大纲
这篇文章是介绍sklearn库的使用,主要围绕sklearn官网内容进行阐述。包括三个部分的内容:
1.背景——主要介绍sklearn库是干什么的,官网内容板块是怎样的,我们主要从哪块学起;
2.框架——主要从模型使用流程角度出发,阐述sklearn主要实现的内容;
3.API——以从应用出发来说,API是sklearn第一学习目标,这块以操作(包括加载数据-预处理-模型评估等)和算法两个部分为主要划分,以每个操作或算法为小节,介绍每块API的使用。在使用学习路径上,主要以API-examples-user guide这样的路径查看相关资料,以便搞清楚API的使用。
其他就是一些参考资料也附在文章底部,也比较有启发性,可以参考下。
一、背景
sklearn封装了许多机器学习算法,在应用为主理论为辅的学习路径中,学习sklearn是一个不错的选择。
sklearn官网有足够丰富的内容,下面对官网相关板块进行了简单备注。我们主要看API部分,即需要的算法用什么类或函数以及参数是什么。其次,tutorials/user guide/glossary/examples都可以参考看一下。tutorials是机器学习过程的一个简要教程;user guide主要是一些算法的详细解释,不太理解API的某些内容可以进一步看这块;glossary是一些相关术语的解释,可以直接搜不理解的术语;examples则是一些具体的案例,一些主要算法不知道怎么入手可以看案例。如果需要安装sklearn,可以看看installation,Anaconda是预装了科学计算相关包的,如果不用Anaconda,注意sklearn是依赖numpy/scipy/matplotlib这三个包的,需要先安装。
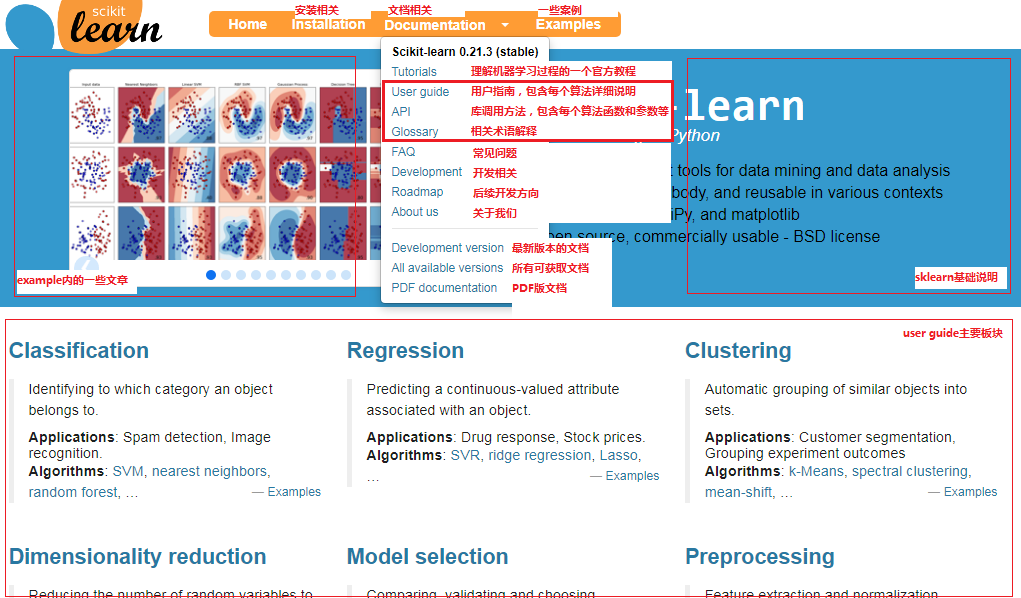
二、框架
从进行机器学习步骤出发,sklearn划分为如下几个模块:
加载数据集——数据预处理——选择和训练模型——评估模型——保存和恢复模型以便使用模型预测
1)加载数据集
数据集要么是在具体项目中需要使用的数据源,要么是公共的数据源。sklearn提供了加载一些公开的数据源库。具体可参考如下使用案例和API介绍。
https://scikit-learn.org/stable/auto_examples/index.html#dataset-examples
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.datasets
2)数据预处理
数据预处理包括降维、数据归一化、特征提取和特征转换(one-hot)等。具体可参考如下使用案例和API介绍。
https://scikit-learn.org/stable/auto_examples/index.html#preprocessing
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.preprocessing
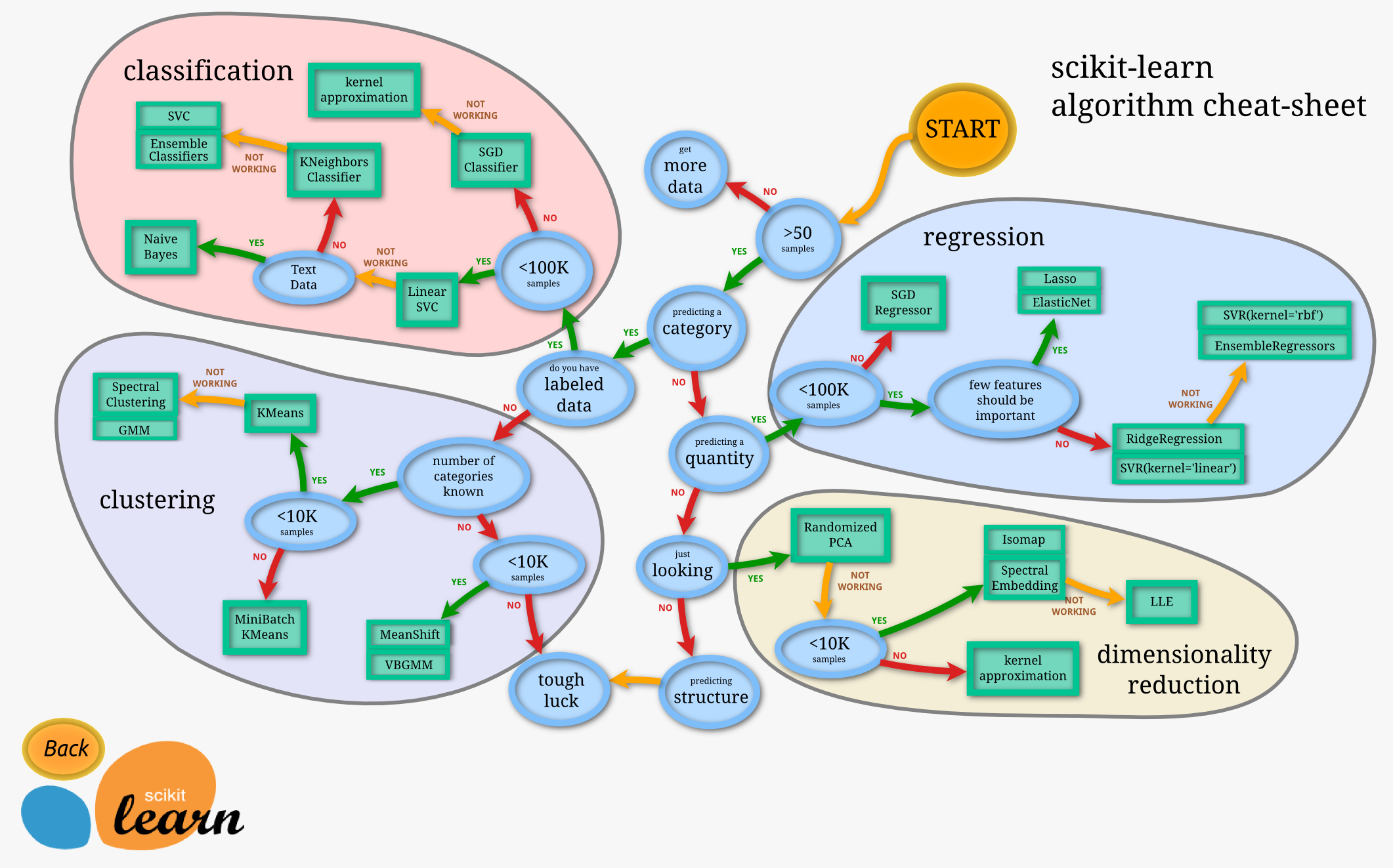
3)选择和训练模型
这部分直接找相关算法的案例和API即可。
在tutorials的Choosing the right estimator里有一个简单的示意图描述选择模型的简单流程:
4)评估模型
https://scikit-learn.org/stable/modules/classes.html#sklearn-metrics-metrics
5)保存和恢复模型以便使用模型预测
pickle库或sklearn自带的joblib模块。
三、API
首先按官网内容排版备注一下都有哪些模块,哪些模块包括哪些常用的方法。
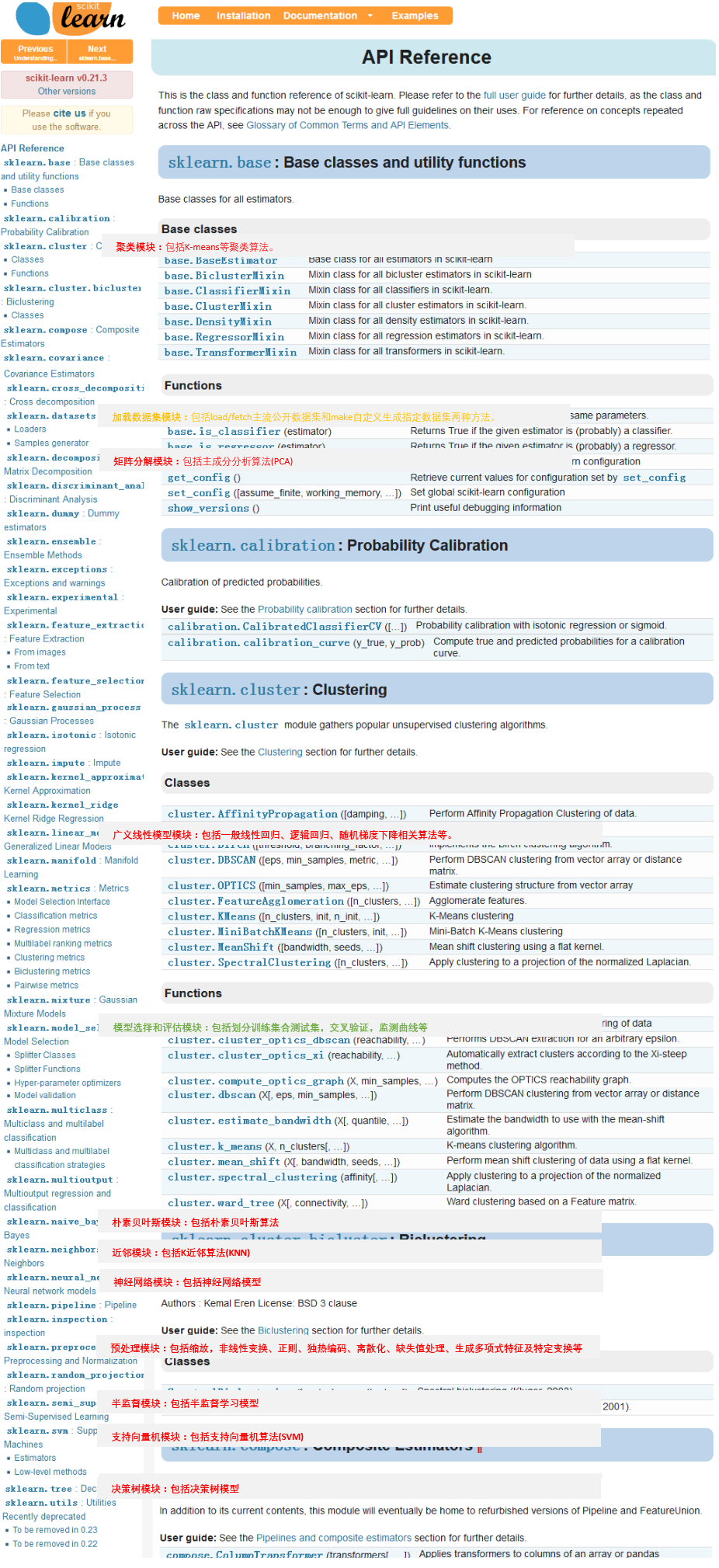
其次从操作(O)和模型(M)角度分别汇总简单API,便于由此展开了解。进一步直接可用的API可查看【代码API篇】。
1)M_分类_决策树


from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier(criterion='gini', --设置衡量的系数,有entropy和gini,默认gini splitter='best', --选择分类的策略,best和random,默认best max_depth=5, --设置树的最大深度 min_samples_split=10,-- 区分一个内部节点需要的最少的样本数 min_samples_leaf=5 -- 一个叶节点所需要的最小样本数 max_features=5 --最大特征数 max_leaf_nodes=3--最大样本节点个数 min_impurity_split --指定信息增益的阀值 ) clf= clf.fit(x_train,y_train) -- 拟合训练
2) M_分类_逻辑回归
from sklearn.linear_model import LogisticRegression clf = LogisticRegression(penalty='l2', --惩罚项(l1与l2),默认l2 dual=False, --对偶或原始方法,默认False,样本数量>样本特征的时候,dual通常设置为False tol=0.0001, --停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解 C=1.0, --正则化系数λ的倒数,float类型,默认为1.0,越小的数值表示越强的正则化。 fit_intercept=True, --是否存在截距或偏差,bool类型,默认为True。 intercept_scaling=1, --仅在正则化项为”liblinear”,且fit_intercept设置为True时有用。float类型,默认为1 class_weight=None, --用于标示分类模型中各种类型的权重,默认为不输入,也就是不考虑权重,即为None random_state=None, --随机数种子,int类型,可选参数,默认为无 solver='liblinear', --优化算法选择参数,只有五个可选参数,即newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear max_iter=10, --算法收敛最大迭代次数,int类型,默认为10。 multi_class='ovr'--分类方式选择参数,str类型,可选参数为ovr和multinomial,默认为ovr。 如果是二元逻辑回归,ovr和multinomial并没有任何区别,区别主要在多元逻辑回归上。 verbose=0, --日志冗长度,int类型。默认为0。就是不输出训练过程 warm_start=False, --热启动参数,bool类型。默认为False。 n_jobs=1--并行数。int类型,默认为1。1的时候,用CPU的一个内核运行程序,2的时候,用CPU的2个内核运行程序。 ) clf= clf.fit(x_train,y_train) -- 拟合训练
3)M_回归_线性回归
from sklearn.linear_model import LinearRegression() clf = LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False) clf= clf.fit(x_train,y_train) -- 拟合训练
4)M_聚类_kmeans聚类
from sklearn.cluster import KMeans clf = KMeans(n_clusters=4, --给定的类别数 max_iter=100,--为迭代的次数,这里设置最大迭代次数为300 n_init=10,--设为10意味着进行10次随机初始化,选择效果最好的一种来作为模型 copy_x=True--布尔型,默认值=True,如果把此参数值设为True,则原始数据不会被改变。如果是False,则会直接在原始数据 上做修改并在函数返回值时将其还原。 ) clf= clf.fit(x) -- 拟合训练
5)M_分类_支持向量机SVM
from sklearn.svm import SVC model = SVC(C=1.0, kernel=’rbf’, gamma=’auto’) """参数 --- C:误差项的惩罚参数C gamma: 核相关系数。浮点数,If gamma is ‘auto’ then 1/n_features will be used instead. """
6)M_分类_K近邻KNN
from sklearn import neighbors #定义kNN分类模型 model = neighbors.KNeighborsClassifier(n_neighbors=5, n_jobs=1) # 分类 model = neighbors.KNeighborsRegressor(n_neighbors=5, n_jobs=1) # 回归 """参数 --- n_neighbors: 使用邻居的数目 n_jobs:并行任务数 """
7)M_分类_朴素贝叶斯
from sklearn import naive_bayes model = naive_bayes.GaussianNB() # 高斯贝叶斯 model = naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None) model = naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None) """ 文本分类问题常用MultinomialNB 参数 --- alpha:平滑参数 fit_prior:是否要学习类的先验概率;false-使用统一的先验概率 class_prior: 是否指定类的先验概率;若指定则不能根据参数调整 binarize: 二值化的阈值,若为None,则假设输入由二进制向量组成 """
8)神经网络
from sklearn.neural_network import MLPClassifier # 定义多层感知机分类算法 model = MLPClassifier(activation='relu', solver='adam', alpha=0.0001) """参数 --- hidden_layer_sizes: 元祖 activation:激活函数 solver :优化算法{‘lbfgs’, ‘sgd’, ‘adam’} alpha:L2惩罚(正则化项)参数。 """
资料参考
官网——随时查
https://scikit-learn.org/stable/
sklearn库的学习——看不懂官网结构可以看这个
https://blog.csdn.net/u014248127/article/details/78885180
ML神器:sklearn的快速使用——入门介绍很简洁了
https://www.cnblogs.com/lianyingteng/p/7811126.html
机器学习的分类与主要算法对比
https://blog.csdn.net/sinat_27554409/article/details/72823984
机器学习sklearn19.0——Logistic回归算法
https://blog.csdn.net/loveliuzz/article/details/78708359
一文入门Scikit-Learn分类器
https://cloud.tencent.com/developer/article/1459623
Python笔记--sklearn函数汇总