为什么查询慢
慢的原因有很多,比如网络、CPU、IO、锁、SQL本身问题等。
SQL执行响应时间是第一位的,SQL的优化一定要找出哪部分是最慢的,具体问题具体分析。分析方法可以使用系统性能检测和执行计划查看。
数据量大问题
1.查询是避免使用select * ,应该具体列出需要的那些字段;
2.如果明确了需要查询结果是数目,建议使用limit N,只取出需要的数据,不做多余的查询避免消耗;
3.多次重复查询一个大量数据的操作,可以考虑使用缓存,减小数据库压力。
mysql自带的优化
查询过程:
客户端和服务端建立连接;连接先查询缓存,查询完缓存之后有会进项SQL解析,预处理,优化之后再执行。
1.数据库自带缓存,连续重复查询会从缓存中返回结果。缓存会在mysql 8版本去掉该模块。
2.通过关键字将SQL语句进行解析,生成一颗解析树,解析器将按照语法规则验证和解析查询。预处理器会进一步检查解析树是否合法,表名和列名是否存在,验证权限等。
3.mysql使用的是基于成本的优化器,在优化的时候会尝试预测一个查询使用某种查询计划时候的成本,并选择其中成本最小的一个。
show status like 'last_query_cost';--查询上一次查询SQL执行的开销,包括IO和CPU开销
select index_name,count(*) from information.INNNODB_BUFFER_PACE where INDEX_NAME IN ('TEST1','TEST2') AND TABLE_NAME LIKE '%TEST%' GROUP BY index_name; --可以查询到SQL执行时候的buffer pool 消耗
4.mysql的优化是基于成本的优化,所以结果不一定是查询速度最快的。具体结果得在优化中测试。
静态优化:对解析树进行分析,只会执行一次。
动态优化:每次执行会重新计算,跟查询结果取值、是否有索引、数据量大小有关系。
5.关联查询
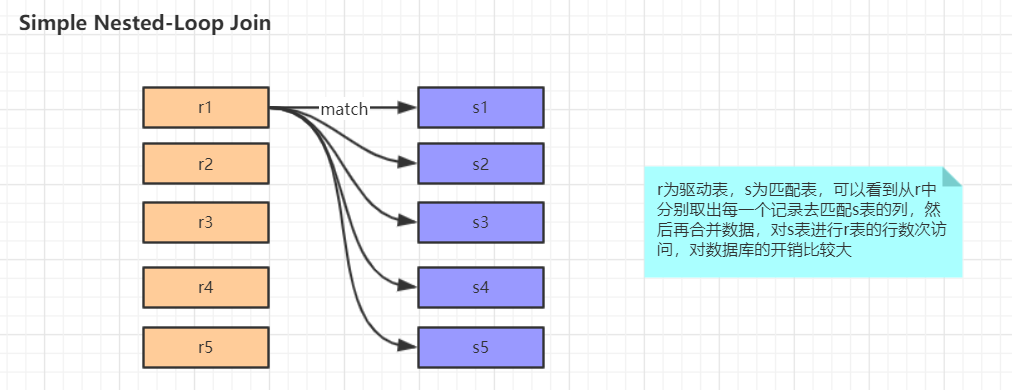
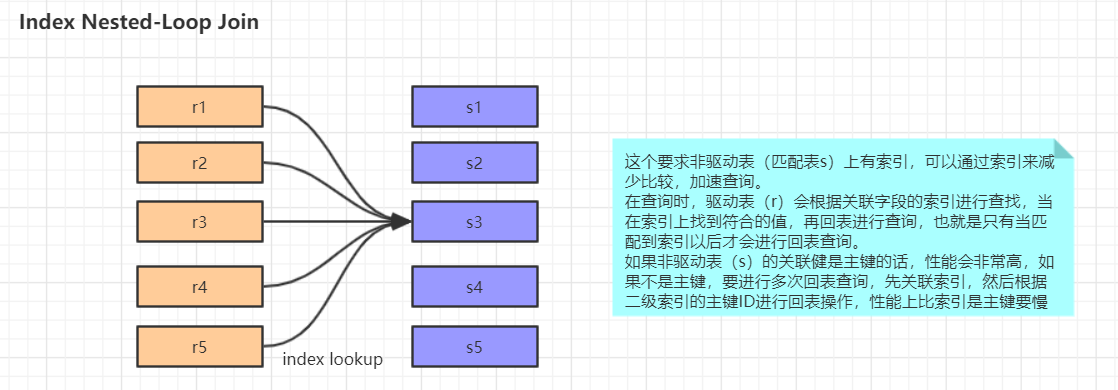
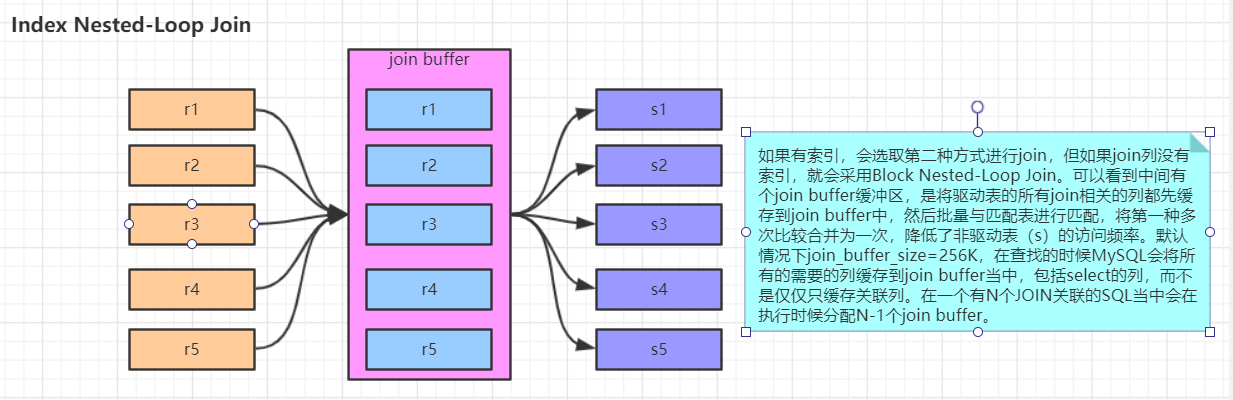
1.Join Buffer会缓存所有参与查询的列而不是只有Join的列。
2.可以通过调整join_buffer_size缓存大小
3.join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
4.使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
show variables like '%optimizer_switch%';--优化器功能开关;
优化小知识
1.优化count查询
在没有任何where条件的时候,myisam存储引擎的count()统计比较快,因为myisam存储引擎维护一个总数值。
正常情况下,count(),count(1),count(id)查询速度是一样的。
如果不需要一个准确值的话,可以用explain取一个近似值。
2.关联查询
阿里规范,不建议三张表以上用join,非要用,on条件(using子句)添加索引。
确保任何的groupby和order by中的表达式只涉及到一个表中的列,这样mysql才有可能使用索引来优化这个过程
3.子查询
建议优化为关联查询,具体问题具体分析
4.limit分页
利用子查询,减少页数过大,扫描过多,缓存区存放不下,耗时过长。
select film_id,description from film order by title limit 50,5;
explain select film.film_id,film.description from film inner join (select film_id from film order by title limit 50,5) as lim using(film_id);
5.自定义变量
1.使用
set @one :=1;--设置自定义变量
set @min_actor :=(select min(actor_id) from actor);--将子查询赋值给自定义变量
set @last_week :=current_date-interval 1 week;--编号
2.限制
1、无法使用查询缓存
2、不能在使用常量或者标识符的地方使用自定义变量,例如表名、列名或者limit子句
3、用户自定义变量的生命周期是在一个连接中有效,所以不能用它们来做连接间的通信
4、不能显式地声明自定义变量地类型
5、mysql优化器在某些场景下可能会将这些变量优化掉,这可能导致代码不按预想地方式运行
6、赋值符号:=的优先级非常低,所以在使用赋值表达式的时候应该明确的使用括号
7、使用未定义变量不会产生任何语法错误
3.使用场景
1、在给一个变量赋值的同时使用这个变量
select actor_id,@rownum:=@rownum+1 as rownum from actor limit 10;
2.做排名编号
select actor_id,@rownum:=@rownum+1 as cnt from film_actor group by actor_id order by cnt desc limit 10;
3.自定义时间戳记录数值