- Background
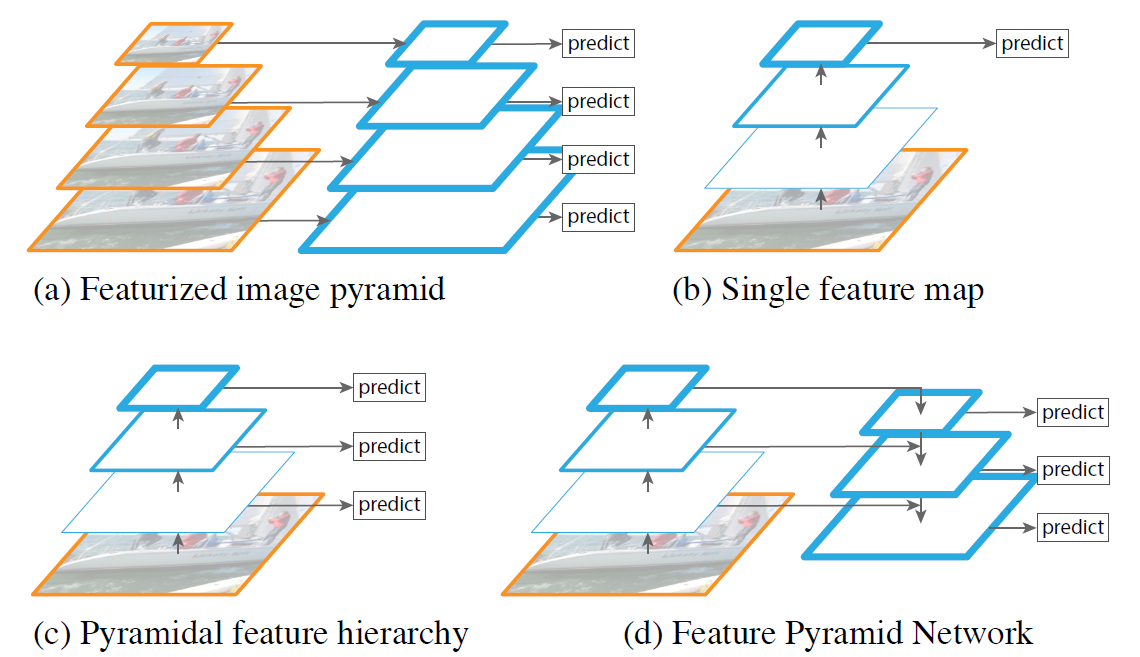
在做目标检测的时候,目标可大可小,如何检测出各种尺度下目标是计算机视觉面临的一个很大挑战。既然目标有多个尺度,那么我是不是可以提取多个尺度的特征呢?答案是肯定的,如下图(a)所示(蓝色的框代表feature map,框的线条越粗,其表达语义的能力越强),我们可以获取输入图像的不同尺度、并在不同尺度上提取特征(如Sift、HOG),然后进行目标的预测。传统的做法是先获取图像的不同尺度,然后分别提取不同尺度图像的feature maps。优势是,不同尺度feature maps的语义表达能力相当,缺点是计算量较大。
下图(b)示意了现在深度学习方法常用的策略,用深度网络提取的feature maps代替传统方法提取feature maps(原因就是深度网络提取的特征表达能力更强)。从底层到高层,深度网络输出的feature maps语义表达能力逐渐增强,我们可以直接在高层feature maps基础上进行目标预测。如果我们把所有尺度的输入图像,都进行类似的处理,则可以进行不同尺度的目标的检测。由于深度网络计算量较大,这样做效率较低。如果针对各个尺度的输入图像设计端对端训练的网络结构,由于硬件资源的限制,较难。
为什么我们不直接利用深度网络本身就具有的多尺度特性呢?这正是图(c)所示方法的一个做法。这样做的一个坏处就是深度网络不同尺度的feature maps具有不同的“语义表达”水平。而如何使得深度网络不同尺度的feature maps具有相同的“语义表达”水平正是本文追求的一个目标。
这样我们就可以达到图(a)的效果,但是并没有针对各个尺度的输入图像都进行相同的feature maps提取过程。
- Main points
1) 上述思路之前也有人做过,只不过它是在“强化语义表达”之后的具有更高分辨率的feature maps进行目标预测的。如下图上所示,而本文则利用所有尺度的feature maps进行预测如下图下所示。
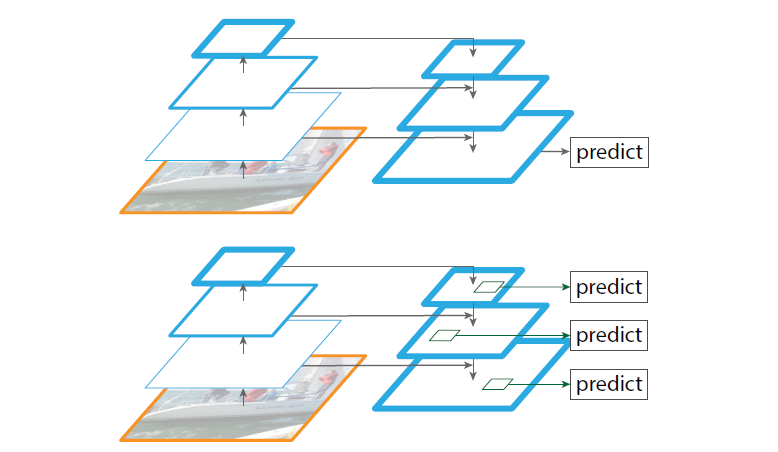
2)具体做法也比较简单,就是通过一个侧向连接输出这一个尺度的feature maps,然后对这一尺度的feature maps进行上采样,与它下一个尺度的输出feature maps进行element-wise add,得到“强化语义表达”的输出feature maps,如下图所示。
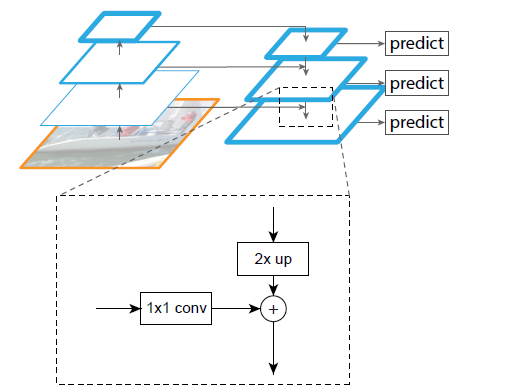
3)下面的问题就是,基础网络结构怎么设计、侧向连接的building blocks怎么选、目标预测器怎么设计、“强化语义表达”的feature maps要不要进行一些平滑处理(消除上采样带来的模糊)以及随着而来的各种参数设计。说句实话,下面的问题就是采用什么样的网络结构以何种方式应用输出的“多次度、语义表达能力相近”的feature maps。本文选取的是残差网络,这一块我就不深入分析了。有兴趣的话,大家可以读读原始paper。
- Summary
1)这篇paper做的事情可以概括为“深度网络输出的不同尺度的feature maps如何reuse以得到语义表达能力近似的多次度feature maps”;
2)活用了“上采样、element-wise add”;
3)有思想,然后采用现有的技术手段实现自己的想法,哈哈!
4)我觉得难点应该是,网络结构的选取、预测器的设计、侧向连接的设计以及各种超参数的选择。此时,想起了速8的一句台词“我们在做选择”,这里我们选择的是网络结构。
5)简单的思路,不是每个人都可以实现不错的实验效果的哦!大家还是得在网络结构设计方面有自己独到的见解哦!