现有一系列因变量 x0,x1,x2,⋯,xn,和一系列未知参数 θ , logistics 函数可以表示为(可能性):
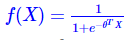 (sigmoid函数)
(sigmoid函数)
这个函数最基础的部分: θTX,参数点积自变量。计算某事发生的可能性,将跟事件有关的特征加权求和。

这个求和的结果在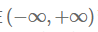 ,为了能得到一个概率预测值,将结果映射到(0,1)之间。这时候就要使用逻辑函数(sigmod)
,为了能得到一个概率预测值,将结果映射到(0,1)之间。这时候就要使用逻辑函数(sigmod)
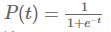
计算出事件的概率之后,如果概率大于0.5就是类别1,小于0.5类别2
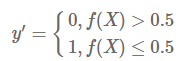
但是问题是:我们不知道参数是什么?怎么求这些参数?
我们要用一系列的权重值逼近训练样例。找到一组最优的解。最优的标准为最小化loss function
loss function 多种多样,最常见的损失函数:
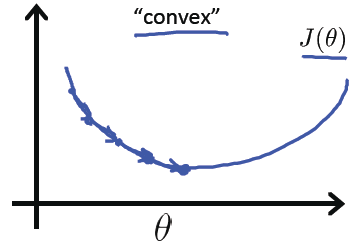
0-1 损失:可用于分类问题,即该函数用于衡量分类错误的数量,但由于此损失函数是非凸(non-convex)的,因此在做最优化计算时,难以求解,所以,正因为如此,0-1损失函数不是那么“实用”(如果这句话有误,请指正)。
凸函数局部最小值为全局最小值。better
平方损失函数:常用于线性回归(Linear Regression)
对数损失(Log Loss)函数:常用于其模型输出每一类概率的分类器(classifier),例如逻辑回归。也常被称为:交叉熵损失函数,熵用来表示不可预测性,交叉熵=真实分布+不可预测性。
其中, yi 是第i个真实值( yi∈{0,1} ), y^i 是第i个预测值。将yi带入:
直观的来解释这个Cost Function,首先看当y=1的情况:
直观来看, 如果y = 1,
,则Cost = 0,也就是预测的值和真实的值完全相等的时候Cost =0;
但是,当
时,
直观来看,由于预测的结果南辕北辙:
如果
因此对于这个学习算法给予一个很大的Cost的惩罚。
同理对于y=0的情况也适用:
因此,我们只要找到一个参数向量 θ ,能使得此式的值最小,那么这个参数向量 θ 就是“最优”的参数向量。
hinge 损失函数:常用于SVM(Support Vector Machine,支持向量机,一种机器学习算法)。中文名叫“合页损失函数”,因为hinge有“合页”之意。这个翻译虽然直白,但是你会发现,99%的文章都不会用它的中文名来称呼它,而是用“Hinge损失”之类的说法。

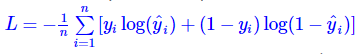
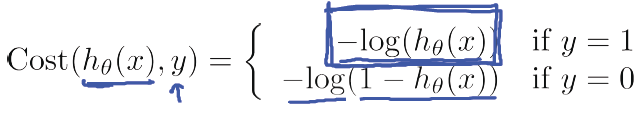
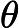
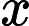

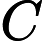

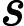


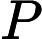
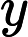

已知了目标函数,怎么求解目标函数:
梯度下降求解:
目标是最小化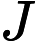
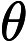
 ,则梯度下降算法的如下:
,则梯度下降算法的如下:
对于多类分类问题:分别计算其中一类相对于其他类的概率: