问题:
在数据库中多处使用到了字典,现在平台需要对字典进行管理,也就是现在的字典表不再是固定的,他是可以变化的,可以增加,删除,变更。
在删除的时候就需要之前引用这个字典值的地方清空
比如说字典里面有个字典YY_title(头衔),它里面有个(1,博士),专家表里面有三条数据引用了这一条字典记录,在专家表里面只存了一个“1”,当然这个字典可以被n个业务表引用,如果说现在的头衔里面不再使用博士这一项了,那么之前业务表里面存的“1”自然是要置空的,现在的问题是怎么通过字典找到引用他的业务表?
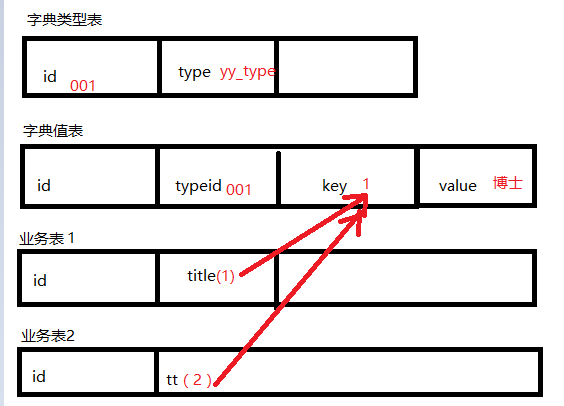
实际场景:
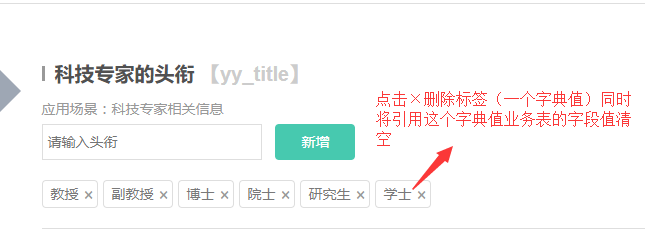
解决方案:
新建关联表(中性表),关系表的结构如下图:【中间过程,有问题,正确结构图在下面】
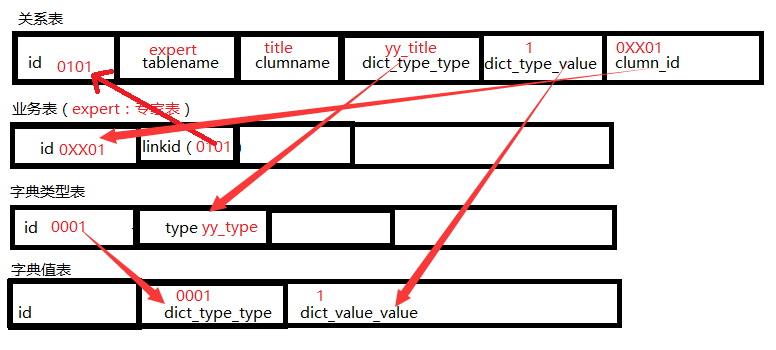
对关联表的操作放在业务表的处理过程中:
(1)增加记录:在业务表新增记录的时候就新建一条关系记录,并将关系表的id存在业务表中
(2)修改记录:在业务表中修改(添加)存放的值的时候,修改关系表中的字典的值
应用过程出现的问题:
(1)在我将某个标签(字典值)删除的时候,需要将引用其的业务项的该字段置空:
UPDATE ${param1} SET ${param2} = '' WHERE id = #{param3}
这段代码理论上是没有问题的,执行结果也对。
但是!!!接下来在查询引用该字段的业务项的数量时发现结果竟然不是零!!代码如下
SELECT count(id) FROM zgl_dictlink a WHERE a.dicttype= 'yy_title' and a.dictvalue= '0'
这段代码理论上是也没有问题的,那么是什么原因导致的这个现象?
仔细分析下,原来是数据库结构设计的有问题!有冗余。。
既然在字典的关系表中标明了使用到的表名,字段名,实体id,又为什么要在业务表中添加字典联系表的id呢。所以说这个id是多余的。
该方案的缺点:
优化:
(1)这可以在字典值表中新加个调用次数字段,用于统计被调用次数。(在没有使用中性表的时候这种方法对于统计调用次数是非常有效的,当然在使用了中性表后,调用次数可以直接的中性表中查询)
(2)缓存。这个现在知识一个想法,具体实现之后再补充。。