在Java8中特别提到了流式计算,在流式计算中就有MapReduce概念。
如果要想使用Hadoop的MapReduce,则必须将要进行统计的文件内容保存在HDFS之中。
下面通过代码来实现一个单词统计的操作,单词统计也被称为Hadoop界的“Hello World”程序。

在给出的文件之中会包含具体的单词信息,每个单词之间可以使用空格进行拆分处理。
我们要处理的事情只是编写一个具体的程序将这些文件进行组成分析而已,只不过本次的分析简单一点,只做了单词的统计。
对MapReduce而言,实际上是属于两个层次的概念:
- Map阶段:对数据的处理阶段
- Reduce阶段:对处理后的数据进行计算
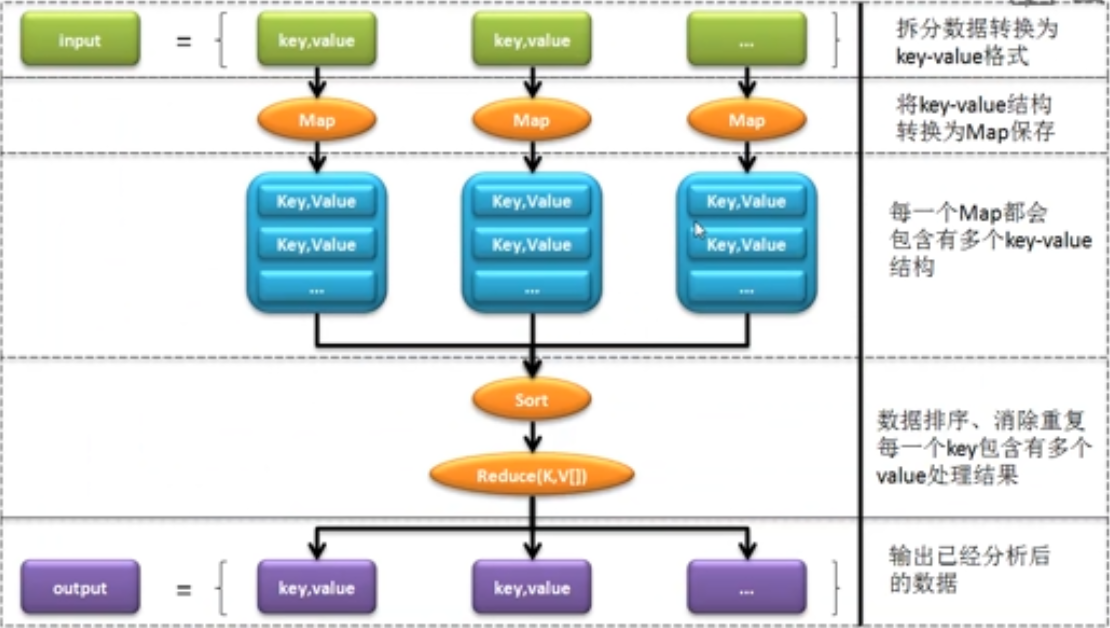
以上流程属于官方推荐的流程,但作为初学者可能不理解。
为了帮助理解,将通过一个具体的分析来进行说明:
范例:定义一个要进行统计的原始文件
| Hello MLDN Hello Yootk |
| Hello Bye Bye Bye |
| Hello MLDN |
里面有许多单词组成,那么最终肯定是需要将这些信息进行汇总,但如果使用MapReduce操作处理,流程如下:
| Map处理 | 排序处理 | 合并处理 | Reduce处理 |
|
<Hello,1> <MLDN,1> <Hello,1> <Yootk,1> <Hello,1> <Bye,1> <Bye,1> <Bye,1> <Hello,1> <MLDN,1> |
<Bye,1> <Bye,1> <Bye,1> <Hello,1> <Hello,1> <Hello,1> <Hello,1> <MLDN,1> <MLDN,1> <Yootk,1> |
<Bye,1,1,1> <Hello,1,1,1,1> <MLDN,1,1><Yootk,1> |
<Bye,3> <Hello,4> <MLDN,2><Yootk,1> |
Map处理和Reduce处理一定是自己处理(知道怎么拆,怎么统计)
排序处理和合并处理则为自动处理,整个操作称为一个完整的作业“Job”.
范例:实现单词统计的操作代码(配置java环境变量,并使用javac、java编译运行、JAVA+Eclipse开发环境的配置)
如果要想进行代码的编写是需要使用到Hadoop中提供的*.jar文件的:
- 路径:C:UsersAdministratorDownloadshadoop-2.7.6sharehadoop(直接解压缩)
需要配置如下几个路径的开发包:
- common组件包:
- C:UsersAdministratorDownloadshadoop-2.7.6sharehadoopcommon
- C:UsersAdministratorDownloadshadoop-2.7.6sharehadoopcommonlib
- mapreduce组件包:
- C:UsersAdministratorDownloadshadoop-2.7.6sharehadoopmapreduce
- C:UsersAdministratorDownloadshadoop-2.7.6sharehadoopmapreducelib
快捷键(Alt+/补全 Ctrl+Shift+O导入包)
package com.yootk.mr.demo; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { //本处要求实现单词统计的处理操作 // 在整个代码之中最为关键的部分就是Map部分与Reduce部分,而且这两个部分是需要用户自己来实现的 /* * 本操作主要进行Map的数据处理 * 在Mapper父类里面接受的内容如下: * object:输入数据的具体内容(可以返回操作的行号) * Text:每行的文本数据(行内容) * Text:每个单词分解后的统计结果 * IntWritable:输出记录的结果 */ @SuppressWarnings("unused") private static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> { @Override //map实现数据拆分的操作 protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { //默认情况下是取得每行的数据,所以每行的数据里面都会存在空格,那么要按照空格进行拆分,每当出现一个单词就需要做一个统计的1 String lineContent = value.toString();//取出每行的数据 String result [] = lineContent.split(" ");//按照空格进行数据拆分 for (int x = 0 ;x <result.length ; x++){//循环每个单词而后进行数据的生成 //每一个单词最终生成的保存个数是1 context.write(new Text(result[x]), new IntWritable(1)); } } } /* * 进行合并后数据的最终统计 * 本次要使用的类型信息如下: * Text:Map输出的文本内容 * IntWritable:Map处理的个数 * Text:Reduce输出文本 * IntWritable:Reduce的输出个数 */ @SuppressWarnings("unused") private static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0;//保存每个单词出现的数据量 for (IntWritable count : values) { sum += count.get(); } context.write(key, new IntWritable(sum)); } } public static void main(String[] args) throws Exception { if (args.length != 2){ System.out.println("本程序需要两个参数,执行:hadoop jar yootk.jar /input/info.txt /output"); System.exit(1); } // 每一次的执行实际上都属于一个作业(Job),但是现在希望通过初始化参数来设置HDFS的文件存储的路径 // 假设现在的文件保存在HDFS上的"/input/info.txt"上,而且最终的输出结果也将保存在HDFS的"/output"目录中 Configuration conf = new Configuration() ;//进行相关配置使用 //考虑到最终需要使用HDFS进行内容的处理操作,并且输入的时候不带有HDFS地址 String [] argArray = new GenericOptionsParser(conf, args).getRemainingArgs();//对输入的参数进行处理 //后面就需要通过作业进行处理了,而且Map与Reduce操作必须通过作业来进行配置 Job job = Job.getInstance(conf,"hadoop");//定义一个Hadoop的作业 job.setJarByClass(WordCount.class);//设置执行的jar文件的程序类 job.setMapperClass(WordCountMapper.class);//指定Mapper的处理类 job.setMapOutputKeyClass(Text.class);//设置输出的Key的类型 job.setMapOutputValueClass(IntWritable.class);//设置输出的value类型 job.setReducerClass(WordCountReducer.class);//设置reduce操作的处理类 //随后需要设置Map-Reduce最终的执行结果 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //设置输入以及输出路径 FileInputFormat.addInputPath(job,new Path(argArray[0])); //设置输入路径 FileOutputFormat.setOutputPath(job, new Path(argArray[1]));//设置输出路径 //等待执行完毕 System.exit(job.waitForCompletion(true) ? 0:1); //执行完毕后退出 } }
