存储系统是计算机系统的重要组成部分,虽然内存容量在不断扩大,但内存仍是宝贵资源,如何提高主存储器利用率,并扩大主存,对主存信息实现有效保护是存储器管理主要任务,也是各种不同存储管理方法的目标。
计算机的存储体系结构
计算机为什么要使用存储器?
-----------冯诺依曼原理
为什么要进行存储管理?
存储器一直一来都是较为珍贵的系统资源,需要合理使用。
程序的逻辑空间和实际的物理空间不甚相同,需要进行映射。
存储结构层次

存储管理的目的
使得用户和用户程序不涉及内存物理的细节。
自动完成用户程序的装入
提高内存的利用率
解决内存速度与CPU速度不匹配的问题
实现内存共享
总结:方便使用者,有效利用存储资源,提高系统工作效率。
存储管理的任务
在现代操作系统中,存储管理的主要任务有以下几个方面:
地址变换(地址再定位)
存储资源的分配和回收
存储共享和保护
存储器扩充:1、覆盖技术 2、交换技术
名字空间、地址空间和存储空间
在源程序中,是通过符号名来访问子程序和数据的,我们把程序中符号名的集合称为“名字空间”。
汇编语言源程序经过汇编,或者高级语言源程序经过编译,得到的目标程序是以“0”作为参考地址的模块。然后多个目标模块由连接程序连接成一个具有统一地址的装配模块。我们把目标模块中的地址称为相对地址(或称为逻辑地址),而把相对地址的集合称为“相对地址空间”或简称为“地址空间”
地址空间的程序和数据经过地址重定位处理后,就变成了可由cpu直接执行的绝对地址程序。我们把这一地址集合称为“绝对地址空间”或"存储空间“。
基本概念
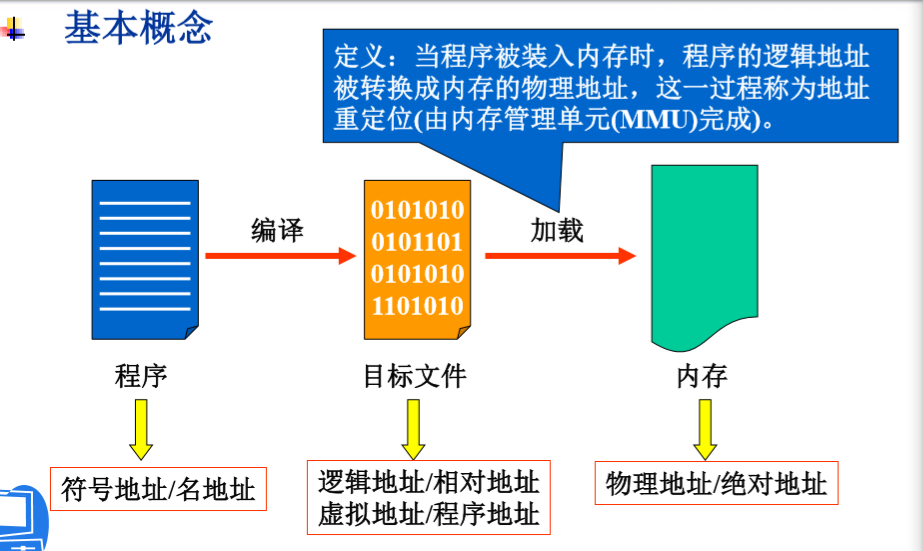
常见的地址重定位技术
绝对传入(Absolute loading)/固定地址再定位
程序的地址再定位是在程序执行之前被确定的,也就是在编译连接时直接生成实际存储器地址(物理地址)。在此,程序地址和内存地址空间是一 一对应的。
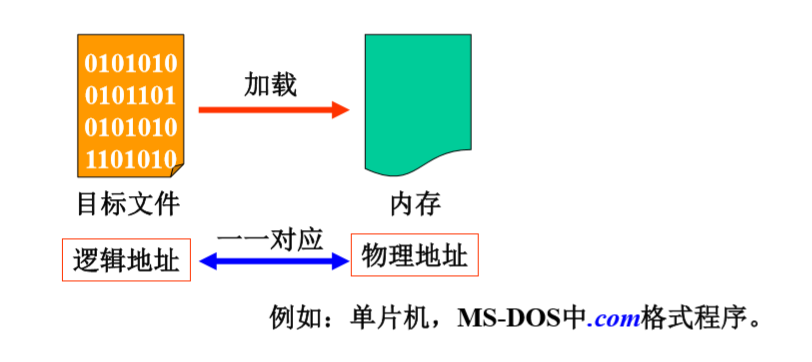
优点:装入过程简单
缺点:与硬件的结构过于密切,缺乏灵活性。
可重定位装入(Relocatable Loading)
即指程序装入内存时,由于程序的逻辑地址和物理地址不一致,由逻辑地址到物理地址的映射过程。
分类:
静态重定位:指地址定位时修改程序的逻辑地址值,完成定位后,在程序的执行期间地址将不再发生变化。特点:在程序执行之前进行地址再定位。

优点:无需硬件支持,容易实现。早期的操作系统中大多数都采用这种方法。
缺点:必须分配连续的存储区域;执行期间不能扩充存储空间,也不能在内存中移动,内存利用率低,不便于共享。
在程序中需要修改的位置称为重定位项 比如上面例子中的 LOAD A,200
程序装入内存中的起始地址称为重定位因子 1000.
