实现原理
我们采用如下的方法来实现把一个 .pdf 文件导入到 Elasticsearch 的数据节点中:
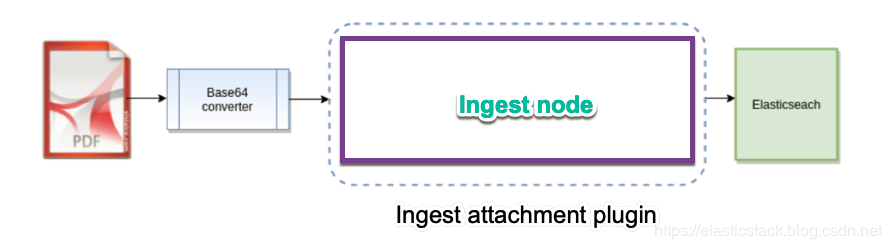
如上图所示,我们首先把我们的 .pdf 文件进行 Base64 处理,然后上传到 Elasticsearch 中的 ingest node 中进行处理。我们可以通过 Ingest attachment plugin 来使得 Elasticsearch 提取通用格式的文件附件比如 PPT、XLS及PDF。最终,数据进入到 Elasticsearch 的 data node 中以便让我们进行搜索。
导入PDF文件到Elasticsearch中
# 准备PDF文件
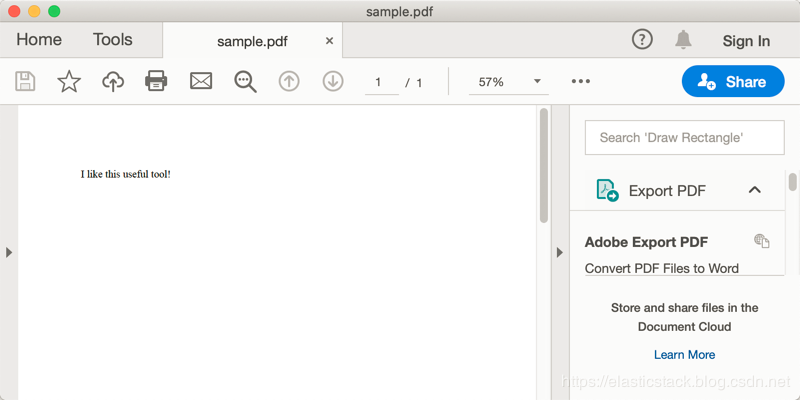
我们可以使用 Word 或其它编辑软件来生产一个 PDF 文件,暂且我们叫这个文件的名字为 sample.pdf,而它的内容非常简单,在 sample.pdf 文件中,我们只有一句话:“I like this useful tool”。
# 安装 Ingest attachment plugin
Ingest attachment plugin 允许 Elasticsearch 通过使用 Apache 文本提取库 Tika 提取通用格式(例如:PPT,XLS 和 PDF)的文件附件。Apache Tika 工具包可从一千多种不同的文件类型中检测并提取元数据和文本。所有这些文件类型都可以通过一个界面进行解析,从而使 Tika 对搜索引擎索引,内容分析,翻译等有用。
需要注意的是,源字段必须是 Base64 编码的二进制,如果不想增加在 Base64 之间来回转换的开销,则可以使用 CBOR 格式而不是 JSON,并将字段指定为字节数组而不是字符串表示形式,这样处理器将跳过 Base64 解码。
可以使用插件管理器安装此插件,该插件必须安装在集群中的每个节点上,并且每个节点必须在安装后重新启动。
bin/elasticsearch-plugin install ingest-attachment
#查看是否安装成功
./bin/elasticsearch-plugin list
# 创建 attachment pipeline
我们可以在我们的 ingest node 上创建一个叫做 pdfattachment 的 pipleline:
PUT _ingest/pipeline/pdfattachment { "description": "Extract attachment information encoded in Base64 with UTF-8 charset", "processors": [ { "attachment": { "field": "file" } } ] }
# 转换并上传PDF文件的内容到Elasticsearch中
对于 Ingest attachment plugin 来说,它的数据必须是 Base64 的。我们可以在网站Base64 encoder 来进行转换,我们可以直接通过下面的脚本来进行操作:
#!/bin/bash encodedPdf=`cat sample.pdf | base64` json="{"file":"${encodedPdf}"}" echo "$json" > json.file curl -XPOST 'http://localhost:9200/pdf-test1/_doc?pipeline=pdfattachment&pretty' -H 'Content-Type: application/json' -d @json.file
在上面的脚本中,我们针对 sample.pdf 进行 Base64 的转换,并生成一个叫做 json.file 的文件。在最后,我们把这个 json.file 文件的内容通过 curl 指令上传到 Elasticsearch 中,我们可以在 Elasticsearch 中查看一个叫做 pdf-test1 的索引。
查看索引并搜索
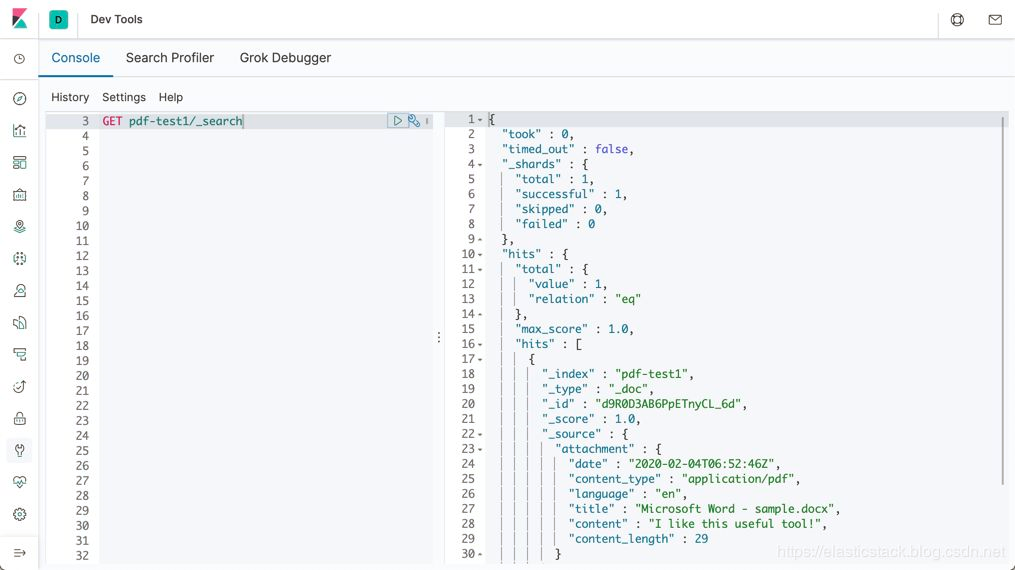
我们可以通过如下的命令来查询 pdf-test1 索引:
GET pdf-test1/_search
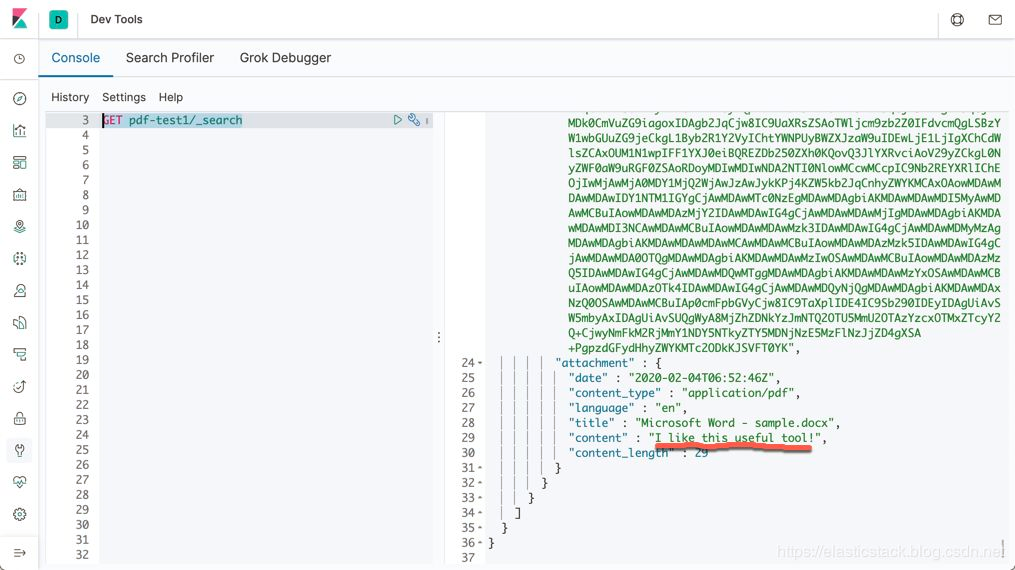
在上面我们可以看出来,我们的索引中有一个叫做 content 的字段,它包含了我们的 pdf 文件的内容,这个字段可以同我们进行搜索。在上面我们也看到了一个很大的一个字段 file,它含有我们转换过的 Base64 格式的内容。如果我们不想要这个字段,我们可以通过添加另外一个 remove processor 来除去这个字段:
PUT _ingest/pipeline/pdfattachment { "description": "Extract attachment information encoded in Base64 with UTF-8 charset", "processors": [ { "attachment": { "field": "file" } }, { "remove": { "field": "file" } } ] }
这样我们除去了那个叫做 file 的字段,那么修正后的索引内容为: