5.1 MNIST数据处理
MNIST是一个非常有名的手写数字识别数据集,一般被用作深度学习的入门样例。MNIST数据集是NIST数据集的一个子集,它包含了60000张图片作为训练数据,10000张图片作为测试数据。
通过input_data.read_data_sets函数生成的类会自动将MNIST数据集划分为train、validation和test三个数据集,其中train这个集合内有55000张图片,validation集合内有5000张图片,这两个集合组成了MNIST本身提供的训练数据集。test集合内有10000张图片,这些图片都来自于MNIST提供的测试数据集。
5.2 神经网络模型训练
以下代码给出一个在MNIST数据集上实现这些功能的完整TensorFlow程序。


import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 # 输入节点 OUTPUT_NODE = 10 # 输出节点 LAYER1_NODE = 500 # 隐藏层数 BATCH_SIZE = 100 # 每次batch打包的样本个数 # 模型相关的参数 LEARNING_RATE_BASE = 0.8 LEARNING_RATE_DECAY = 0.99 REGULARAZTION_RATE = 0.0001 TRAINING_STEPS = 5000 MOVING_AVERAGE_DECAY = 0.99 ------------------------------------------------------------------------ def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2): # 不使用滑动平均类 if avg_class == None: layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1) return tf.matmul(layer1, weights2) + biases2 else: # 使用滑动平均类 layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1)) return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2) ------------------------------------------------------------------------- def train(mnist): x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input') y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name='y-input') # 生成隐藏层的参数。 weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1)) biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE])) # 生成输出层的参数。 weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1)) biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE])) # 计算不含滑动平均类的前向传播结果 y = inference(x, None, weights1, biases1, weights2, biases2) # 定义训练轮数及相关的滑动平均类 global_step = tf.Variable(0, trainable=False) variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) variables_averages_op = variable_averages.apply(tf.trainable_variables()) average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2) # 计算交叉熵及其平均值 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1)) cross_entropy_mean = tf.reduce_mean(cross_entropy) # 损失函数的计算 regularizer = tf.contrib.layers.l2_regularizer(REGULARAZTION_RATE) regularaztion = regularizer(weights1) + regularizer(weights2) loss = cross_entropy_mean + regularaztion # 设置指数衰减的学习率。 learning_rate = tf.train.exponential_decay( LEARNING_RATE_BASE, global_step, mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY, staircase=True) # 优化损失函数 train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step) # 反向传播更新参数和更新每一个参数的滑动平均值 with tf.control_dependencies([train_step, variables_averages_op]): train_op = tf.no_op(name='train') # 计算正确率 correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 初始化会话,并开始训练过程。 with tf.Session() as sess: tf.global_variables_initializer().run() validate_feed = {x: mnist.validation.images, y_: mnist.validation.labels} test_feed = {x: mnist.test.images, y_: mnist.test.labels} # 循环的训练神经网络。 for i in range(TRAINING_STEPS): if i % 1000 == 0: validate_acc = sess.run(accuracy, feed_dict=validate_feed) print("After %d training step(s), validation accuracy using average model is %g " % (i, validate_acc)) xs,ys=mnist.train.next_batch(BATCH_SIZE) sess.run(train_op,feed_dict={x:xs,y_:ys}) test_acc=sess.run(accuracy,feed_dict=test_feed) print(("After %d training step(s), test accuracy using average model is %g" %(TRAINING_STEPS, test_acc))) ------------------------------------------------------------------------ def main(argv=None): mnist = input_data.read_data_sets("../../../datasets/MNIST_data", one_hot=True) train(mnist) if __name__=='__main__': main() ------------------------------------------------------------------------- Extracting ../../../datasets/MNIST_data/train-images-idx3-ubyte.gz Extracting ../../../datasets/MNIST_data/train-labels-idx1-ubyte.gz Extracting ../../../datasets/MNIST_data/t10k-images-idx3-ubyte.gz Extracting ../../../datasets/MNIST_data/t10k-labels-idx1-ubyte.gz After 0 training step(s), validation accuracy using average model is 0.1156 After 1000 training step(s), validation accuracy using average model is 0.9768 After 2000 training step(s), validation accuracy using average model is 0.982 After 3000 training step(s), validation accuracy using average model is 0.9828 After 4000 training step(s), validation accuracy using average model is 0.9838 After 5000 training step(s), test accuracy using average model is 0.9831
