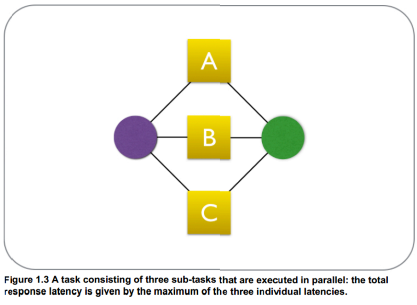
之前在想如何降低API的延迟,这些API里有几个比较耗时的操作且是串行执行,那通过异步执行的方式理论上可以降低运行的时间,如下图所示:
具体的实现比较简单,例如这样:
public class ParallelRetrievalExample {
final CacheRetriever cacheRetriever;
final DBRetriever dbRetriever;
ParallelRetrievalExample(CacheRetriever cacheRetriever,
DBRetriever dbRetriever) {
this.cacheRetriever = cacheRetriever;
this.dbRetriever = dbRetriever;
}
public Object retrieveCustomer(final long id) {
final CompletableFuture<Object> cacheFuture =
CompletableFuture.supplyAsync(() -> {
return cacheRetriever.getCustomer(id);
});
final CompletableFuture<Object> dbFuture =
CompletableFuture.supplyAsync(() -> {
return dbRetriever.getCustomer(id);
});
return CompletableFuture.anyOf(
cacheFuture, dbFuture);
}
用java8引入的CompletableFuture即可。
这里不再赘述。
主要讲一下这样实践遇到的坑和一些自己的理解。
性能测试
优化后的代码需要和未修改(基准)的版本做比较,要考虑在不同负载下的性能情况。
针对API的修改可以使用AB工具,比较方便,能通过设定不同的并发用户模拟不同的负载。
测试是必要的,很多直觉上会提高性能的点可能会在实际表现上收到资源的限制等原因无法提高甚至不如优化前的性能。
适合处理的任务 & 线程池的设定
我们要优化怎样的任务呢?
任务也就三大分类,计算密集,IO密集和混合,其中混合里面也可以通过细化变为前两类。
在一般的web开发中计算不太会成为瓶颈,主要是IO。
一些耗时的阻塞IO操作(数据库,RPC调用)往往是导致接口慢的原因,这里要优化的就是这类操作。
不过与其说是优化,更恰当的说法是让这些阻塞操作异步化,缩短整体的时间,这里也要注意这些任务所在的位置,如果在API的最后面的逻辑里那优化他们也没什么必要,或者在不影响业务逻辑的情况下可以把他们置前。
我们需要的怎样的线程池?
如上所说要优化的任务几乎都是阻塞IO,也就意味着这些任务占用CPU的时间很短,主要是处在waiting状态下,这种线程的增加最大的开销就是内存,对上下文切换影响较小。
其次,线程数必定要有限,java的线程过于重量,不考虑CPU因素也需要考虑内存因素。
最后还要考虑线程池耗尽的情况,最差的情况是回到没优化之前,也就是在调用者线程上执行。
CompletableFuture的runAsync和supplyAsync方法有不带Executor的版本,首先看一下默认的线程池是否合适。
private static final Executor asyncPool = useCommonPool ?
ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
useCommonPool的判断是根据ForkJoinPool的并行度,可以简单地先认为多核下会返回true(也可以通过java.util.concurrent.ForkJoinPool.common.parallelism参数进行设定)。
而使用的commonPool()线程数量不是很多(默认和CPU核数相等),其次ForkJoinPool是设计用于短任务的运行,不适合做阻塞IO,我们要优化的主要慢操作几乎都是阻塞IO带来的。
接下去看需求比较接近的Executors.newFixedThreadPool,但通过实现不难发现他的队列是无界的,如果线程耗尽新的任务就会等待,也无法使用拒绝策略。
只有定制了,根据上面说到的需求,定制如下:
private static final ThreadPoolExecutor IO = new ThreadPoolExecutor(20, 20, 0, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
new CallerRunsPolicy());
线程数量定长,数量的多少可以根据测试情况做下调整,使用SynchronousQueue不产生队列,拒绝策略使用在调用者线程上运行,满足了所需。
这个线程池专门为IO密集任务使用,不要让计算密集的代码使用。
在实践中遇到了使用这种方式结果测试时性能降低了5倍左右的情况,一看代码中除了从数据库获取数据还有几个for循环在做修改字段的工作,导致上下文切换带来了很大的开销。
思考
上述实现中,限制线程数量的原因是因为线程的开销(这里主要是在内存上)过大,这就意味着在这里使用了线程过重了,更好的实现应该使用类似绿色线程的技术,和系统线程进行1对多的映射。
此外这种场景下用事件驱动的方式可能会更好。
追究其核心原因还是java世界中同步阻塞操作还是占多数,而主要的优化手段底层还是使用了昂贵的线程,一些在其他语言/平台上很容易实现的扩展在java上就会遇到问题。
此外,异步没有得到语言上的支持,造成异步编程在java上比较麻烦和显式,这点C#的async和await语法糖就要甜的多。
java之后的发展还是任重而道远啊。
参考资料
reactive design pattern 上述的图和ParallelRetrievalExample代码取自这里