上网简单看了几篇博客
自己试了试简单的爬虫
哎呦喂
很有感觉
蛮好玩的
之前写博客 有点感觉是在写教程啊什么的
写的很别扭
各种复制粘贴
写得很不舒服
以后还是怎么舒服怎么写
把每天的练习
所得
写上来就好了
本来就是个菜鸟
不断学习
不断debug就好
直接上程序:
1 # -*- coding: utf-8 -*- 2 import urllib2 3 import urllib 4 import re 5 6 7 #正则表达式 8 pat = re.compile('img.*?id="bigImg".*?src="(.*?)"') 9 patnext = re.compile('nextPic.*?"(.*?)",') 10 pattotal = re.compile('picTotal.*?(d*),') 11 patnum = re.compile('picNum.*?(d*),') 12 patnextgroup = re.compile('nextGroup.*?"(.*?)",') 13 14 #URL 15 nexturl = "http://desk.zol.com.cn" 16 SerialNumber = ["/bizhi/6195_76529_2.html"] 17 nexturl1 = nexturl + SerialNumber[0] 18 19 20 21 #header 22 def s(nexturl2): 23 myurl = nexturl2 24 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' 25 values = {'username' : 'cqc', 'password' : 'XXXX' } 26 headers = { 'User-Agent' : user_agent } 27 data = urllib.urlencode(values) 28 request = urllib2.Request(myurl, data, headers) 29 myres = urllib2.urlopen(request) 30 return myres 31 32 myres = s(nexturl1) 33 mypage = myres.read() 34 ucpage = mypage.decode("gbk") #ytf-8 35 36 37 total = pattotal.findall(ucpage) #当前组图总图数 38 num = patnum.findall(ucpage) #当前编号 39 40 41 print u"num:" 42 max = raw_input(">>>") 43 44 picnum = 1 45 46 while int(picnum) <= int(max): 47 48 49 if int(total[0]) == int(num[0]): #检测是否抓取完当前组图 50 SerialNumber = patnextgroup.findall(ucpage) 51 nexturl1 = nexturl + SerialNumber[0] 52 53 myres = s(nexturl1) 54 55 mypage = myres.read() 56 ucpage = mypage.decode("gbk") #ytf-8 57 SerialNumber = patnext.findall(ucpage) 58 59 total = pattotal.findall(ucpage) 60 num = patnum.findall(ucpage) 61 62 mat = pat.findall(ucpage) 63 64 if len(mat) : 65 print "Pic " + str(picnum) + " : Url: " + mat[0] + " " 66 67 fnp = re.compile('(w{6}.w+)$') 68 fnr = fnp.findall(mat[0]) 69 if fnr: 70 fname = fnr[0] #下载给的文件名 71 urllib.urlretrieve(mat[0], fname) #下载 72 picnum+=1 73 74 else: 75 print "no data" 76 77 print u" Done"
程序抓取的是 http://desk.zol.com.cn/bizhi/6262_77251_2.html 的图片
抓取完一张
就申请进入下一页继续抓取
运行结果:

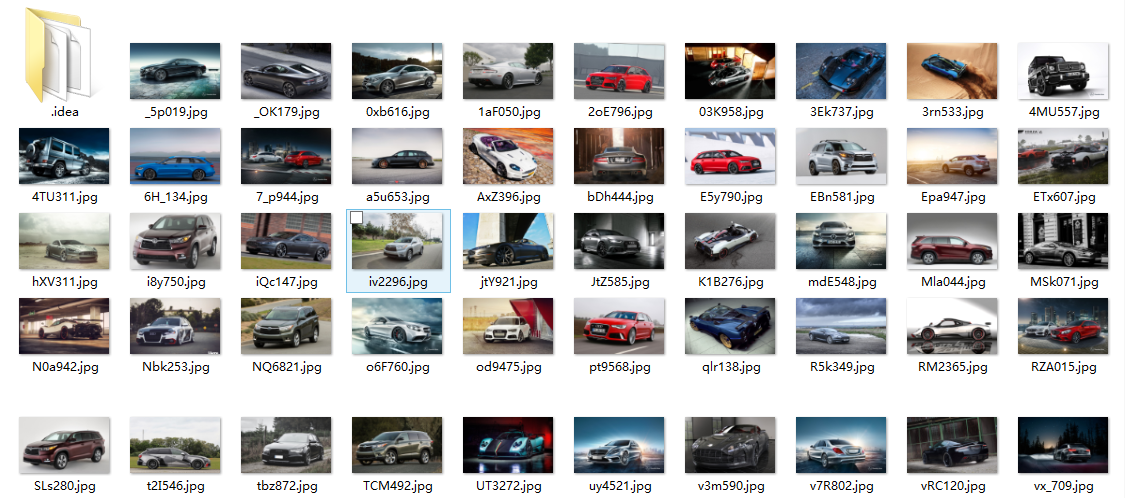
收获:
1.html js 不熟悉
2.可以通过找URL直接的规律 找下一页的URL
3.查了些资料 发现很多东西都可以学 html js beautiful soup等
4.还没习惯用try 语句
5.多练多学多问
6,urllib.urlretrieve() mypage.decode("gbk")
遇到的困难:
1.一开始不知道下一页的链接在哪 找了很久才找到 但方法不对 不知道有什么好的方法 一个原因是不了解 html js
2.一开始不知道怎么“变”到下一页,所以还想着通过pymouse控制鼠标。。。。。。结果鼠标不受控制 暴力重启。。。
3.运行的时候会跳出这个问题:IOError: [Errno socket error] [Errno 10060],为什么呢?还需要设置什么?求大神帮忙解决