Scrapy框架介绍
什么是scrapy框架?
Scrapy框架是封装了很多功能并具有很强的通用性的爬虫框架。
Scrapy框架的功能
- 高性能的持久化存储
- 异步的数据下载
- 高性能的数据解析
- 分布式应用
Scrapy框架的基本使用
环境安装:
- linux & Mac:pip install scrapy
- Window:
- pip install wheel : 负责处理twisted模块
- 下载安装twisted
- $: pip install pywin32
- $: pip install scrapy
基本使用:
1、创建Scrapy工程:
$: scrapy startproject ProjectName # ProjectName为工程名
2、在spiders子目录中创建一个爬虫文件:
$ : scrapy genspider spidername www.xxx.com # spidername为爬虫文件名 # www.xxx.com 为爬虫文件中的 url , 后续可在爬虫文件中修改
3、执行项目:
$ : scrapy crawl spidername # spidername为爬虫文件名
根据上述步骤执行后,得到如下层级的项目:
创建以项目之后,Scrapy会自动生成一下文件
- spiders:用以存放所有的爬虫文件
- items.py: 自定义处理item对象的类
- middlewares.py:用于存放中间件
- pipelines.py:管道类文件,用于封装处理item对象的管道类
- settings.py: Scrapy项目的配置文件
- scrappy.cfg: Scrapy的配置文件
来看下爬虫文件中的代码:
# -*- coding: utf-8 -*- import scrapy class FirstSpiderSpider(scrapy.Spider): # name:爬虫文件的名称,也是爬虫文件的唯一标识, name = 'first_spider' # 允许发起请求的域名,用来限制 start_urls 列表中的哪些url可以发起请求 一般不适用 allowed_domains = ['www.baidu.com'] # 起始的url列表,列表中的url会被scrapy自动进行请求的发送 start_urls = ['http://www.baidu.com/'] def parse(self, response): ''' 用来解析数据的方法 :param response: 请求url返回的响应 :return: 返回解析的结果 ''' print(response)
这里对Parse方法进行了修改,让其打印response,现在执行项目看下:


(venv) kylin@kylin:~/PycharmProjects/Crawler/Scrapy框架/firstspider$ scrapy crawl first_spider 2020-05-28 12:56:10 [scrapy.utils.log] INFO: Scrapy 2.1.0 started (bot: firstspider) 2020-05-28 12:56:10 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.6.9 (default, Apr 18 2020, 01:56:04) - [GCC 8.4.0], pyOpenSSL 19.1.0 (OpenSSL 1.1.1g 21 Apr 2020), cryptography 2.9.2, Platform Linux-5.3.0-51-generic-x86_64-with-Ubuntu-18.04-bionic 2020-05-28 12:56:10 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor 2020-05-28 12:56:10 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'firstspider', 'NEWSPIDER_MODULE': 'firstspider.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['firstspider.spiders']} 2020-05-28 12:56:10 [scrapy.extensions.telnet] INFO: Telnet Password: 644fdd2de863d7ee 2020-05-28 12:56:10 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.memusage.MemoryUsage', 'scrapy.extensions.logstats.LogStats'] 2020-05-28 12:56:10 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2020-05-28 12:56:10 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2020-05-28 12:56:10 [scrapy.middleware] INFO: Enabled item pipelines: [] 2020-05-28 12:56:10 [scrapy.core.engine] INFO: Spider opened 2020-05-28 12:56:10 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2020-05-28 12:56:10 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2020-05-28 12:56:10 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/robots.txt> (referer: None) 2020-05-28 12:56:10 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://www.baidu.com/> 2020-05-28 12:56:11 [scrapy.core.engine] INFO: Closing spider (finished) 2020-05-28 12:56:11 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/exception_count': 1, 'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1, 'downloader/request_bytes': 223, 'downloader/request_count': 1, 'downloader/request_method_count/GET': 1, 'downloader/response_bytes': 676, 'downloader/response_count': 1, 'downloader/response_status_count/200': 1, 'elapsed_time_seconds': 0.280637, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2020, 5, 28, 4, 56, 11, 68667), 'log_count/DEBUG': 2, 'log_count/INFO': 10, 'memusage/max': 54968320, 'memusage/startup': 54968320, 'response_received_count': 1, 'robotstxt/forbidden': 1, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2020, 5, 28, 4, 56, 10, 788030)} 2020-05-28 12:56:11 [scrapy.core.engine] INFO: Spider closed (finished) (venv) kylin@kylin:~/PycharmProjects/Crawler/Scrapy框架/firstspider$ clear (venv) kylin@kylin:~/PycharmProjects/Crawler/Scrapy框架/firstspider$ scrapy crawl first_spider 2020-05-28 12:56:54 [scrapy.utils.log] INFO: Scrapy 2.1.0 started (bot: firstspider) 2020-05-28 12:56:54 [scrapy.utils.log] INFO: Versions: lxml 4.5.0.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 20.3.0, Python 3.6.9 (default, Apr 18 2020, 01:56:04) - [GCC 8.4.0], pyOpenSSL 19.1.0 (OpenSSL 1.1.1g 21 Apr 2020), cryptography 2.9.2, Platform Linux-5.3.0-51-generic-x86_64-with-Ubuntu-18.04-bionic 2020-05-28 12:56:54 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.epollreactor.EPollReactor 2020-05-28 12:56:54 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'firstspider', 'NEWSPIDER_MODULE': 'firstspider.spiders', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['firstspider.spiders']} 2020-05-28 12:56:54 [scrapy.extensions.telnet] INFO: Telnet Password: 6302078d359db2f4 2020-05-28 12:56:54 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.memusage.MemoryUsage', 'scrapy.extensions.logstats.LogStats'] 2020-05-28 12:56:54 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware', 'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] 2020-05-28 12:56:54 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] 2020-05-28 12:56:54 [scrapy.middleware] INFO: Enabled item pipelines: [] 2020-05-28 12:56:54 [scrapy.core.engine] INFO: Spider opened 2020-05-28 12:56:54 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min) 2020-05-28 12:56:54 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023 2020-05-28 12:56:54 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/robots.txt> (referer: None) 2020-05-28 12:56:54 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://www.baidu.com/> 2020-05-28 12:56:55 [scrapy.core.engine] INFO: Closing spider (finished) 2020-05-28 12:56:55 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/exception_count': 1, 'downloader/exception_type_count/scrapy.exceptions.IgnoreRequest': 1, 'downloader/request_bytes': 223, 'downloader/request_count': 1, 'downloader/request_method_count/GET': 1, 'downloader/response_bytes': 676, 'downloader/response_count': 1, 'downloader/response_status_count/200': 1, 'elapsed_time_seconds': 0.236715, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2020, 5, 28, 4, 56, 55, 143621), 'log_count/DEBUG': 2, 'log_count/INFO': 10, 'memusage/max': 55033856, 'memusage/startup': 55033856, 'response_received_count': 1, 'robotstxt/forbidden': 1, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2020, 5, 28, 4, 56, 54, 906906)} 2020-05-28 12:56:55 [scrapy.core.engine] INFO: Spider closed (finished)
设置打印信息
由于settings.py中设置 # Obey robots.txt rules ROBOTSTXT_OBEY = True ,所以在上面的结果中不会得到response
这个参数的作用是设定是否遵从”rebots.text“协议,为“True”代表遵循,爬虫文件就无法获得对应的数据,反之亦然
设置为" False "后,就可以在日志DEBUG中看到结果:
2020-05-28 13:03:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.baidu.com/> (referer: None)
<200 http://www.baidu.com/>
如何只让其打印response呢?可以在执行代码后加上“nolog”参数:
(venv) kylin@kylin:~/PycharmProjects/Crawler/Scrapy框架/firstspider$ scrapy crawl first_spider --nolog <200 http://www.baidu.com/> (venv) kylin@kylin:~/PycharmProjects/Crawler/Scrapy框架/firstspider$
这中方式有个弊端,那就是如果爬虫代码出现问题,就不会打印处错误信息,只会返回空。
所以有个更好的方式来实现这个效果:修改parse中的代码
def parse(self, response): print(response1) # 在response后价格“1”
在settings.py中设置打印日志级别:
# 设置打印的日志级别 LOG_LEVEL = "ERROR"
再次执行结果:
(venv) kylin@kylin:~/PycharmProjects/Crawler/Scrapy框架/firstspider$ scrapy crawl first_spider 2020-05-28 13:08:47 [scrapy.core.scraper] ERROR: Spider error processing <GET http://www.baidu.com/> (referer: None) Traceback (most recent call last): File "/home/kylin/PycharmProjects/Crawler/venv/lib/python3.6/site-packages/twisted/internet/defer.py", line 654, in _runCallbacks current.result = callback(current.result, *args, **kw) File "/home/kylin/PycharmProjects/Crawler/Scrapy框架/firstspider/firstspider/spiders/first_spider.py", line 19, in parse print(response1) NameError: name 'response1' is not defined
通常情况下,第二种方式用的较多
Scrapy框架数据解析
xpath解析:
在Scrapy中response可以直接调用xpath解析,用法大体上和etree中的差不多,不同的是Scrapy中xpath返回的是以Selector对象为元素的列表。
<Selector xpath='./div[1]/a[2]/h2/text()' data=' 小恩的老公8 '>
每一个Selector对象中,包含两个属性:
- xpath表达式:对应标签的xpath
- data数据:存放对应标签的文本内容
获取Selector数据
在局部解析中,可以调用对应的方法获取Selector对象中data的数据
- extract():
- 调用对象:Selector列表 / Selector对象
- Selector列表调用:将每个Selector对象中data的数据以列表的形式返回
- Selector对象调用:直接将data中的数据以字符串的形式返回
- extract_first():
- 调用对象:Selector列表 (仅当列表中只有一个元素时方可调用)
- 返回结果:直接将data中的数据以字符串的形式返回
''' extract()方法调用: 返回Selector对象中data的属性值 Selector对象调用: div.xpath('./div[1]/a[2]/h2/text()')[0].extract() Selector对象列表调用: list: [<Selector xpath='./div[1]/a[2]/h2/text()' data=' 天热打鼓球 '>] extract_first()方法: 仅在列表中只有一个Selector对象时,返回结果同 extract() '''
Scrapy框架的持久化存储
方式一:基于终端指令存储
- 只可以将prase中返回的数据存储到本地的文本文件中
- 指令: scrapy crawl spidername -o filepath
- 优势:便捷高校、
- 劣势:只能存储到特定的文件类型中:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
示例:
爬虫文件:
def parse(self, response): div_lists = response.xpath('//*[@id="content"]/div/div[2]/div') # print(div_lists) # //*[@id="content"]/div/div[2] //*[@id="qiushi_tag_123151102"]/div[1]/a[2]/h2 all_data = [] # 存储所有数据 for div in div_lists: author_name = div.xpath('./div[1]/a[2]/h2/text()')[0].extract() content = div.xpath('./a[1]/div/span[1]//text()').extract()
# 将列表转为字符串 content = "".join(content)
dic = { "author": author_name, "content": content, } all_data.append(dic) return all_data
执行命令: scrapy crawl qiushi_spider -o qiushi.xml
结果图示:
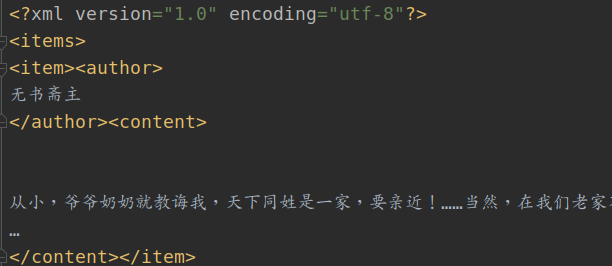
方式二:基于管道存储
编码流程:
- 数据解析
- 在item类中定义相关的属性
- 将解析的数据封装存储到item类型的对象中
- 将item对象提交给管道进行持久化存储
- 在管道类的process_item方法中 ,将接收到的item对象中的数据进行持久化存储
- 在配置文件中开启管道
优劣势:
- 优势:通用性强,存储文件没有位置和文件类型限制
- 劣势:相比较终端存储,编码较为繁琐,
案例:
使用上面的爬取的数据,对其代码进行修改
1、对item类定义相关属性
class QiushispiderItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() """ 用以接受爬虫文件发送的数据,并通过指定形式进行封装 """ author = scrapy.Field() content = scrapy.Field()
