爬网演练代码1:
import requests from bs4 import BeautifulSoup url = 'https://www.cnblogs.com/exesoft/p/13184331.html' r = requests.get(url, timeout=30) r.encoding = 'utf-8' soup = BeautifulSoup(r.text, "html.parser") trs = soup.select('.exesoft-table tr') print(type(trs)) print(trs) print("------------------------") for tr in trs: print(tr) print("---------------") tds=tr.find_all('td') print(tds) print("---------") for td in tds: print(td.string) print("----")
爬网演练代码2:上述代码的改良版
import requests from bs4 import BeautifulSoup allStudents = [] def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fillStudentsList(soup): data = soup.select('.exesoft-table tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleStudent = [] for td in ltd: singleStudent.append(td.string) allStudents.append(singleStudent) def printStudentsList(): print(allStudents) print("{} {} {}".format("编号","姓名","分数")) for i in range(5): u=allStudents[i] print("{} {} {}".format(u[0],u[1],u[2])) def main(): url = 'https://www.cnblogs.com/exesoft/p/13184331.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") fillStudentsList(soup) printStudentsList() main()
代码运行效果:
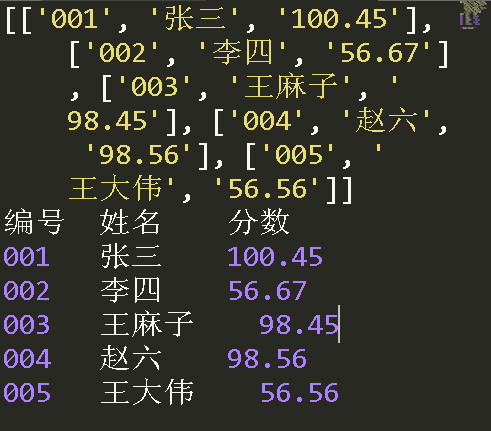
小结:
爬网可以看成一个"剥蒜"过程.最终的目标是要获取一个带有少量皮的蒜,还是一颗纯净的蒜,这个由业务需求决定。由于爬网得来的数据结构列表居多,所以可以通过循环结构层层剥离外面的包装(即:Html标签),得到相应的数据。