设定项目文件大致结构
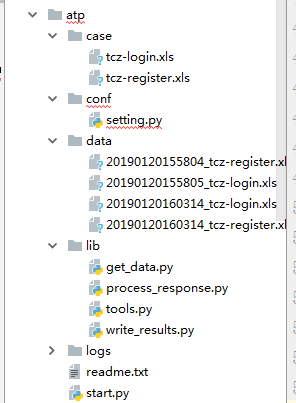
-
atp/: 项目名 -
conf/:存放配置文件
-
data/:存放sql文件
-
lib/: 存放项目的所有源代码。 -
logs/:存放日志文件
-
uploads/:存放下载的文件
-
start.py: 程序启动脚本 -
readme.txt: 项目说明文件。 - case/:存放用例表
理清思路
基本思想与原则A:
数据很多,就放到一个列表或字典里;
用for语句,处理一条数据即可。
基本思想与原则B:
考虑是否传参,如何传参。
一般把要处理的对象作为参数传入。
1.有多个用例表,取所有的表到一个大列表d_all_excel中。for循环,处理一个表abs_excel先。
d_all_excel = glob.glob(os.path.join(case_path,'*.xls'))
2..一个表中有多条用例,取表中的用例到一个大列表中all_cases中.
(表的读写)
# all_cases = [[url,method,data:dict,check],[url,method,data:dict,check],...] ;
book = xlrd.open_workbook(abs_excel)
sheet = book.sheet_by_index(0)
for case in range(1,nrows):all_cases.append(sheet.row_values(i)[4:8])
3.用例数据处理:for循环,处理一条用例case先。
case作为参数入参。case = [url,method,data:dict,check]
序列解包;
url需要拼接为完整的接口地址: url = urljoin(server_url,url)
难点:data不仅要参数化: for p,func in func_map.items(): if p in data: data.replace(p,func())
func_map = {
'<phone>': f.phone_number, #生成电话的
'<ssn>': f.ssn,
'<email>': f.email,
'<name>': f.name,
'<username>': f.user_name,
'<bank_no>': f.credit_card_number,
'<password>': f.password,
'<addr>': f.address
} #这儿的f是faker.Faker()
data还要取成字典:
4.访问接口,拿到返回数据response和res_reason, satate('成功,失败')。
分get和post,需要传参url,data,header. 后俩个不是必传参数,可以默认为None;
没返回数据时,拿不到json, 处理下异常;
5.难点:校验返回的数据和预期结果。 检查点 如 erron = 2001
根据预测数据检查点的key,来获取实际返回数据的rea_value;
(jsonpath模糊匹配)
[key,seq,value]
code = '%s %s %s'%(self.convert_type(real_value),seq,self.convert_type(value)) #生成比较实际结果和语气结果的代码
status = eval(code) #用eval来执行生成代码,获取到执行的结果
将预测数据检查点的value,用其运算符,与rea_value比较。所有检查点都True即成功。
注意:nt和float不能比较。字符不加引号,就是变量,变量不能比较。try except
6.将校验结果写入表中。
列表数据写入表格;
表格存放到data里,避免与case混一起。
7.将表通过邮件发送。
处理下异常,网不好等很容易失败
8.串通好流程。
9.提高效率,单线程和多线程