本文主要目的是测试单列是否应该建立索引,并以查询时间和扫描行数作为参考依据。mysql版本5.5.20
一:建表
CREATE TABLE `record` ( `id` int(11) NOT NULL AUTO_INCREMENT, `openid` varchar(63) NOT NULL, `tagId` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_openid` (`openid`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
二:插入数据
向record表中导入20万测试数据
三:测试openid列二值平均分布情况
(3.1)更新数据
update record set openid = '1' where id>0 and id<=100000; update record set openid = '2' where id>100000 and id<=200000;
(3.2)openid列不使用索引
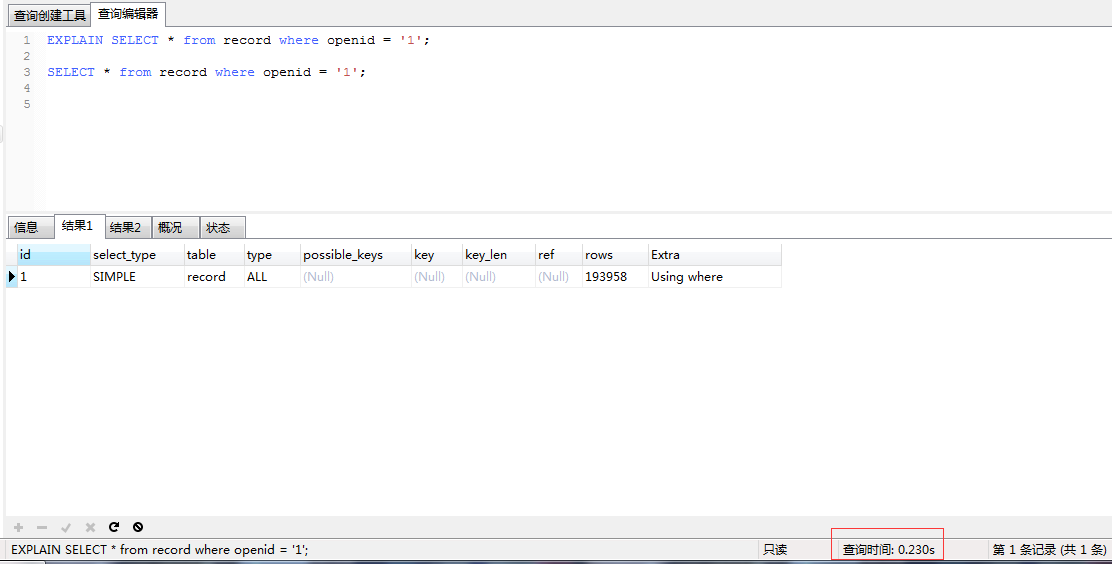
(3.2.1)查询所有列
(3.2.2) 查询tagId列

注:rows:显示MYSQL估算执行查询的行数,不是精确值,简单且重要,数值越大越不好
分析:不使用索引时,大致扫描193958行,查询所有列查询时间为0.230s,查询非索引单列为0.181s。所以,尽量不要查询不需要的列。
(3.3)openid列使用建表时的索引
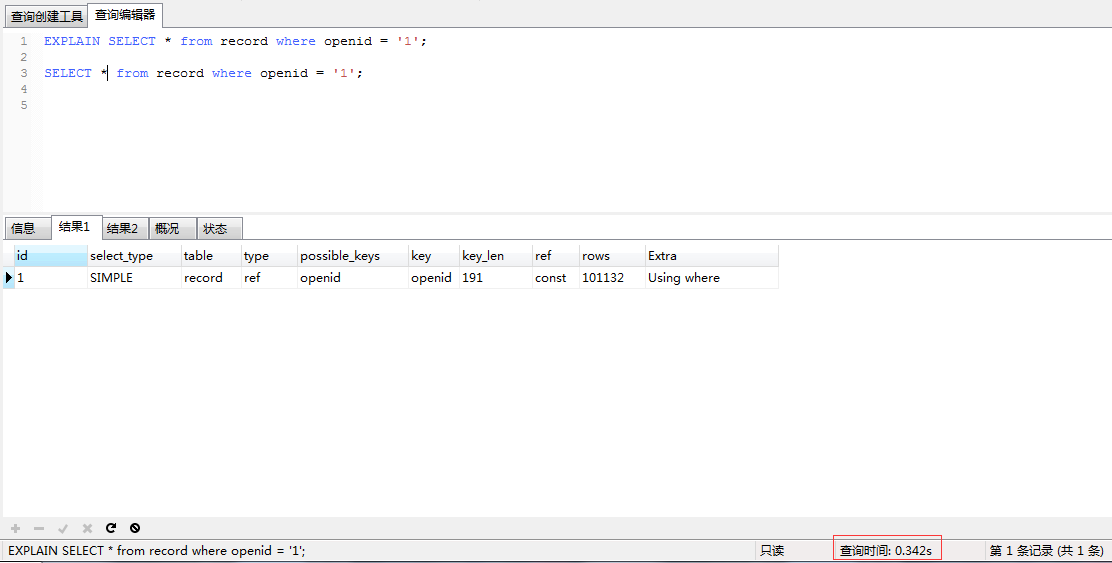
分析:openid列使用索引后,大致扫描101132行,查询时间0.342s,相对于不使用索引,虽然扫描的行数变少了,但是查询时间大致增加了三分之一。因为先要在BTree树中查找,然后再回表查询,导致查询时间不减反增了。所以平时我们如果在性别列等二值列建立索引,是完全没有效果的。这大概也是为什么有些时候(如二值分布,分布不均,选择超过一半的查询条件),即使该列建了索引,但是mysql选择全表查询的原因。
四:建索引总结
(1)经测试,在上述20万数据情况下,如果openid列4值平均分布的情况下,使用索引(全列查询0.175s)和不使用索引(全列查询0.178s)的时间大致相当。但索引还有额外内存等消耗,如果索引对查询性能改善不大,在该列建立索引作用不大。
(2)查询出的结果数据越多,查询时间越长。在数据分布不均,某个索引查询条件下,查出的数据比较多时需要注意。全表查询也是如此。
(3)在区分性较高的列上建索引是比较好的选择。