用kafka的目的
kafka是mq的一种,那么使用mq的三大好处削峰、解耦、异步,自然也是使用kafka的目的之一。不过不同的mq有不同的使用场景,不同mq的使用场景以后我会在别的文章中总结。
基本概念
消息和批次
消息:kafka的数据单元。可以理解成数据库的一条记录。消息有一个可选的元数据,叫做键。
批次:一组消息,这些消息属于相同主体和分区。消息分批次传输可以降低网络开销,不过要权衡响应时间和吞吐量。批次越大,吞吐量越大,但是时延越高。
模式
模式是指消息按一定结构来定义消息内容,让他们更易于理解。类似JSON、XML。kafka开发者喜欢用的序列化框架是Apache Avro。
主题和分区
主题:消息通过主题进行分类,主题类似数据库的表,或者文件系统中的文件夹。主题可以被分为若干分区,一个分区就是一个提交日志,消息以追加的方式写入分区,然后以先入先出的顺序读取。
一个主题一般包含几个分区,所以无法在整个主题范围内保证消息的顺序,但是可以保证消息在单个分区内的顺序。kafka使用分区实现数据的冗余性和拓展性,分区可以分布在不同的服务器上。

通常用流这个词描述kafka这类系统的数据。很多时候把一个主题内的数据看成一个流。
消费者和生产者
生产者创建消息,把消息发布到某一个特定的主题上。默认情况下消息会均衡地发布到所有分区上。在需要的情况下,也可以把消息写到指定的分区,通过消息键和分区器来实现。
消费者读取消息,消费者通过检查偏移量来区分已经读取过的消息,偏移量是一种元数据,不断递增的整数值,在特定的分区里,每个消息的偏移量是唯一的。消费者会将偏移量记录在zookeeper或者kakfa中,来保证关闭或重启时偏移量不消失。
消费者是消费者组的一部分。群组保证每个分区只能被一个消费者使用。通过这种方式,消费者可以消费包含大量消息的主题。而且,如果一个
消费者失效,群组里的其他消费者可以接管失效消费者的工作。

broker和集群
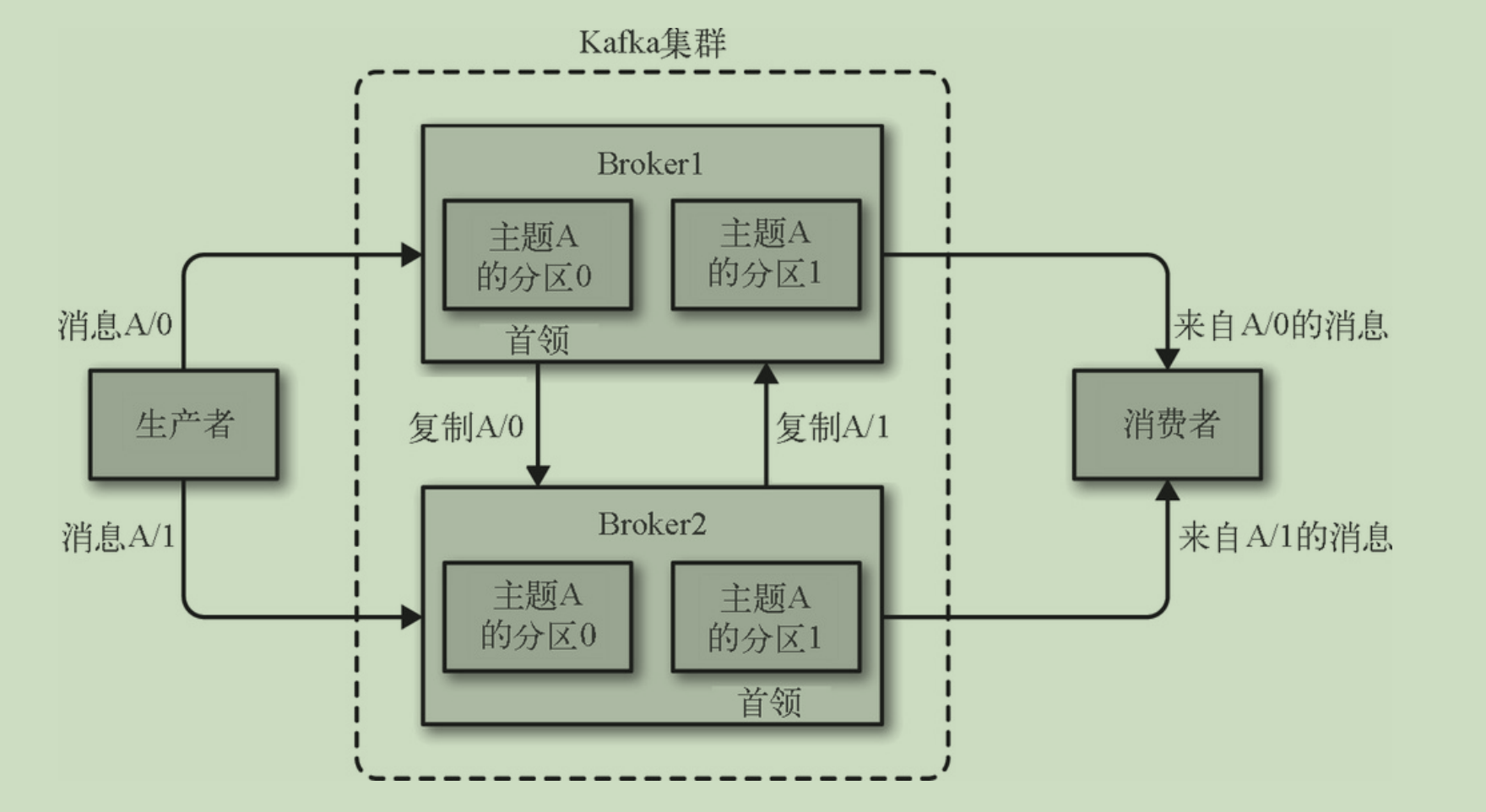
一个独立的kafka服务器成为broker,broker 接收来自生产者的消 息,为消息设置偏移量,并提交消息到磁盘保存。broker 为消费者提供 服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根 据特定的硬件及其性能特征,单个 broker 可以轻松处理数千个分区以及 每秒百万级的消息量。
broker 是集群的组成部分。每个集群都有一个 broker 同时充当了集群控 制器的角色(自动从集群的活跃成员中选举出来)。
控制器负责管理工 作,包括将分区分配给 broker 和监控 broker。在集群中,一个分区从属 于一个 broker,该 broker 被称为分区的首领。一个分区可以分配给多个 broker,这个时候会发生分区复制(见图 1-7)。这种复制机制为分区提 供了消息冗余,如果有一个 broker 失效,其他 broker 可以接管领导权。
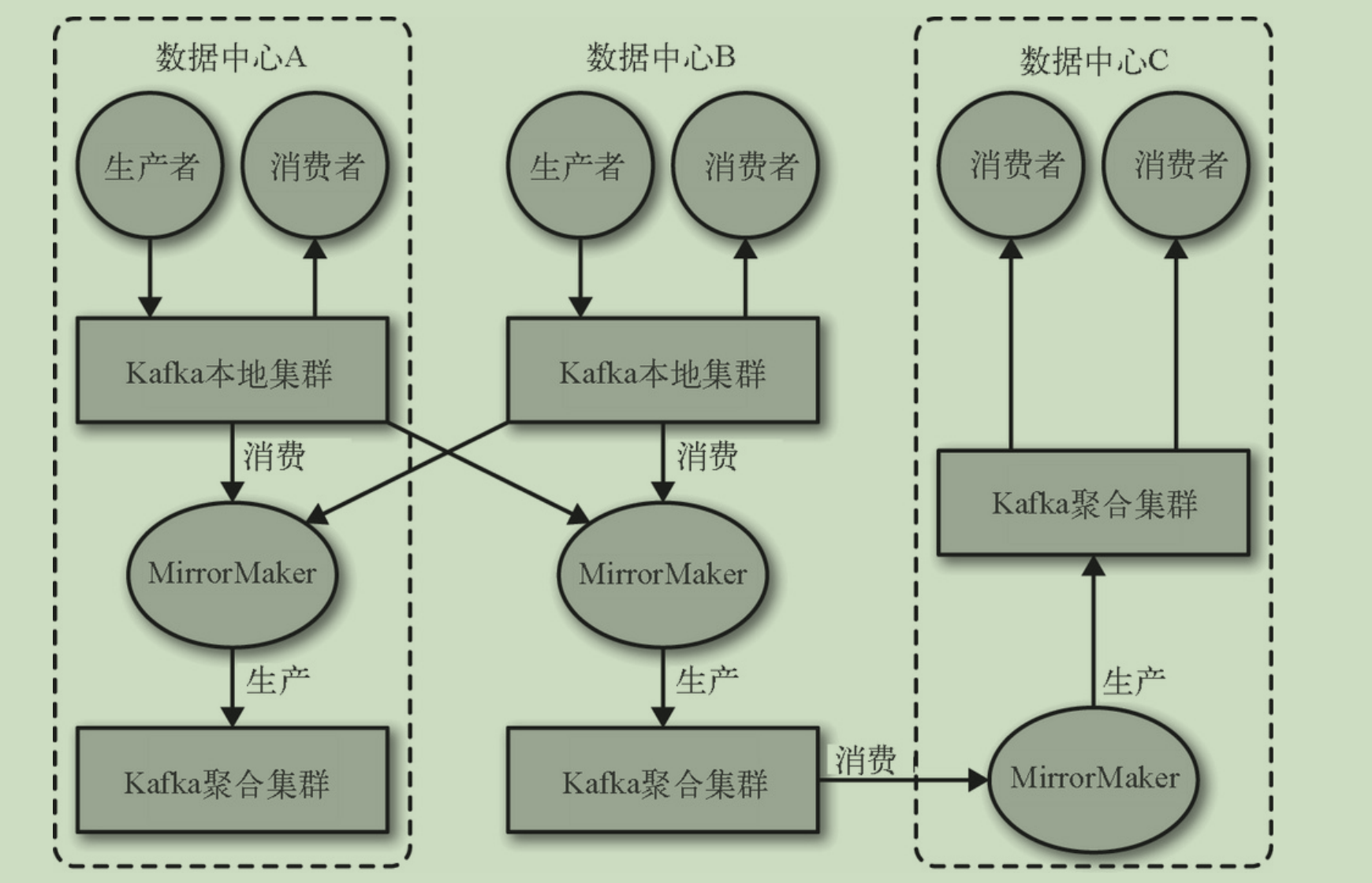
多集群
随着数据规模的增大,会用到多集群。
多集群的好处:
- 数据类型分离
- 安全需求隔离
- 多数据中心(灾难恢复)
kafka提供了 MirrorMaker的工具实现集群间的消息复制。
多数据中心架构
Kafka的特性
- 支持多消费者
- 支持多生产者
- 基于磁盘的数据存储
- 伸缩性
- 高性能
使用场景
- 活动跟踪
- 传递消息
- 度量指标和日志记录
- 提交日志
- 流处理