本系列是 极客时间王宝令老师《JAVA 并发编程实战》课程的学习笔记,目的在于学习之后的思考与总结,将学到的东西转换成自己的东西,输出出来。
架构图如下:
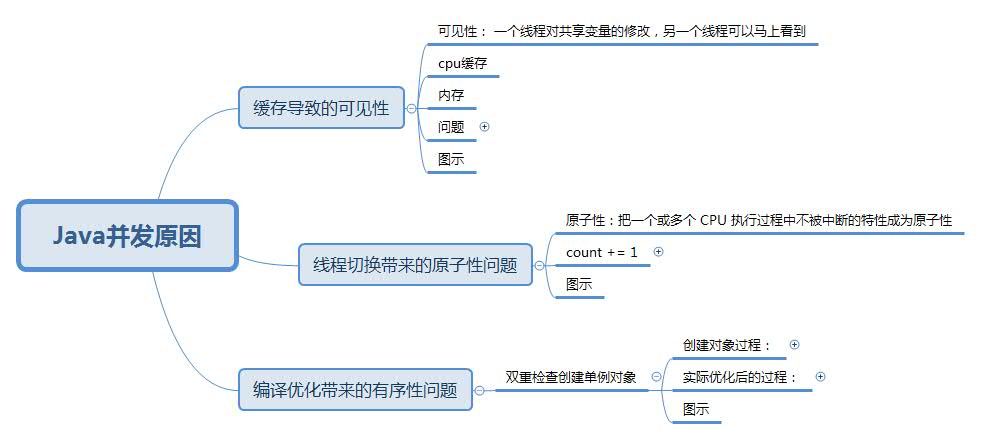
导致并发的原因有三种:
-
缓存导致的可见性问题
-
线程切换带来的原子性问题
-
编译优化带来的顺序性问题
并发源头之一:缓存导致的可见性问题
说到可见性,什么是可见性呢?
可见性是指一个线程对共享变量的修改另一个线程能够立刻看到。
那么对于单核 CPU 来说不会存在可见性问题,因为所有线程都在同一 CPU 上执行,CPU 缓存与内存缓存都是共用的。
而多核 CPU 则会有可见性问题,每一个线程都有自己的 CPU 缓存,如果同步不及时,很容易出现问题,如下是单核 CPU 到多核 CPU 的变化:

很明显,在多核时如果 线程 A 操作的是 CPU-1 上的缓存,而线程 B 操作的是 CPU-2 上的缓存,这个时候线程 A 对变量 V 的操作对线程 B 就不可见了。
比较经典的例子是 A B 两个线程,执行一次循环 10000次 count += 1 的方法,count 初始为 0,每个线程都调用一次上述方法,得到的 count 的值是在 10000 ~ 20000 之间的数,并不是我们期望的 20000 。
我们分析一下,假设线程 A 和线程 B 同时开始执行,那么第一次都会将 count = 0 读到各自的 CPU 缓存里,执行完 count+=1 之后,各自 CPU 缓存里的值都是 1,同时写入内存后,我们会发现内存中是 1,而不是我们期望的 2。之后由于各自的 CPU 缓存里都有了 count 的值,两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。这就是缓存的可见性问题。
并发源头之二:线程切换导致的原子性问题
所谓的原子性,并不是指高级语言里的一行代码,如上述的 count += 1 是需要多条 CPU 指令完成的,至少需要三条指令:
-
指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
-
指令 2:之后,在寄存器中执行 +1 操作;
-
指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
我们知道,进程之间是通过时间片来相互切换执行的,现在操作系统都是基于更轻量的线程来调度,提到的任务切换都是指线程切换。线程切换就会破坏程序的原子性,导致本应该同时执行的CPU指令被迫中断,从而产生问题。
所以原子性指定是一个或者多个操作在 CPU 执行的过程中不被中断的特性。
再来看上面 count += 1 的例子,我们潜意识是认为 count += 1 是原子性的,其实不然,这段代码很有可能出现如下线程切换带来的问题:

并发源头之三:编译优化带来的顺序性问题
其实编译器为了优化性能,有时候会改变程序中语句的先后顺序。
Java 中一个经典的案例就是利用双重检查创建单例对象,代码如下:
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
假设有两个线程 A B 同时调用 getInstance() 方法,他们会同时发现 instance == null,于是同时对 Singleton.class 加锁,此时 JVM 保证只有一个线程能够加锁成功(假设是线程 A),另外一个线程则会处于等待状态(假设是线程 B);线程 A 会创建一个 Singleton 实例,之后释放锁,锁释放后,线程 B 被唤醒,线程 B 再次尝试加锁,此时是可以加锁成功的,加锁成功后,线程 B 检查 instance == null 时会发现,已经创建过 Singleton 实例了,所以线程 B 不会再创建一个 Singleton 实例。
这看上去很完美,其实是有问题的,问题就出在 new 操作上,我们以为 new 操作应该是:
-
分配一块内存 M;
-
在内存 M 上初始化 Singleton 对象;
-
然后 M 的地址赋值给 instance 变量。
但是实际优化后的路径却是:
-
分配一块内存 M;
-
将 M 的地址赋值给 instance 变量;
-
最后在内存 M 上初始化 Singleton 对象。
优化有的程序就有问题了,如图:
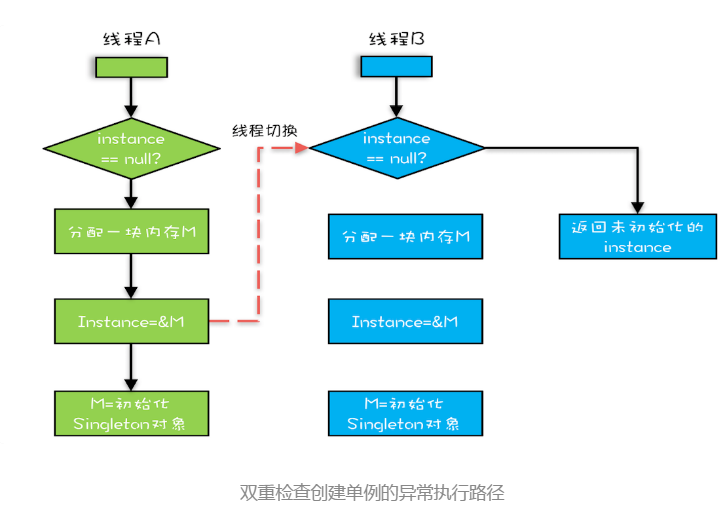
假如在图中位置出现了线程切换,B 线程判断 instance != null,就会返回未初始化的引用,就会出现问题。
总结:
缓存导致的可见性问题,线程切换带来的原子性问题,编译优化带来的有序性问题是并发问题的源头,后续我们会继续学习该课程,巩固基础,打好并发这场硬仗。
参考资料 : 《JAVA 并发编程实战》