2、在prase方法中,把数据封装到Item中,并将封装过数据的item对象提交给管道处理
def parse(self, response): div_lists = response.xpath('//*[@id="content"]/div/div[2]/div') for div in div_lists: author_name = div.xpath('./div[1]/a[2]/h2/text()')[0].extract() content = div.xpath('./a[1]/div/span[1]//text()').extract() # 将列表转为字符串 content = "".join(content) # 实例化QiushispiderItem对象 进行数据封装 item = QiushispiderItem() item["author"] = author_name item["content"] = content # 将item对象提交给管道 yield item
3、在管道类中,将接收到的数据进行持久化存储
class QiushispiderPipeline: fp = None # 重写父类open_spider方法 def open_spider(self, spider): """爬虫开始时调用的方法 只在爬虫程序结束时调用一次""" print("开始爬取数据。。。") self.fp = open("qiushi.txt", "w", encoding="utf-8") def process_item(self, item, spider): """用于处理Item对象 """ author = item["author"] content = item["content"] self.fp.write(author + ":" + content + "") return item # 将管道中的数据返回给下一个管道类进行使用 # 重写父类close_spider方法 def close_spider(self, spider): """爬虫结束时调用的方法 只在爬虫程序结束时调用一次""" print("结束爬虫。。") self.fp.close()
注意:
1、每一个管道类对应将item中的数据存储到一种载体上,如果想实现多种处理方式,
可以定义多种管道类,并在settings.py文件中配置新的管道类及其优先级
2、爬虫文件发送的item对象,管道只接受一次,交由优先级高的管道类处理
3、由优先级最高的管道类中的process_item方法处理完数据后 返回item对象,后续的管道类才可以获得item对象
4、在配置文件中开启管道
# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'qiushiSpider.pipelines.QiushispiderPipeline': 300, # 300表示类的优先级数值 数值越小优先级越高 }
5、执行爬虫程序: scrapy crawl qiushi_spider
基于spider的全站数据爬取
上面爬取的都是单个页面的数据,现在我们基于spider爬取全站数据,实现翻页爬取的效果
import scrapy import requests class XiaohuaSpider(scrapy.Spider): name = 'xiaohua' start_urls = ["https://www.58pic.com/tupian/so-800-0-default-0-0-SO-0_10_0_0_0_0_0-0-1.html"] url = "https://www.58pic.com/tupian/so-800-0-default-0-0-SO-0_10_0_0_0_0_0-0-%d.html" page_num = 2 def parse(self, response): div_lists = response.xpath('/html/body/div[4]/div[4]/div[1]/div[@class="qtw-card"]') for div in div_lists: title = div.xpath('./a/div[2]/span[2]/text()')[0].extract() print(title) if self.page_num <= 3: new_url = self.url % self.page_num self.page_num +=1 # 使用scrapy.spiders.Request手动发起请求 url爬取的url callback为要执行的方法 yield scrapy.spiders.Request(url=new_url, callback=self.parse)
请求参数
使用场景:后续请求的url和首次请求的url不在同一个页面,也就是深度爬取
# meta中放置传递的参数 比如 :item对象 yield scrapy.spiders.Request(url=new_url, callback=self.parse, meta={"item":"item"})
Scrapy的图片爬取:ImagesPipeline
Scrapy框架给我们封装了一个管道类:“ImagesPipeline”,专门用于图片处理
ImagesPipeline的使用方法:
- 自定义管道类,然后继承“ImagesPipeline”
- from scrapy.pipelines.images import ImagesPipeline
- 重写父类方法:
- get_media_request() :
- 作用: 对图片url发起请求
- file_path() :
- 作用: 用于设置图片存储位置
- item_completed() :
- 作用:返回item给下一个管道类
- get_media_request() :
- 在settings.py文件中配置自定义管道类
- 在settings.py文件中配置图片路径:IMAGES_STORE = "./filepath"
示例:爬取站长工具的图片
1、数据解析,将图片的URL封装到item对象:
import scrapy from ..items import ZhanzhangItem class TupianSpiderSpider(scrapy.Spider): name = 'tupian_spider' start_urls = ['http://sc.chinaz.com/tupian/'] def parse(self, response): div_lists = response.xpath('//div[@id="container"]/div') for div in div_lists: img_src = div.xpath('./div/a/img/@src2')[0].extract() # 实例化item item = ZhanzhangItem() item["img_src"] = img_src # 将item对象提交给管道类 yield item
2、设置item字段
import scrapy class ZhanzhangItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() img_src = scrapy.Field()
3、自定义管道类,重写父类方法
import scrapy from scrapy.pipelines.images import ImagesPipeline class ImgPipeline(ImagesPipeline): """自定义管道类 继承ImagesPipeline 重写父类方法""" def get_media_requests(self, item, info): """对图片URL发起请求""" yield scrapy.Request(item["img_src"]) def file_path(self, request, response=None, info=None): """设置图片存储路径""" imgName = request.url.split("/")[-1] return imgName def item_completed(self, results, item, info): """返回item对象给后续的管道类""" return item
4、配置文件配置管道类和图片存储路径
# Obey robots.txt rules ROBOTSTXT_OBEY = False # 配置输出日志级别 LOG_LEVEL = "ERROR" # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'zhanzhang.pipelines.ImgPipeline': 300, } # 配置图片存储路径 IMAGES_STORE = "./Img/"
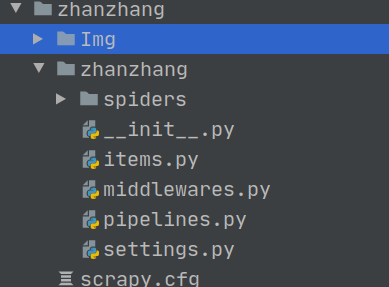
执行爬虫程序,就会看到在根目录生成了一个Img文件夹:
Scrapy的五大核心组件
- 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心)
- 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
- 下载器(Downloader) 用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的)
- 爬虫(Spiders) 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面
- 项目管道(Pipeline) 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
中间件
下载中间件:位于引擎和下载器中间,可以拦截爬虫整个工程中的请求和响应
爬虫中间件:
下载中间件
拦截请求:
- UA伪装:在process_request()方法中实现
- 代理ip设定:在process_exception()方法中实现
拦截响应:
- 修改响应对象和响应数据
UA伪装实现
# UA列表 ua_lists = [ 'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)', 'Mozilla/5.0 (compatible; U; ABrowse 0.6; Syllable) AppleWebKit/420+ (KHTML, like Gecko)', 'Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729)', 'Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser; GTB5; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; SV1; Acoo Browser; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; Avant Browser)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)', 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; GTB5; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; Maxthon; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)', 'Mozilla/4.0 (compatible; Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser 1.98.744; .NET CLR 3.5.30729); Windows NT 5.1; Trident/4.0)', 'Mozilla/4.0 (compatible; Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; GTB6; Acoo Browser; .NET CLR 1.1.4322; .NET CLR 2.0.50727); Windows NT 5.1; Trident/4.0; Maxthon; .NET CLR 2.0.50727; .NET CLR 1.1.4322; InfoPath.2)', 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; Acoo Browser; GTB6; Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1) ; InfoPath.1; .NET CLR 3.5.30729; .NET CLR 3.0.30618)', ] def process_request(self, request, spider): """ 拦截所有正常的请求 :param request: :param spider: :return: 返回response/request/error """ # UA伪装 request.headers["User_Agent"] = random.choice(self.ua_lists) return None
IP代理实现
# 代理ip列表 PROXY_http = [ '223.242.224.37:9999', '175.42.128.136:9999', '112.245.17.202:8080', '27.43.187.191:9999', '183.166.133.235:9999', ] PROXY_https = [ '60.179.201.207:3000', '60.179.200.202:3000', '60.184.110.80:3000', '60.184.205.85:3000', '60.188.16.15:3000', ] def process_exception(self, request, exception, spider): """ 拦截所有的异常请求 :param request: :param exception: :param spider: :return: request 返回请求进行重写发送 """ # 根据URL的请求不同选择不同的代理ip if request.url.split(":")[0] == "http": request.meta["proxy"] = random.choice(self.PROXY_http) else: request.meta["proxy"] = random.choice(self.PROXY_https) return request # 返回请求以便重写发起
基于CrawlSpider进行全站爬取