下面需要将程序打包成jar文件,名称就为yootk.jar,在进行jar文件导出的时候需要设置一个主类名称

随后利用ftp将yootk.jar文件上传到Linux服务器中
在hdfs上建立一个input文件夹,同时将保存一个文件到此文件夹之中
启动服务start-all.sh,通过jps确定6个进程都在,服务配置正常
root@hadoopm:/home/shawnee/local/hadoop/input# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [hadoopm] hadoopm: starting namenode, logging to /home/shawnee/local/hadoop/logs/hadoop-root-namenode-hadoopm.out hadoopm: starting datanode, logging to /home/shawnee/local/hadoop/logs/hadoop-root-datanode-hadoopm.out Starting secondary namenodes [hadoopm] hadoopm: starting secondarynamenode, logging to /home/shawnee/local/hadoop/logs/hadoop-root-secondarynamenode-hadoopm.out starting yarn daemons starting resourcemanager, logging to /home/shawnee/local/hadoop/logs/yarn-root-resourcemanager-hadoopm.out hadoopm: starting nodemanager, logging to /home/shawnee/local/hadoop/logs/yarn-root-nodemanager-hadoopm.out root@hadoopm:/home/shawnee/local/hadoop/input# jps 6112 DataNode 6896 Jps 6583 NodeManager 5959 NameNode 6460 ResourceManager 6302 SecondaryNameNode root@hadoopm:/home/shawnee/local/hadoop/input#
范例:在hdfs上创建一个input的文件目录
root@hadoopm:/home/shawnee/local/hadoop/input# hadoop fs -mkdir /input
查看创建是否成功
root@hadoopm:/home/shawnee/local/hadoop/input# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2018-06-19 00:07 /input
范例:建立一个文件,直接利用vi处理
root@hadoopm:/home/shawnee/local/hadoop/input# vi mldn.txt
Hello MLDN Hello Yootk
Hello Bye Bye Bye
Hello MLDN
范例:将此文件保存到HDFS中的"/input"目录之中
root@hadoopm:/home/shawnee/local/hadoop/input# hadoop fs -put mldn.txt /input/
查看文件内容以确定是否成功推送
root@hadoopm:/home/shawnee/local/hadoop/input# hadoop fs -cat /input/mldn.txt
Hello MLDN Hello Yootk
Hello Bye Bye Bye
Hello MLDN
随后要进入到yootk.jar文件所在的路径,执行jar文件
root@hadoopm:/home/shawnee/local/hadoop/input# cd /srv/ftp
root@hadoopm:/srv/ftp# ll
total 20
drwxrwxrwx 3 root ftp 4096 Jun 18 02:14 ./
drwxr-xr-x 3 root root 4096 May 26 23:34 ../
drwxrwxrwx 2 ftp ftp 4096 May 27 01:19 .cache/
-rw------- 1 ftp ftp 5193 Jun 18 09:13 yootk.jar
root@hadoopm:/srv/ftp# hadoop jar yootk.jar /input/mldn.txt /output
执行的时候需要保证output目录在HDFS上不存在
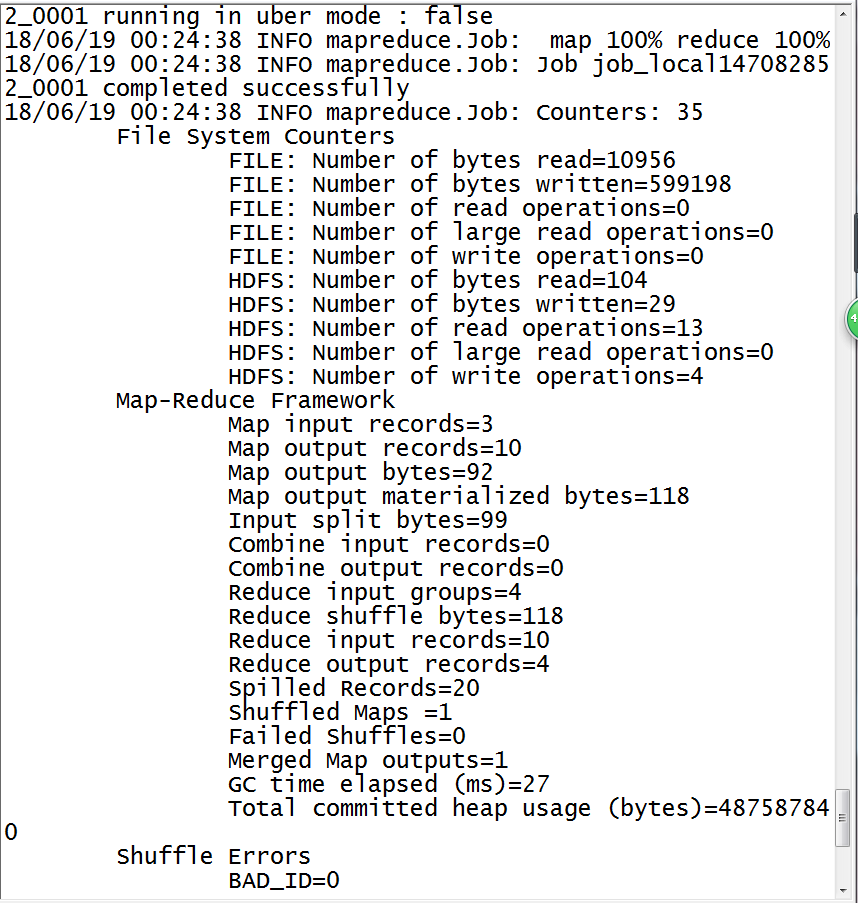
这样的结果表示作业执行完毕
而后可以查看在HDFS中/output目录下的内容
root@hadoopm:/srv/ftp# hadoop fs -ls /output
Found 2 items
-rw-r--r-- 1 root supergroup 0 2018-06-19 00:24 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 29 2018-06-19 00:24 /output/part-r-00000
范例:查看输出的文件内容
root@hadoopm:/srv/ftp# hadoop fs -cat /output/part-r-00000
Bye 3
Hello 4
MLDN 2
Yootk 1