上述用的 tf.nn.sparse_softmax_cross_entropy_with_logits 这个函数和tf.nn.softmax_cross_entropy_with_logits函数比较明显的区别在于它的参数labels的不同,这里的参数label是非稀疏表示的,一般用到频率更高
用法为 cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
另一种 tf.nn.softmax_cross_entropy_with_logits的用法,博客很容易理解,也有将此函数拆分的对比
将损失函数改为 cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=y_),得到的准确率会有略微差距
Extracting ../../../datasets/MNIST_data/train-images-idx3-ubyte.gz Extracting ../../../datasets/MNIST_data/train-labels-idx1-ubyte.gz Extracting ../../../datasets/MNIST_data/t10k-images-idx3-ubyte.gz Extracting ../../../datasets/MNIST_data/t10k-labels-idx1-ubyte.gz After 0 training step(s), validation accuracy using average model is 0.1078 After 1000 training step(s), validation accuracy using average model is 0.9768 After 2000 training step(s), validation accuracy using average model is 0.9792 After 3000 training step(s), validation accuracy using average model is 0.9814 After 4000 training step(s), validation accuracy using average model is 0.9838 After 5000 training step(s), test accuracy using average model is 0.9814
另外,除了使用验证数据集,还可以采用交叉验证(cross_validation)的方式来验证模型效果。但因为神经网络训练时间本身就比较长,采用cross_validation会花费大量世间。所以在海量数据的情况下,一般更多地采用验证数据集的形式来评测模型的效果。
总的来说,通过MNIST数据集有效地验证了激活函数、隐藏层可以给模型的效果带来质的飞跃。由于MNIST问题本身相对简单,滑动平均模型、指数衰减的学习率和正则化损失对最终正确率的提升效果不明显。
5.3 变量管理
TF中通过变量名称获取变量的机制主要是通过tf.get_variable和tf.variable_scope函数实现的。tf.get_variable函数可以创建或获取变量,当它用于创建变量时,它和tf.Variable的功能基本等价。
#下面两个定义是等价的 v=tf.get_variable("v",shape=[1],initializer=tf.constant_initializer(1.0)) v=tf.Variable(tf.constant(1.0,shape=[1]),name="v")
上述样例中使用到的常数初始化函数tf.constant_initializer和常数生成函数和tf.constant功能上就是一致的。TF提供了7种不同的初始化函数:Tensorflow中的变量初始化函数
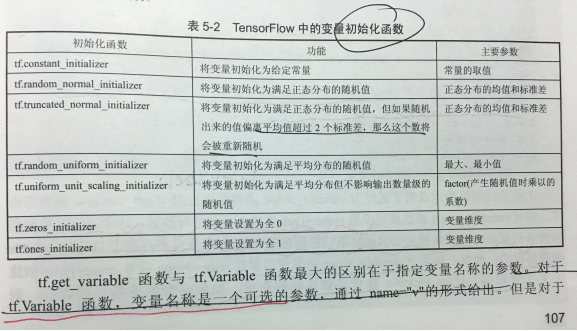
当tf.variable_scope函数使用参数reuse=True生成上下文管理器时,这个上下文管理器内所有的tf.get_variable函数会直接获取已经创建的变量。如果变量不存在,则tf.get_variable函数将报错;相反如果tf.variable_scope函数使用参数reuse=None或者reuse=False创建上下文管理器,tf.get_variale操作将创建新的变量。如果同名的变量已经存在,则tf.get_variable函数将报错。
with tf.variable_scope("foo"):
v = tf.get_variable("v", [1], initializer=tf.constant_initializer(1.0))
#with tf.variable_scope("foo"): 报错already exists
# v = tf.get_variable("v", [1])
with tf.variable_scope("foo", reuse=True):
v1 = tf.get_variable("v", [1])
print v == v1
#with tf.variable_scope("bar", reuse=True): 报错 doesn't exist
# v = tf.get_variable("v", [1])
#嵌套上下文管理器中的reuse参数的使用 with tf.variable_scope("root"): print tf.get_variable_scope().reuse with tf.variable_scope("foo", reuse=True): print tf.get_variable_scope().reuse with tf.variable_scope("bar"): print tf.get_variable_scope().reuse print tf.get_variable_scope().reuse -------------------------------------------------------------------------- False True True False
#通过variable_scope来管理变量 v1 = tf.get_variable("v", [1]) print v1.name with tf.variable_scope("foo",reuse=True): v2 = tf.get_variable("v", [1]) print v2.name with tf.variable_scope("foo"): with tf.variable_scope("bar"): v3 = tf.get_variable("v", [1]) print v3.name v4 = tf.get_variable("v1", [1]) print v4.name ---------------------------------------------------------------------------- v:0 foo/v:0 foo/bar/v:0 v1:0 ------------------------------------------------------------------------- #我们可以通过变量的名称来获取变量 with tf.variable_scope("",reuse=True): v5 = tf.get_variable("foo/bar/v", [1]) print v5 == v3 v6 = tf.get_variable("v1", [1]) print v6 == v4 ------------------------------------------------------------------------- True True
