起因
事情的起因,是看到一篇公众号文章Apache Flink 在汽车之家的应用与实践,里面提到了“基于 SQL 的开发流程”。在平台提供以上功能的基础上,用户可以快速的实现 SQL 作业的开发:
创建一个 SQL 任务;
1.编写 DDL 声明 Source 和 Sink;
2.编写 DML,完成主要业务逻辑的实现;
3.在线查看结果,若数据符合预期,添加 INSERT INTO 语句,写入到指定 Sink 中即可。
即这种功能:
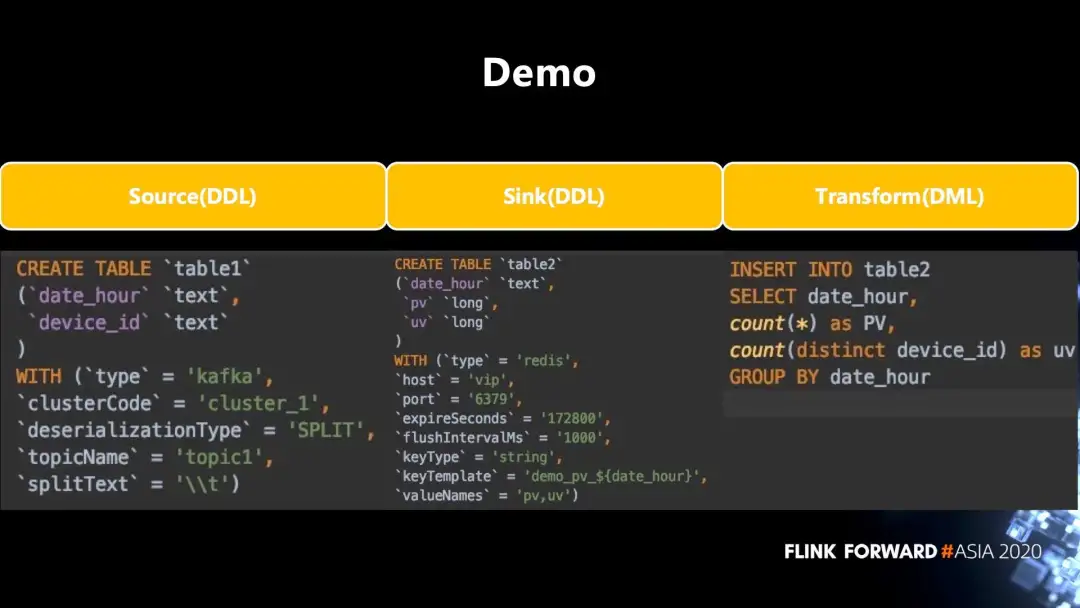
之前也写过一个spark自动提交任务的小项目,但始终无法做到简单交互自动生成任务,因而最终没有用到生产环境当中。Flink的SQL是Flink生态里的一等公民,可以做到直接一条SQL语句把数据源source加载到一张表,也可以一条SQL语句把数据写入到sink终端。这让交互式自动生成任务能够简单实现。
本文前提是,简单实现。如果不考虑性价比,当然也可以做到一个WEB系统,全交互式,点点点,需要的什么参数,什么功能提交到后台,解析生成任务也是可以做的,但这样性价比不高。
思路
1.首先是一个简单的WEB系统,后台springboot可以快速实现,前端thymeleaf可以快速做一个简单的页面,不考虑CSS,JS。
2.然后提供一个页面,传入flink集群参数,mainclass,parallelism等,以及业务参数,主要是sourceSql,sinkSql,transformationSql。然后后台提供一个Flink任务的模板,将sourceSql,sinkSql,transformationSql这三个参数替换掉。再编译成class并生成jar包。
3.然后将jar包提交到flink集群,再将任务提交到集群。
这一点可以通过Flink提供的restapi实现。
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/ops/rest_api/
关于第2点,也可以在模板当中以提供参数的形式传入sourceSql,sinkSql,transformationSql,flink 在提交任务的接口里也提供了这样的参数program-args,但只适合简单的参数,像sql语句这种带大量的引号,空格,换行符不建议这样传参。
实现
功能本身实现起来倒没太大问题。代码就不提供了,光占篇幅。有兴趣的同学可以看github仓库,这里
1.配置
需要修改application的以下4个配置
分别是
flink集群的访问地址,
布置WEB服务的根目录地址,
编译flink任务所依赖的jar包目录,
flink任务main class,也就是flink任务模板的路径(不要写成包名的格式)
flinkurl=http://localhost:8081
rootpath=D://ideaproject//test//flink_remotesubmit
dependmentpath=D://ideaproject//test//flink_remotesubmit//lib
mainpath=//src//main//java//com//yp//flink//model//TableApiModel.java
2.界面如下


提交成功后,跳转到flink任务界面
3.环境
基于
flink 1.13.2
spring boot 2.5
问题
遇到的问题,来自于汽车之家的那张图。就文章里表述的需求来说,需要每天按小时统计PV,UV。
1.flink 的kafka connector 目前只支持批模式(有界数据),不支持流模式(无界)。
如图中红色标记处。
如果按inStreamingMode,那就是实时统计,没法设定batch频次;如果按inBatchMode批次,上图可见,目前不支持。而且kafka connector里参数也只支持kafka的起始位置,不支持结束位置。
所以这里怎么实现的?目前不得而知。

2.还是如上图所见,在sink的时候是只支持append模式,而在append模式下,不支持group by,因为使用了group by 会改行结果行。
如果强行使用group by 将会抛出异常:
目前sink只支持append模式,如果使用了group by 等会改变结果行,会报错:AppendStreamTableSink doesn't support consuming update changes which is produced by node GroupAggregate
所以对kafka数据源进行sink的怎样进行分组聚合?
Flink SQL还是非常强大的。前几天发布的flink 14版本,批执行模式现在支持在同一应用中混合使用 DataStream API 和 SQL/Table API(此前仅支持单独使用 DataStream API 或 SQL/Table API)。也引入了更多的connetor。