sklearn神经网络分类
神经网络学习能力强大,在数据量足够,隐藏层足够多的情况下,理论上可以拟合出任何方程。
理论部分
sklearn提供的神经网络算法有三个:
neural_network.BernoulliRBM,neural_network.MLPClassifier,neural_network.MLPRgression
我们现在使用MLP(Multi-Layer Perception)做分类,回归其实也类似。该网络由三部分组成:输入层、隐藏层、输出层,其中隐藏层的个数可以人为设定。神经网络学习之后的知识都存在每一层的权重矩阵中,学习的过程也就是不断训练权重达到拟合的效果。权重训练比较常用的方法是反向传递(Backpropagation)

分类代码
#coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.neural_network import MLPClassifier
import numpy as np
from sklearn.preprocessing import StandardScaler
def main():
iris = datasets.load_iris() #典型分类数据模型
#这里我们数据统一用pandas处理
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data['class'] = iris.target
#这里只取两类
data = data[data['class']!=2]
#为了可视化方便,这里取两个属性为例
scaler = StandardScaler()
X = data[['sepal length (cm)','sepal width (cm)']]
scaler.fit(X)
#标准化数据集
X = scaler.transform(X)
Y = data[['class']]
#划分数据集
X_train, X_test, Y_train, Y_test =train_test_split(X, Y)
mpl = MLPClassifier(solver='lbfgs',activation='logistic')
mpl.fit(X_train, Y_train)
print 'Score:
',mpl.score(X_test, Y_test) #score是指分类的正确率
#区域划分
h = 0.02
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = mpl.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
#做出原来的散点图
class1_x = X[Y['class']==0,0]
class1_y = X[Y['class']==0,1]
l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])
class2_x = X[Y['class']==1,0]
class2_y = X[Y['class']==1,1]
l2 = plt.scatter(class2_x,class2_y,color='r',label=iris.target_names[1])
class3_x = X[Y['class']==2,0]
class3_y = X[Y['class']==2,1]
l3 = plt.scatter(class3_x,class3_y,color='g',label=iris.target_names[2])
plt.legend(handles = [l1, l2,l3], loc = 'best')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()
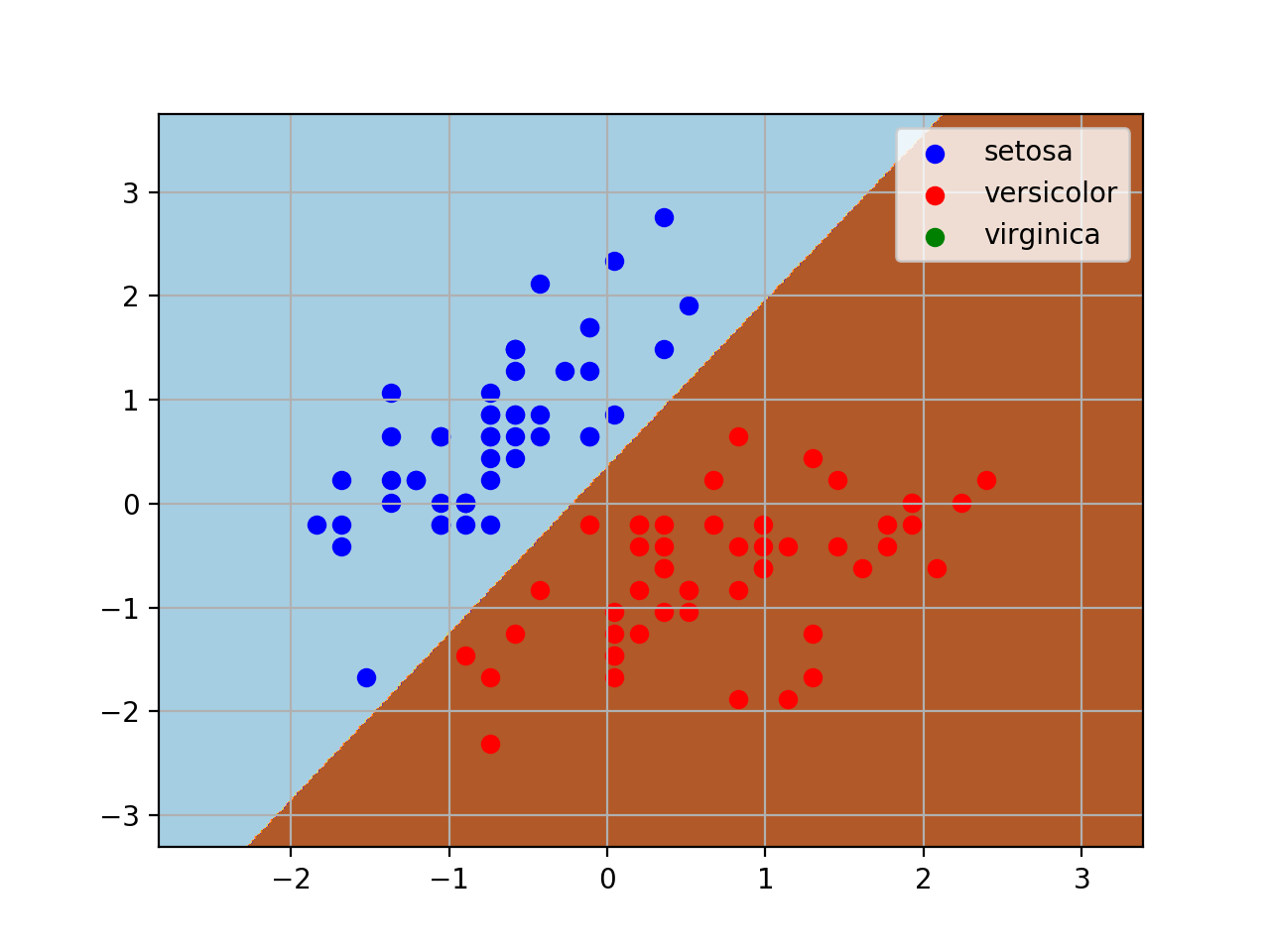
测试结果