m openshift-logging logging-fluentd-m5rbg 1/1 Running 0 6m openshift-logging logging-fluentd-m64sn 1/1 Running 0 6m openshift-logging logging-fluentd-nqpz4 1/1 Running 0 6m openshift-logging logging-kibana-1-wpf2t 2/2 Running 0 7m openshift-metrics-server metrics-server-845b478887-vcbkd 0/1 ErrImagePull 0 11m openshift-monitoring alertmanager-main-0 3/3 Running 0 14m openshift-monitoring alertmanager-main-1 3/3 Running 0 14m openshift-monitoring alertmanager-main-2 3/3 Running 0 14m openshift-monitoring cluster-monitoring-operator-674969789d-65rxn 1/1 Running 0 16m openshift-monitoring grafana-7594d8dd75-cwr6p 2/2 Running 0 15m openshift-monitoring kube-state-metrics-787f69cf4d-xjh76 3/3 Running 0 14m openshift-monitoring node-exporter-bwvpv 2/2 Running 0 14m openshift-monitoring node-exporter-hzbb8 2/2 Running 0 14m openshift-monitoring node-exporter-rdzlp 2/2 Running 0 14m openshift-monitoring prometheus-k8s-0 4/4 Running 1 15m openshift-monitoring prometheus-k8s-1 4/4 Running 1 15m openshift-monitoring prometheus-operator-8544897d54-z7249 1/1 Running 0 16m openshift-node sync-6xthq 1/1 Running 0 20m openshift-node sync-rsgz9 1/1 Running 0 19m openshift-node sync-vsbws 1/1 Running 0 19m openshift-sdn ovs-5d2dl 1/1 Running 0 20m openshift-sdn ovs-gd4gw 1/1 Running 0 19m openshift-sdn ovs-ktpt6 1/1 Running 0 19m openshift-sdn sdn-dz8kv 1/1 Running 0 19m openshift-sdn sdn-mhbkg 1/1 Running 0 19m openshift-sdn sdn-x7tq9 1/1 Running 0 20m openshift-web-console webconsole-5db89b6cd4-5sm9d 1/1 Running 2 16m
metrics还出不来
在master节点执行创建admin用户
# htpasswd /etc/origin/master/htpasswd admin
同时赋予admin用户权限
# oc adm policy add-cluster-role-to-user cluster-admin admin
在hosts文件中加入
192.168.0.103 master.example.com
192.168.0.104 console.apps.example.com
192.168.0.104 prometheus-k8s-openshift-monitoring.apps.example.com
192.168.0.104 grafana-openshift-monitoring.apps.example.com
192.168.0.104 hawkular-metrics.apps.example.com
访问https://master.example.com:8443,转到cluster console下,可以访问到集群相关的监控信息
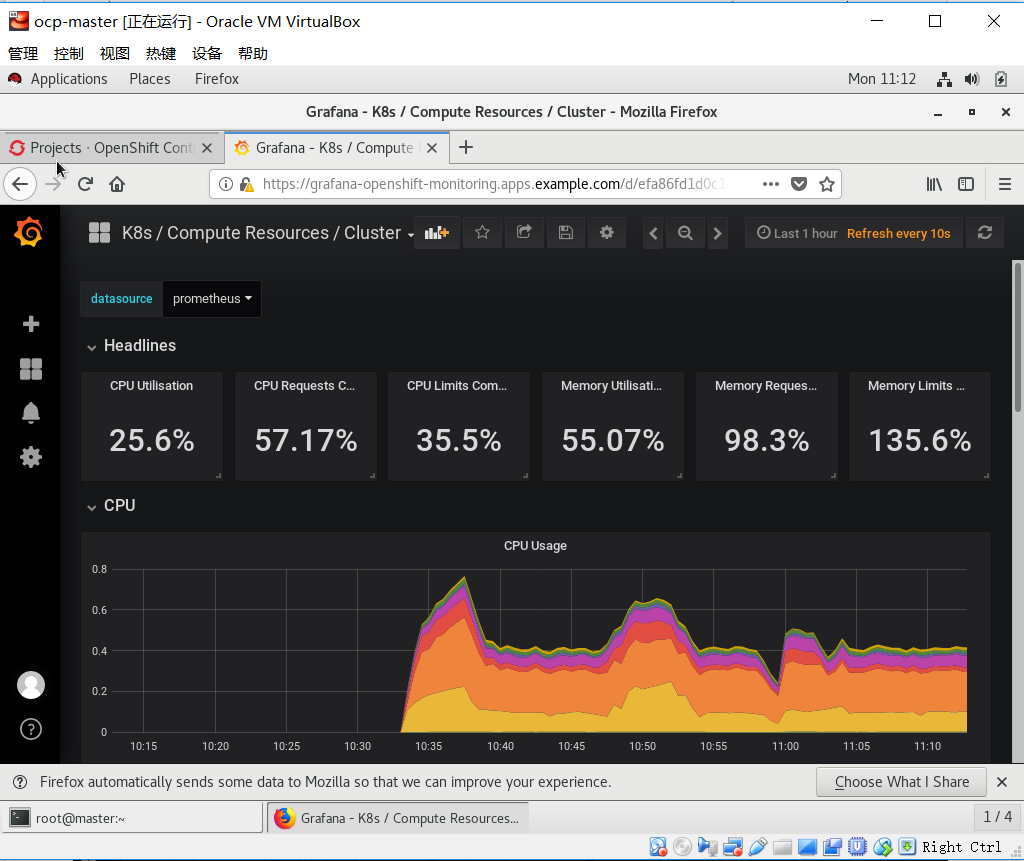
修改错误
- Metrics
经过定位,metrics启动不了的原因主要是两点:
1.ose-metrics-server的镜像缺失,这个重新导入后解决
2.openshift-monitoring下的node2下的node-exporter-sbddr一直启动出错,经过定位发现是安装了一个gitlab软件造成的端口冲突问题,把gitlab停掉后启动成功
[root@master ~]# oc get pods -n openshift-monitoring -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE alertmanager-main-0 3/3 Running 23 21h 10.129.0.69 node1.example.com <none> alertmanager-main-1 3/3 Running 20 21h 10.129.0.66 node1.example.com <none> alertmanager-main-2 3/3 Running 20 21h 10.129.0.68 node1.example.com <none> cluster-monitoring-operator-674969789d-65rxn 1/1 Running 10 21h 10.129.0.65 node1.example.com <none> grafana-7594d8dd75-cwr6p 2/2 Running 18 21h 10.129.0.64 node1.example.com <none> kube-state-metrics-787f69cf4d-xjh76 3/3 Running 20 21h 10.129.0.71 node1.example.com <none> node-exporter-bwvpv 2/2 Running 8 21h 192.168.0.104 node1.example.com <none> node-exporter-hzbb8 2/2 Running 14 21h 192.168.0.103 master.example.com <none> node-exporter-sbddr 2/2 Running 0 13m 192.168.0.105 node2.example.com <none> prometheus-k8s-0 4/4 Running 22 21h 10.129.0.70 node1.example.com <none> prometheus-k8s-1 4/4 Running 22 21h 10.129.0.67 node1.example.com <none> prometheus-operator-8544897d54-z7249 1/1 Running 8 21h 10.129.0.63 node1.example.com <none>
3.openshift-infra下面的hawkular-metrics-9r5nc pod一直在pending状态,describe一下发现需要1.5G的内存,修改rc hawkular-metrics request为500m,后启动成功
[root@master ~]# oc get pods -n openshift-infra -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE hawkular-cassandra-1-k5bg2 1/1 Running 4 21h 10.130.0.42 node2.example.com <none> hawkular-metrics-9r5nc 1/1 Running 0 11m 10.129.0.75 node1.example.com <none> hawkular-metrics-schema-sd7c5 0/1 Completed 0 21h 10.130.0.3 node2.example.com <none> heapster-tvn6t 1/1 Running 39 21h 10.128.0.53 master.example.com <none>
终于也能截图展示一下了。

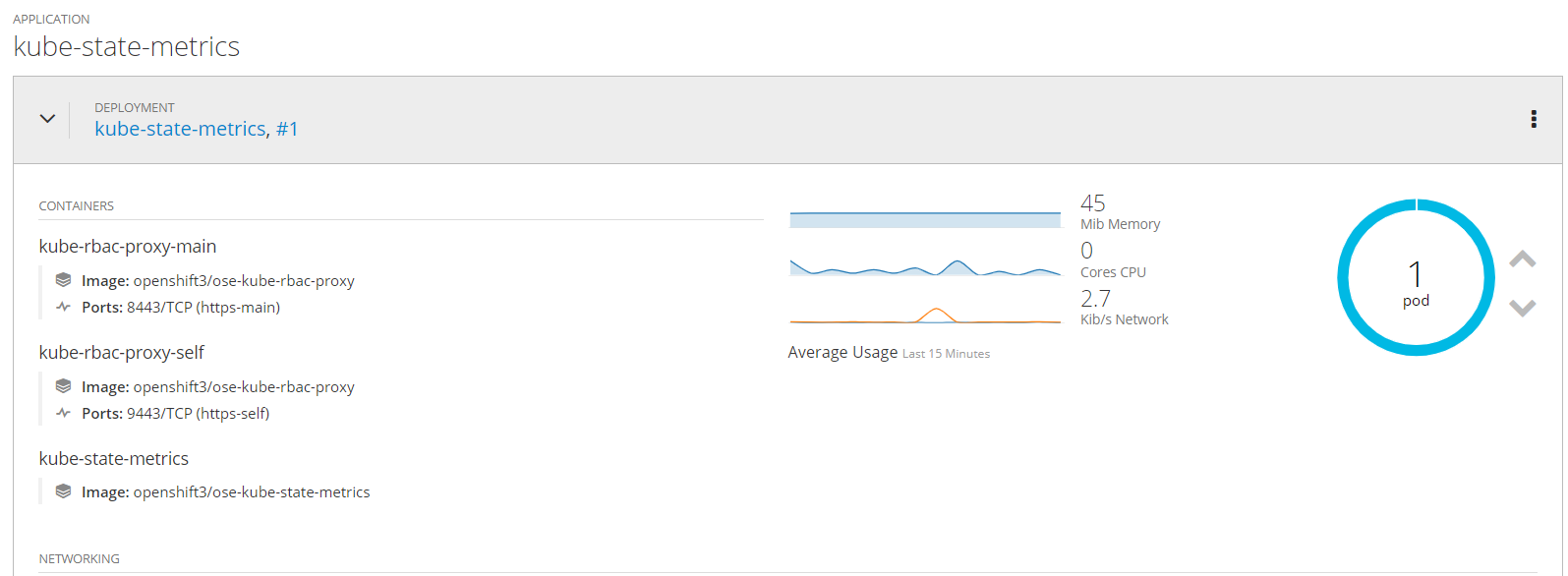
- EFK
经过定位主要是内存不够问题导致,所以现有的16G机器无法折腾了,看了pod启动命令,一个启动起来居然就要8G.令人发指啊!