Scrapy的全站爬取方式:
-
基于Spider:
- 手动请求其他页面
- 基于CrawlSpider
- 通过链接提取器和规则解析器进行请求发和数据提取送
CrawlSpider的用法:
1、创建工程和Spider一样
2、创建爬虫文件:
scrapy genspider -t crawl ProjectName www.xxx.com
来看下创建的爬虫文件的代码:
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class CrawlSpiderSpider(CrawlSpider): name = 'Crawl_spider' allowed_domains = ['www.xxx.com'] start_urls = ['http://www.xxx.com/'] """ LinkExtractor :链接提取器 allow = r"" :根据allow指定的正则规则进行匹配合法的链接 特性:自动去除重复的链接 Rule:规则提取器 根据指定的链接提取器(LinkExtractor)进行链接提取 然后对链接进行指定的规则(callback)解析 LinkExtractor: 肩上 callback: 指定对应的规则对链接进行解析 follow: """ rules = ( Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True), ) def parse_item(self, response): item = {} #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() return item
代码中类的作用初步说明:
LinkExtractor :链接提取器
allow = r"" : 引号为正则表达式,用以匹配对应的链接
根据allow指定的正则规则进行匹配合法的链接
特性:自动去除重复的链接
Rule:规则提取器
根据指定的链接提取器(LinkExtractor)进行链接提取
然后对链接进行指定的规则(callback)解析
LinkExtractor: 肩上
callback: 指定对应的规则对链接进行解析
follow参数:
follow=True:表示”链接提取器“提取到的链接会作为start_urls 将继续被Rule进行循环规则匹配
follow=False:表示仅对start_urls中的链接 做对应的规则匹配
案例: 爬取阳光网投诉的编号、标题、内容
分析:
- 先提取每个页码的链接
- 对每个页面中的编号和标题进行解析提取
- 对每个详情页面的编号和内容进行解析提取
spider文件:
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from ..items import CrawlspiderItem, DetailItem class CrawlSpiderSpider(CrawlSpider): name = 'Crawl_spider' # allowed_domains = ['www.xxx.com'] start_urls = ['http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1'] rules = ( # 对每个页码对应的链接进行提取 Rule(LinkExtractor(allow=r'id=1&page=d+'), callback='parse_item', follow=False), # 新建规则提取器 对每条数据的链接进行提取 Rule(LinkExtractor(allow=r'index?id=d+', ), callback='detail_parse',), ) def parse_item(self, response): """对每一页数据进行解析 提取编号和标题""" li_lists = response.xpath('/html/body/div[2]/div[3]/ul[2]/li') for li in li_lists: first_id = li.xpath('./span[1]/text()').extract_first() title = li.xpath('./span[3]/a/text()').extract_first() item = CrawlspiderItem() item['first_id'] = first_id item['title'] = title yield item def detail_parse(self, response): """对详情页面进行解析 提取编号和内容""" second_id = response.xpath('/html/body/div[3]/div[2]/div[2]/div[1]/span[4]/text()').extract_first() content = response.xpath('/html/body/div[3]/div[2]/div[2]/div[2]/pre/text()').extract() content = "".join(content) item = DetailItem() item['second_id'] = second_id item['content'] = content yield item
由于需要进行两次解析,不可以进行请求传参,两个callback解析的数据不可以存储在同一个”item“中,所以需要创建两个item进行封装数据
item文件:
import scrapy class CrawlspiderItem(scrapy.Item): # define the fields for your item here like: first_id = scrapy.Field() title = scrapy.Field() class DetailItem(scrapy.Item): # define the fields for your item here like: second_id = scrapy.Field() content = scrapy.Field()
管道类对提交过来的item对象,进行区分进而提取对应的数据
pipelines.py
class CrawlspiderPipeline: def process_item(self, item, spider): """ 根据item类型进行对应的item数据提取 """ if item.__class__.__name__ == "CrawlspiderItem": first_id = item["first_id"] title = item["title"] print(first_id,title) else: second_id = item["second_id"] content = item["content"] print(second_id,content) return item