数据压缩是机器学习领域中重要的内容,通过数据压缩技术可以将原始数据集变换到一个维度更低的新的特征子空间,帮助对数据存储和分析。
降维压缩数据,分为无监督和有监督两类,先来介绍无监督数据压缩——主成分分析(Principal Component Analysis,PCA)
PCA是在高维数据中找到最大方差的方向,并将数据映射到一个维度不大于原始数据的新的子空间上,可以基于特征之间的关系识别出数据内在的模式。
PCA算法的流程:
- 对原始d维数据集做标准化出来
- 构造样本的协方差矩阵
- 计算协方差矩阵的特征值和相应的特征向量
- 选择与前k个最大特征值对应的特征向量,其中k为新特征空间的维度
- 通过前k个特征向量构建映射矩阵W
- 通过映射矩阵W将d维的输入数据集X转换到新的k维特征子空间
#获取葡萄酒数据集
import pandas as pd
df_wine = pd.read_csv('D:Pythondatawine.data', header=None)
#将数据集划分为训练集(70%)和测试集(30%),并使用单位方差进行标准化
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
X_test_std = sc.fit_transform(X_test)
#构造协方差矩阵
import numpy as np
cov_mat = np.cov(X_train_std.T) #协方差矩阵
eigen_vals, eigen_vecs = np.linalg.eig(cov_mat) #使用Numpy的linalg.eig函数计算数据集协方差矩阵的特征值对
print ('
Eigenvalues
%s' % eigen_vals)
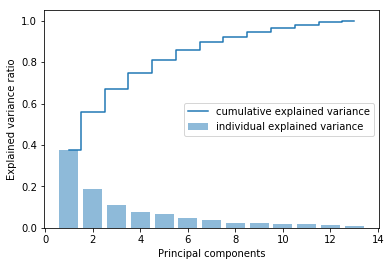
#特征值的方差贡献率
tot = sum(eigen_vals)
var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)]
cum_var_exp = np.cumsum(var_exp) #Numpy cumsum计算累计方差
import matplotlib.pyplot as plt
plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='individual explained variance') #单个方差贡献
plt.step(range(1, 14), cum_var_exp, where='mid', label='cumulative explained variance') #累计方差贡献
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.show()
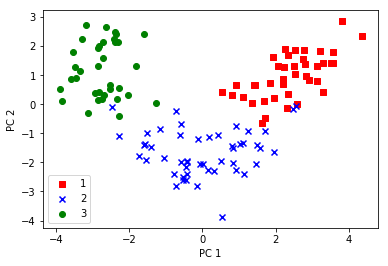
eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i])
for i in range(len(eigen_vals))]
eigen_pairs.sort(key = lambda k : k[0], reverse=True) #按特征值的降序排列特征
w = np.hstack((eigen_pairs[0][1] [:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) #选取两个最大特征值对应的特征向量 得到一个13*2的映射矩阵W
print ('Matrix W:
', w)
X_train_std[0].dot(w)
print (X_train_std[0].dot(w))
X_train_pca = X_train_std.dot(w) #矩阵点积 将124*13的训练集转换为包含两个主成分的子空间上 124*2
print(X_train_pca)
#二维散点图可视化
colors = ['r', 'b', 'g']
markers = ['s', 'x', 'o']
for l, c, m in zip(np.unique(y_train), colors, markers):
plt.scatter(X_train_pca[y_train == l, 0],
X_train_pca[y_train == l, 1],
c=c, label=l, marker=m)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.show()
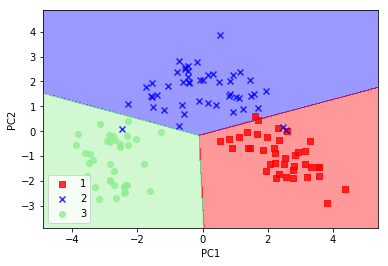
scikit-learn中提供的PCA类 对数据集预处理再使用逻辑斯蒂回归对转换后的数据进行分类
from matplotlib.colors import ListedColormap
import matplotlib.pyplot as plt
#对二维数据集决策边界可视化
def plot_decision_regions(X, y, classifier, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))]) #ListedColormap定义颜色 标记符号,通过颜色列表生成颜色示例图
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
from sklearn.linear_model import LogisticRegression
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
lr = LogisticRegression()
X_train_pca = pca.fit_transform(X_train_std)
X_test_pca = pca.transform(X_test_std)
lr.fit(X_train_pca, y_train)
plot_decision_regions(X_train_pca, y_train, classifier=lr)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='lower left')
plt.show()