R-CNN for Small Object Detection
文章方法概括
- 这篇文章主要讨论针对小目标的目标检测
- 文章为了证明:对传统R-CNN style的方法进行改进,可以用于小目标检测,并且性能比DPM方法好
- 整个检测流程
- 用改进版的RPN(修改了anchor的尺度,称为modified RPN)提取候选区域
- 用改进版的CNN(结合了上下文信息的CNN模型,base的CNN可以用AlexNet或者VGG,称为ContextNet)对候选区域进行分类,不做Box Regression
文章创新点和贡献
-
这篇文章从三个角度对比了小目标检测的方法:
- 候选区域生成:传统RPN vs. modified RPN(更好)
- 上采样策略:上采样比例小 + 去掉全连接 vs. 上采样比例大 + 保留全连接(更好)
- 是否使用上下文信息:不实用上下文 vs. 使用上下文(更好)
- 这篇文章的贡献在于:
- 提出了一个专门针对于小目标的目标检测benchmark库
- 提出了一个把传统R-CNN方法进行改进用于小目标检测的思路和流程
- 小目标检测的难点:
- 一张图中小目标比大目标往往更多
- 小目标的像素少(信息少)
- 目前针对小目标的研究非常有限,大部分文献都是针对VOC库中的大目标
文章方法和细节
- 小目标benchmark库的建立
- 小目标的定义
- 现实生活中的目标的物理大小相对较小,比如,鼠标,插孔,盘子等等,即实际大小也比较小
- 在图像中所占整张图像的比例小
- 小目标的定义

- 大库(包含大、小目标)如何做成小库(仅包含小目标)
- 使用Microsoft COCO和SUN库的子集
- 只挑选了10类(Mouse,Telephone,Switch,Outlet,Clock,Toilet paper,Tissue box,Faucet,Plate,Jar)
- 去掉10类中目标比较大的(即使是鼠标类,在有的图像中鼠标也很大,把这些样本去掉)
- 数据库大小
- 4295张图像,8393个目标(train:test = 2:1)
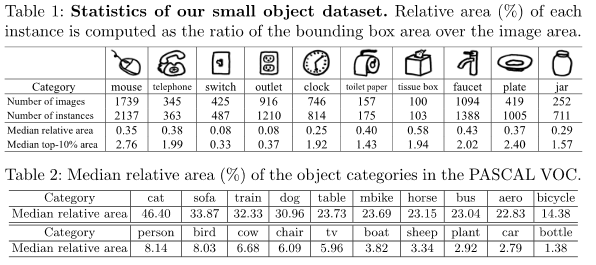
- relative area即相对面积 = Area(Bounding box of the object) / Area(image)
- 小目标的相对面积(relative area)的中位数(media relative area) 分布在0.08%~0.58%(约16*16~42*42像素)
- 一般的大目标的media relative area 分布在1.38%~46.4%
- 具体的类别,图像数,相对面积分布如下表
- 评估标准(mAP,和普通的多类目标检测一样)
- 单类的PR曲线(调整IOU的阈值)
- 单类的average precision:(PR曲线求积分,面积)
- 多类的mAP:每类的average precision直接取平均
针对R-CNN style方法进行修改得到小目标检测方法和流程
- 候选区域生成
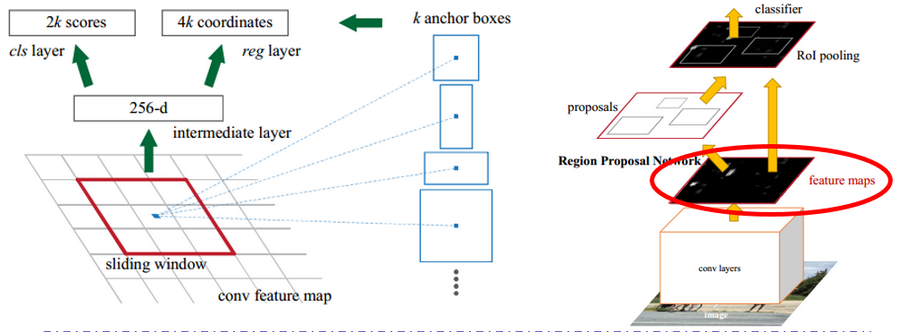
- 本文方法(modified RPN):普通的RPN修改了anchor大小 + feature map选择
- anchor大小修改: 128^2,256^2,512^2 → 16^2,40^2,100^2
- feature map选择:conv5 → conv4_3
- 初始RPN的anchor和流程如下:
- 拿来对比的两种方法:DPM(据说在R-CNN出现之前最好的方法,HOG+SVM),原始的RPN(用来检测大目标的)
- 实验结果对比:

- 实验结论:修改anchor尺度(modefied RPN)比DPM好,比原始RPN好
- 本文方法(modified RPN):普通的RPN修改了anchor大小 + feature map选择
- 上采样策略
- 本文方法(Full AlexNet):直接把modefied RPN得到的候选区域resize成分类要用的CNN的原始输入图像(Alexnet是227,VGG是224)
- 对比方法(Partial AlexNet):把候选区域resize成67*67,输入到分类要用的CNN(因为AlexNet和VGG有全连接层,所以只能处理固定成规定大小的图像,但是如果把全连接层去掉,只取卷积层,就能处理大小和规定的固定大小不一样的输入图像),最后连接分类层
- 实验对比结果:
- 因为候选区域的大小很小,如果用Full AlexNet(全连接层),则必须resize成227或者224,都是放大了好几倍,所以作者考虑这样的放大可能引入了artificats,这个部分的实验就是在证明即使这样的放大效果也比不用整个网络仅使用全卷积层得到的效果更好。
- 作者认为,第一因为输入图像大小变小了,所以相同的感受野大小(网络结构相同)对小图而言,可能就是对应了原图的很大部分,属于coarse的scale,而对于大图,因为只对应原图的一小部分,所以更加fine,细节更多,信息更丰富
- 第二,从得到的特征来看,小图的feature更短,大图的feature更长(只考虑卷积层)
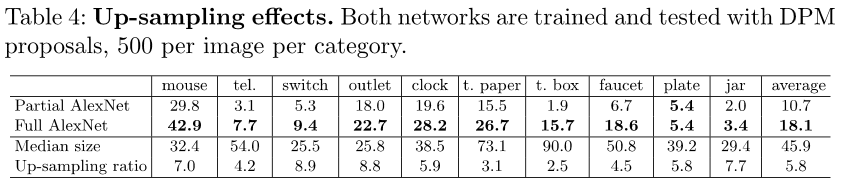
- 实验结论:取整个(包括Full Concation层)分类网络(Full AlexNet)比只取卷积部分的网络(Partial AlexNet)好
- 因为候选区域的大小很小,如果用Full AlexNet(全连接层),则必须resize成227或者224,都是放大了好几倍,所以作者考虑这样的放大可能引入了artificats,这个部分的实验就是在证明即使这样的放大效果也比不用整个网络仅使用全卷积层得到的效果更好。
- 上下文信息的结合
-
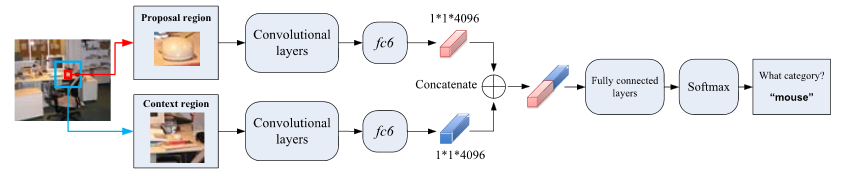
- 本文方法(Context-AlexNet)网络结构如下图:
- 网络结构分为两部分,front-end和back-end
- front-end由两个并行的CNN组成,一个以proposal region直接作为输入,经过6个conv层(Alex或者VGG)+ 1个fc层,得到4096维的特征;另一个以proposal region为中心,在原图上取4倍的proposal region的一个context region作为输入,经过6个conv层 + 1个fc层,得到4096维的特征
- back-end以front-end的两个4096的特征串起来作为输入,经过2个fc层 + 1个softmax层得到每个proposal region的分类信息
- 结构图如下:
- 对比的方法(Baseline AlexNet):普通的AlexNet,没有context信息。另外作者对比了上下文尺度的大小(放大3倍还是7倍)

- 实验结果对比:

- 实验结论:用了上下文(ContextNet)比不用上下文(Baseline AlexNet)好,3倍和7倍差别不大!
- 本文方法(Context-AlexNet)网络结构如下图:
实验结果
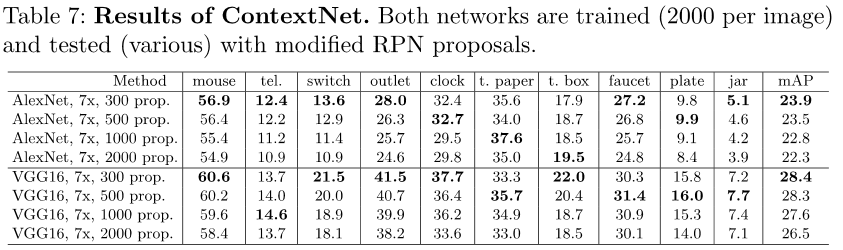
- 最终的mAP上和其他的方法进行对比(比DPM,AlexNet R-CNN,和VGG R-CNN都要好)

- 最终的mAP上AlexNet和VGG的对比(VGG好,层数更深),不同proposal个数对比(取300好,false positive少)
总结
- 做小目标检测的几个思路:专门建立小目标库,对小目标大小进行统计分析,对网络进行修改(卷积核大小,anchor大小),利用目标周围的上下文信息