为了支持静态重定位,连接程序在生成统一地址空间和装配模块时,还应产生一个重定位项表。
所以操作系统的装入程序要把装入模块和重定位项表一起装入内存。由装配模块的实际装入起始地址得到重定位因子,然后取重定位项,加上重定位因子得到欲修改位置的实际地址,最后对实际地址中的内容再加上重定位因子,从而完成指令代码的修改。
动态重定位:程序在装入内存时,不修改程序的逻辑地址值,程序在访问物理内存之前,再实时地将逻辑地址转换成物理地址。
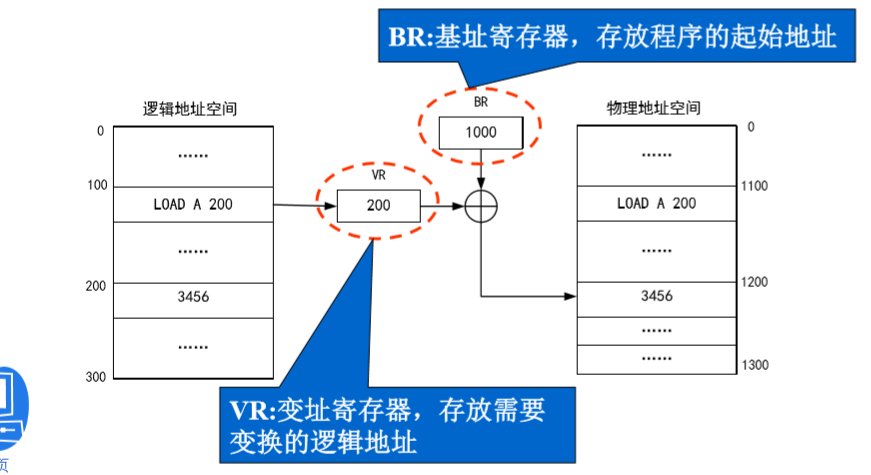
优点:
程序在执行期间可以换入和换出内存,可以解决内存紧张状态。
可以在内存中移动----把内存中的碎片集中起来,可以充分利用空间。
不必给程序分配连续的内存空间,可以较好的利用较小的内存块。
若干用户可以共享同一程序,实现共享。
缺点:需要附加的硬件支持,实现存储管理的软件算法比较复杂。
重定位寄存器(基址寄存器)
当该模块被操作系统调度到处理机上执行时,操作系统首先把该模块装入的实际起始地址减去目标模块的相对基地址(图中该模块的基地址为0),然后将其差值装入重定位寄存器。
存储管理方案分类
从操作系统的发展历史来看,存储管理主要有以下几种方案:
分区存储管理方案。要求连续分配存储空间,且程序要一次性全部装入内存。简单,但是有比较严重的内碎块和外碎块。
段式存储管理方案。不要求连续分配存储空间,段和段之间可以不连续,但程序需要一次性全部装入内存。有比较严重的外碎块。
页式存储管理方案。是一种不连续存储管理方案,也需要一次性全部装入内存。在逻辑地址空间和物理地址空间都采用分页的思想。缺点是每一个作业的最后一页有内碎块。
段页式存储管理方案。是一种不连续存储方案,段式存储管理和页式存储管理的结合。克服了纯分页和纯分段存储管理思想的缺点。
交换技术和覆盖技术
虚拟存储管理方案
分区存储管理:
是一种连续分配存储空间的管理方式。曾被广泛得应用于1960~1970年代的操作系统中。
思想:把内存分为一些大小相等或不等的分区,装入时每个应用程序占用一个或几个分区,操作系统占用其中一个分区。适用于多道程序系统和分时系统,支持多个程序并发执行。
分类
单一连续分区存储管理
固定分区管理
可变分区管理
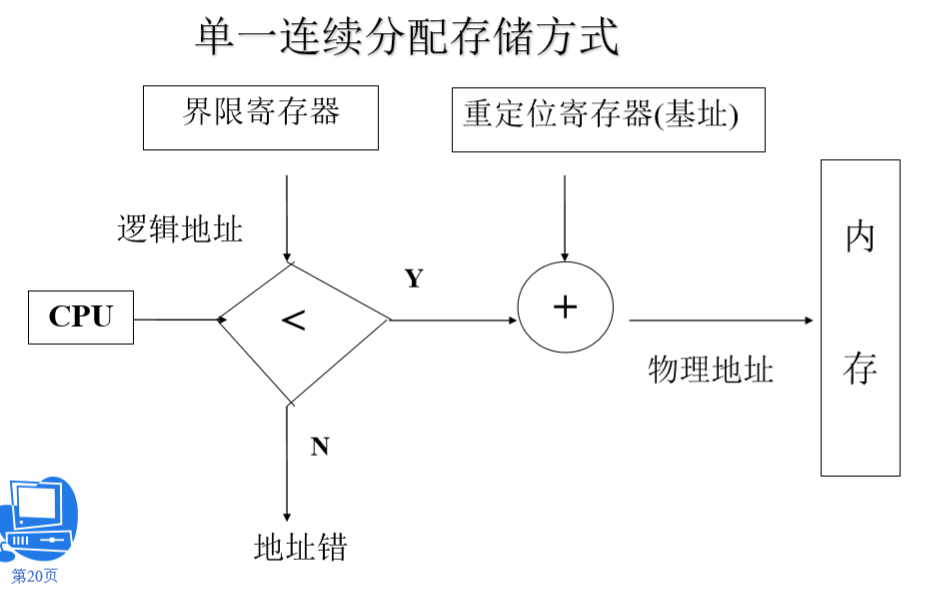
单一连续分区存储管理
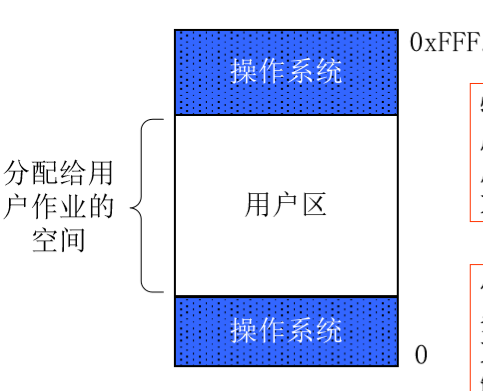
特点:一次只能装入一个程序,程序独占整个用户区,如果程序小于用户区,则剩余的空间浪费,如果大于,则无法装入。
优点:简单,适用于单用户、单任务的操作系统,不需要复杂的硬件支持。
缺点:一个作业运行时要占用整个内存地址空间,对内存造成了很大的浪费,不支持大作业。
固定分区管理
支持多道程序技术
实现方法:
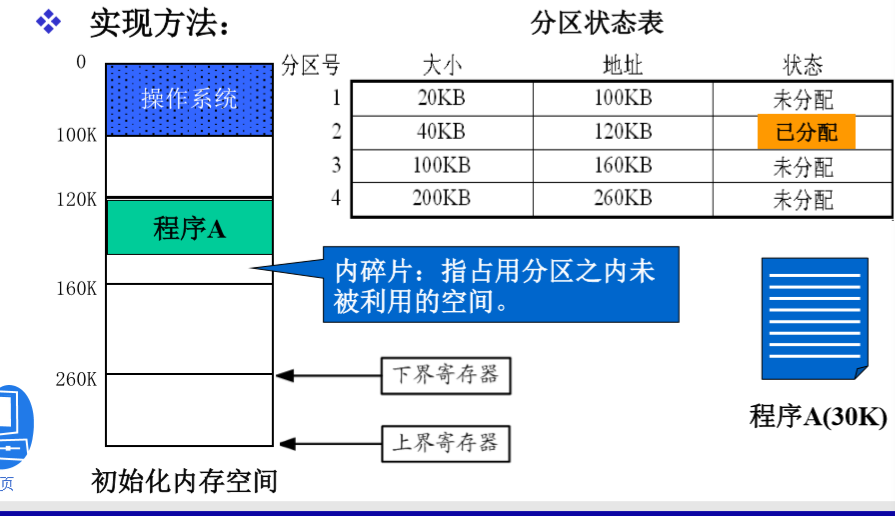
特点:
内存中同时可以容纳多道程序
程序必须连续存放,且要一次全部装入
优点:
相比单一连续分配方法,内存的利用率提高了
可以支持多道程序
实现简单,开销小。
缺点:
作业必须预先能够估计自己要占用多大的内存空间,有时候这是难以做到的。
存在内碎片,造成存储空间的浪费。
分区总数固定,限制了并发执行的程序数目。
固定分区的两种保护法
上下界保护法:
上界寄存器(UR)≤物理地址≤下界寄存器(LR)
基址/限长保护法:
基址寄存器(BR)≤物理地址≤(BR)+(LR)
LR为限长寄存器
可变分区
思想:预先不划分内存,当作业需要时向系统申请,系统从其中挖出一块给该作业,其大小等于作业所需内存的大小,然后将剩下的部分再作为空标快,给下一次分配使用。
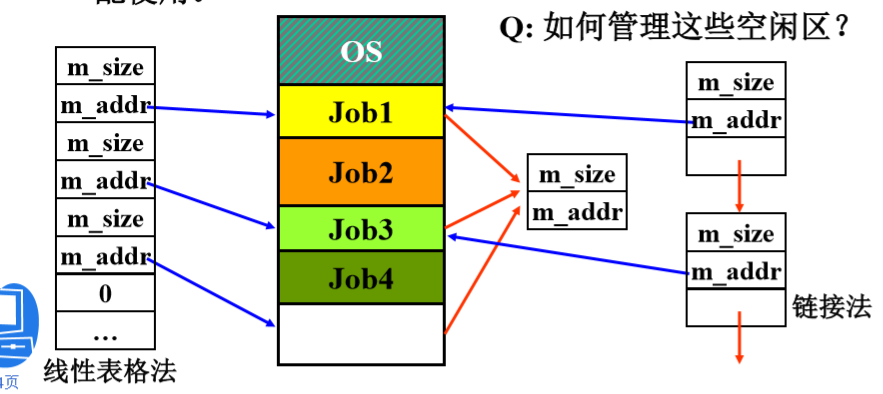
可变式分区数据结构
有两种数据结构,即自由区表和自由区链表,供可变分区管理选用。
自由区表形式
空闲分区表为每个尚未分配的分区设置一个表项,包括分区的序号、大小、始址和状态。
自由区链形式
为了实现对空闲分区的分配和连接,在每个分区的起始部分,用两个字段设置一些用于控制分区分配的信息(如分区的大小和状态位),以及用于链接其他分区的前向指针;在分区尾部,用两个字段设置了一个后向指针,为了检索方便也设置了控制分区分配的信息。然后,通过前、后向指针将所有的分区链接成一个双向链表。

空闲(自由)区表形式FBT
FBT相当简单,每个表目记录自由区的大小及其起始地址。由于自由区的个数是动态改变的,因此FBT表目的最大个数难以确定:太小了有可能产生表目溢出,太大了会产生表目空间的浪费。不过此表目所占位数不多,浪费不算严重。
双向链表
双向链表:链中的第1个自由区的始址和最末自由区的始址分别由FREE节点的始端指针和尾端指针给出。FREE的当前指针指向即将被查找的、循环链中的自由区。
FBC的设计技巧在于:它利用自由区本身的空间记录自由区的大小及前后自由区的位置。当分配一自由区时,用于成链的首尾两字也一起连同分配,这样就不再需用额外的存储空间来记录自由区现状。
分区分配算法
最先适应算法(first-fit)
分配方法:将所有的空闲分区按照地址递增的顺序排列,按照分区的先后次序,从头开始查找,符合要求的第一个分区就是要找的分区。
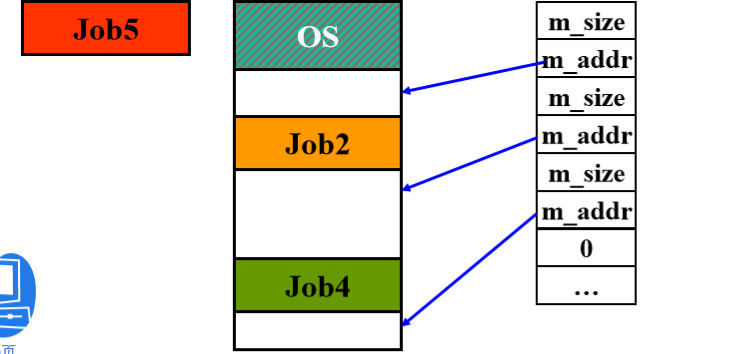
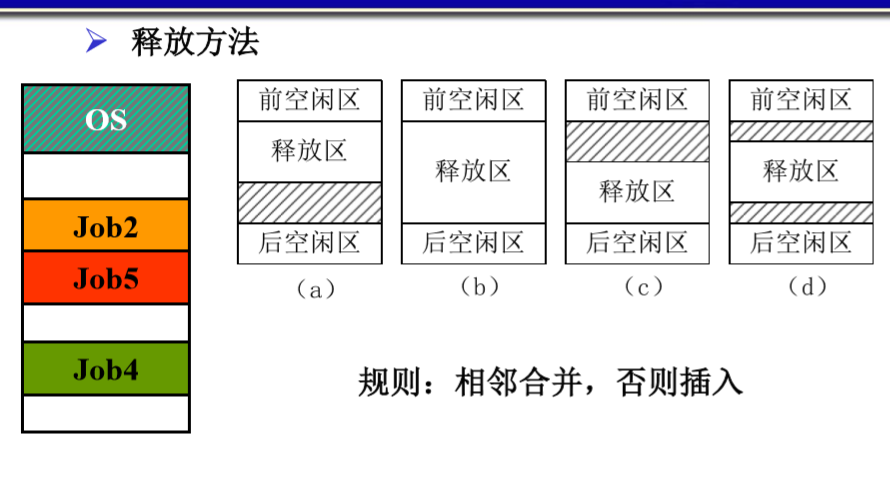
释放规则:相邻合并,否则插入
优点:
分配策略简单。
尽可能利用存储区低地址的空闲区,而在高地址部分保存较大的空闲区,容易满足大作业。
在释放内存分区时,如果有相邻的空白区就进行合并,使其成为一个较大的空白区。
缺点:
查找总是从表首开始,因此前面的空闲区往往被分割得很小时,查找次数增大。
会产生外碎片(指占用的分区之间难以利用的空闲分区),这些碎片散布在存储器的各处,不能集中使用,因而降低了存储器的利用率。
循环最先适应算法(next-fit,下次适应算法)
分配方法:按分区的先后次序,从上次分配的分区起查找,到最后分区时再回到开头,符合要求的第一个分区就是找到的分区。
释放方法:同于最先适应算法。
优点:使空闲分区分布得更均匀,提高了分配查找的速度。
缺点:较大的空闲分区不易保留。
最佳适应算法(best-fit)
分配方法:将所有的空闲分区按照其容量递增的顺序排列,当要求分配一个空白分区时,由小到大进行查找,找到合适的分配。
释放方法:在整个链表上搜索地址相邻的空闲区,合并后,再插入到合适的位置。
优点:
分配后所剩余的空白快会最小,较大的空闲分区会被保留。
平均,只要查找一半的表格便能找到最佳适应的空白区。
如果有一个空白区的容量正好满足要求,则它必被选中。
缺点:空白区一般不可能恰好满足要求,在分配之后的剩余部分通常非常小,以致小到无法使用,会形成较多外碎片。
最坏适应算法(worst-fit)
分配方法:于最佳适应算法相反,将所有的空白分区按容量递减的顺序排列,最前面的最大的空闲分区就是找到的分区。
释放方法:同于最佳适应算法。
优点:分配的时候,只需查找一次,就可以成功,分配的算法很快。
缺点:最后剩余的分区会越来越小,不会保留较大的空闲分区,无法运行大程序。
