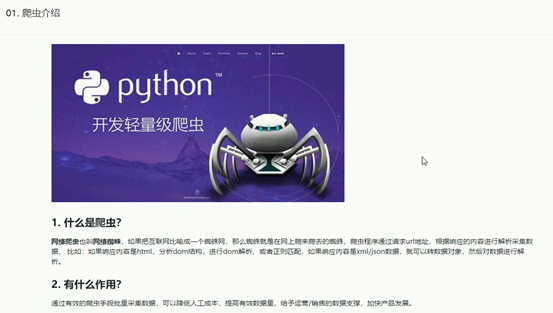
1、爬虫介绍:




2、第一个爬虫程序:
from urllib.request import urlopen url= "http://www.baidu.com" # 记得是http,不是https response = urlopen(url) info = response.read() # 获取内容 # print(info.decode()) # 设置编码,decode()默认是utf-8 print(response.getcode()) # 获得状态码 200 print(response.geturl()) # 获得真实url http://www.baidu.com print(response.info()) # 获得响应头
3、Request请求信息:
from urllib.request import urlopen,Request from random import choice url= "http://www.baidu.com" # 记得是http,不是https User_Agent = [ "User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)", "Opera 11.11 – WindowsUser-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", "User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko)
Chrome/17.0.963.56 Safari/535.11" ] headers= { "User-Agent":choice(User_Agent) # 随机获得User-agent } request = Request(url,headers=headers) print(request.get_header("User-agent")) # 获得请求头的User-agent信息 response = urlopen(request) info = response.read() # 获取内容 print(info.decode()) # 设置编码,decode()默认是utf-8
4、random中choice:
from random import choice from fake_useragent import UserAgent User_Agent = [ "Opera 11.12 – MACUser-Agent:Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11", "Opera 11.11 – WindowsUser-Agent:Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11", "Chrome 17.0 – MACUser-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11" ] c = choice(User_Agent) # 随机获得一个求头 print(c) c= UserAgent() # 随机获得user-agent print(c.chrome) print(c.firefox) print(c.ie)
5、get请求之中文处理:
from urllib.request import urlopen,Request from random import choice from urllib.parse import quote,urlencode # url = "https://www.baidu.com/s?wd=尚学堂" # 这样会出错 # 处理中文:方式一 wd = quote("尚学堂") # url= "https://www.baidu.com/s?wd={}".format(wd) # 处理中文:方式二 args = { "wd":"尚学堂", "id":"11" } url= "https://www.baidu.com/s?wd={}".format(urlencode(args)) # print(url) # https://www.baidu.com/s?wd=wd=%E5%B0%9A%E5%AD%A6%E5%A0%82&id=11 headers= { "User-Agent": "User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)", } request = Request(url,headers=headers) response = urlopen(request) print(response.read().decode())
6、爬取贴吧:
from urllib.request import urlopen,Request from random import choice from urllib.parse import quote,urlencode from fake_useragent import UserAgent def get_html(num,title): base_url = "http://tieba.baidu.com/f?{}" headers = { "User-Agent": UserAgent().random } for pn in range(int(num)): args = { "kw": "尚学堂", "ie": "utf - 8", "pn": pn * 50 } request = Request(url,headers=headers) print("正在爬取") response = urlopen(request) filename = "第"+str(pn)+"页.html" save(filename,response.read()) def save(filename,content): html = content.decode() with open(filename,"wb") as f: f.write(content) def main(): num = input("请输入爬取的页数:") title = input("请输入爬取的题目:") get_html(num,title) # 调用函数 if __name__ == "__main__": main()
7、post请求之登录:
from urllib.request import Request,urlopen from urllib.parse import urlencode url = "https://www.sxt.cn/index/login/login.html" headers = { "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36" } data = { "user": "17703181473", "password": "12346" } # post请求,Request中有data,字典先变成字符串(urlencode),再变成字节(encode) # 必须加encode,变成字节 request = Request(url,data=urlencode(data).encode(),headers=headers) resposne = urlopen(request) print(resposne.read().decode())