内置序列类型概览
容器序列: list、tuple和collections.deque这些序列能存放不同类型的数据
扁平序列: str、bytes、bytearray、memoryview和array.array, 这类序列只能容纳一种类型
1. bytearry(): 返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256 >>>bytearray() bytearray(b'') >>> bytearray([1,2,3]) bytearray(b'x01x02x03') >>> bytearray('runoob', 'utf-8') bytearray(b'runoob') >>> 2. memoryview(): 返回给定参数的内存查看对象(memory view)。所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。 >>>v = memoryview(bytearray("abcefg", 'utf-8')) >>> print(v[1]) 98 >>> print(v[-1]) 103 >>> print(v[1:4]) <memory at 0x10f543a08> >>> print(v[1:4].tobytes()) b'bce' 3. array.array(): 数组,可以存放放一组相同类型的数字 array.array(typecode[, initializer])
容器序列存放的是它所包含的任意类型的对象的引用,而扁平序列里存放的值而不是引用。换句话说,扁平序列其实是一段连续的内存空间。
序列类型还能按照能否被修改来分类:
可变序列:
list、bytearray、array.array、collections.deque和memoryview
不可变序列:
tuple、str和bytes
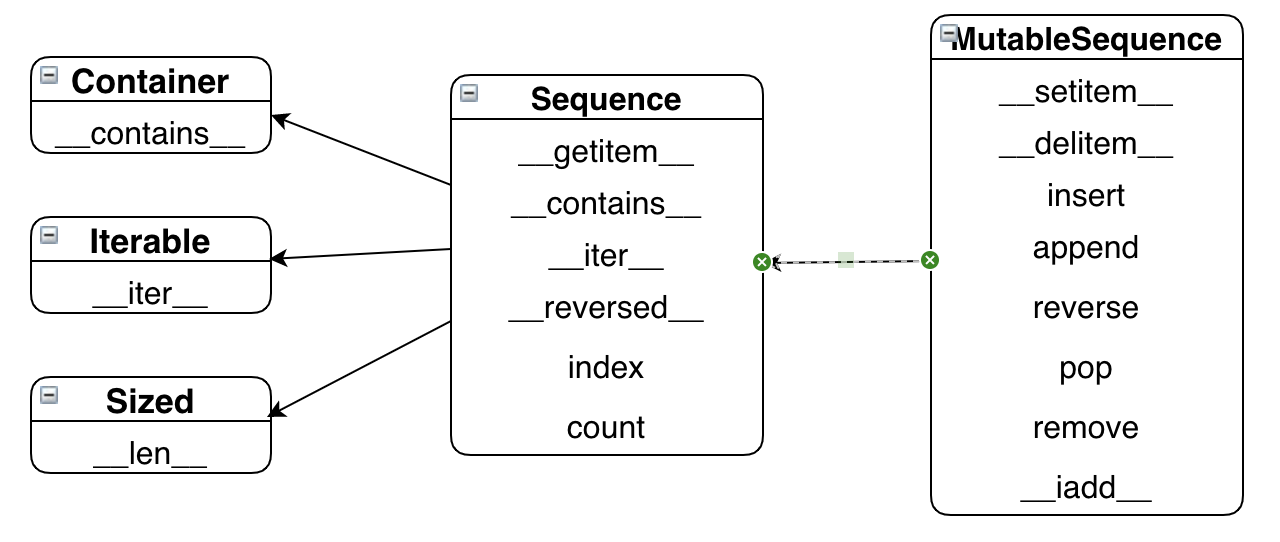
这个UML图列举了collections.abc中的几个类(超类在左边,箭头从子类指向超类)。这个图显示了可变序列(MutableSequence)和不可变序列(Sequence)的差异。通知也能看成前者从后者那里继承了一些方法。
列表推导和生成器表达式
列表推导是构建列表(list)的快捷方式,而生成器表达式则可以用来构建其他任何类型的序列。
列表推导式和可读性
示例:
# 列表推导式和可读性 # 把一个字符串标出Unicode码位的列表 # 方法1 symbols = '$%^&*(' codes = [] for symbol in symbols: codes.append(ord(symbol)) print(codes) # 方法2 symbols = '$%^&*(' codes = [ord(symbol) for symbol in symbols] print(codes)
使用列表推导式的原则是: 列表推导式不能被滥用,通常的原则是只用列表推导式来创建新的列表,并且尽量保持简短。如果列表推导的代码超过两行,可能就需要考虑是不是用for循环重写了
列表推导式不会再有变量泄漏的问题
# 在Python2.x中, 在列表推导中的for关键字之后的赋值操作可能会影响列表推导式上下文中的同名变量。 >>> x = "my precious" >>> dummy = [x for x in "ABC"] >>> x 'C' # 在Python3.x中,列表推导式、生成器表达式、以及同他们很相似的集合(set)推导和字典(dict)推导都有自己的局部作用域。就像函数似的。表达式内部的变量和赋值只在局部起作用。表达式的上下文里的同名变量还可以被正常使用。局部变量并不会影响他们。 >>> x = "ABC" >>> dummy = [ord(x) for x in x] >>> x 'ABC' >>> dummy [65, 66, 67]
列表推导同filter和map的比较
filter和map能做的事,列表推导式也可以做。而且还不需要借助难以理解和阅读的lambda表达式。
symbols = '$%^&*(' beyond_ascii = [ord(s) for s in symbols if ord(s) > 40] print(beyond_ascii) beyond_ascii2 = list(filter(lambda c:c>40, map(ord, symbols))) print(beyond_ascii2)
map/filter组合起来用不一定比列表推导快!!!
笛卡尔积
用列表推导可以生成两个或两个以上的笛卡尔积
colors = ['black', 'white'] sizes = ['S', 'M', 'L'] tshirts = [(color, size) for color in colors for size in sizes] print(tshirts) for color in colors: for size in sizes: print((color, size))
这里得到的结果是先以颜色排列,再以尺寸排列。
注意: 这个循环的嵌套关系和上面的列表推导中for从句的先后顺序一样。如果想依照先尺寸后颜色的顺序来排列。只需要调整从句的顺序。
列表推导式的作用只有一个: 生成列表
生成器表达式
生成器表达式可以生成任何类型的序列,这是列表推导做不到的。
虽然也可以使用列表推导来初始化元组、数组或其他序列类型。但是生成器表达式是更好的选择。
因为生成器表达式背后遵守了迭代器协议。可以逐个地产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个构造函数里。
显然生成器表达式可以节省内存。
生成器表达式的语法和列表推导差不多,只不过把方括号换成了圆括号而已。
示例:
1. 用生成器表达式初始化元组和数组
# 用生成器表达式初始化元组和数组 symbols = '$%^&*(' result1 = tuple(ord(symbols) for symbol in symbols) print(result1) # 如果生成器表达式是一个函数调用过程中的唯一参数,那么不需要额外再用括号把它括起来 import array result2 = array.array('I', (ord(symbol) for symbol in symbols)) print(result2) # array的构造方法需要两个参数,因此括号是必须的,array构造方法的第一个参数指定了数组中数字的存储方式。
2. 使用生成器表达式计算笛卡尔积
# 使用生成器表达式计算笛卡尔积 colors = ['black', 'white'] sizes = ['S', 'M', 'L'] for tshirt in ('%s %s' % (c, s) for c in colors for s in sizes): print(tshirt) # 生成器表达式逐个产出元素, 从来不会一次性产出一个含义6个T恤样式的列表
元组不仅仅是不可变的列表
有些Python入门教程把元组称为"不可变列表", 然而这并没有完全概况元组的特点。除了用作不可变的列表, 它还可以用于没有字段名的记录。
元组和记录
元组其实是对数据的记录,元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。如果只把元组理解为不可变的列表,那其他信息--它所含有的元素的总数和他们的位置--似乎就变得可有可无了,但是如果把元组当做一些字段的集合,那么数量和位置信息就变得非常重要了。
# 洛杉矶国际机场的经纬度 lax_coordinates = (33.9425, -118.408056) # 东京市的一些信息: 市名、年份、人口(单位:百万)、人口变化(单位: 百分比)和面积(单位: 平方千米) city, year, pop, chg, area = ('Tokyo', 2003, 32450, 0.66, 8014) # 一个元组列表, 元组的形式为(country_code, passport_number) traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')] # 在迭代的过程中, passport变量被绑定到每个元组上 # %格式运算符能匹配到对应的元组元素上 for passport in sorted(traveler_ids): print('%s/%s' % passport) # for循环可以拆包(分别提取元组里的元素), 因为元组中第二个元素无用, 所有它赋值给"_"占位符 for country, _ in traveler_ids: print(country)
元组拆包
元组拆包可以用到任何可迭代对象上, 唯一的硬性要求是: 被可迭代对象中的元素数量必须要跟接收这些元素元组的空档一致。除非我们用*来表示忽略多余的元素
最好辨认的元组拆包形式就是平衡赋值,也就是说吧一个可迭代对象里的元素,一并赋值到由对应的变量组成的元组中。
lax_coordinates = (33.9425, -118.408056) latitude, longitude = lax_coordinates # 元组拆包 print(latitude) print(longitude)
应用: 不使用中间变量交换两个变量的值
b, a = a, b
使用*号进行拆包
# 使用*号拆包 # divmod()方法: 返回第二个元素除以第一个元素的商和余数组成的元组 print(divmod(20, 8)) t = (20, 8) print(divmod(*t)) quotient, remainder = divmod(*t) print(quotient, remainder)
让一个函数可以用元组的形式返回多个值, 然后调用函数的代码就能很轻松的接收这些返回值
# os.path.split()函数返回以路径和最后一个文件名组成的元组(path, last_part) import os _, filename = os.path.split('/home/zhangjie/.ssh/idrsa.pub') print(filename)
用*来处理剩下的元素
a, b, *rest = range(5) print(a, b, rest) a, b, *rest = range(3) print(a, b, rest) a, b, *rest = range(2) print(a, b, rest) # 在平行赋值中, *前缀只能用在一个变量名前面, 但是这个变量可以出现在赋值表达式中的任意位置 a, *body, c, d = range(5) print(a, body, c, d) *head, b, c, d = range(5) print(head, b, c, d)
嵌套元组拆包
# 用嵌套元素来获取经度 metro_areas = [ ('Tokyo', 'JP', 36.933, (35.689722, 139.691667)), ('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)), ('Mexico City', 'MX', 20.142, (19.433333, -99.133333)), ('New York-Newark', 'US', 20.104, (40.808611, -74.020386)), ('Sao Paulo', 'BR', 19.469, (-23.547778, -46.635833)) ] print('{:15} | {:^9} | {:^9}'.format('', 'lat.', 'long.')) fmt = '{:15} | {:9.4f} | {:9.4f}' for name, cc, pop, (latitude, longitude) in metro_areas: if longitude <= 0: print(fmt.format(name, latitude, longitude))
具名元组
用nametuple构建的类的实例所消耗的内存跟元组是一样的,因为字段名被存在对应的类里面。这个实例跟普通的对象实例比起来也要小一些, 因为Python不会用__dict__来存放这些实例的属性
collections.nametuple是一个工厂函数, 它可以用来构建一个带字段名的元组和一个有名字的类
# 定义和使用具名元组 from collections import namedtuple City = namedtuple('City', 'name country population coordinates') tokyo = City('Tokyo', 'JP', 36.933, (35.689722, 139.691667)) print(tokyo) print(tokyo.population) print(tokyo.coordinates) print(tokyo[1])
说明:
- 创建一个具名元组需要两个参数, 一个是类名, 另一个是类的各个字段的名字。后者可以是由数个字符组成的可迭代对象,或者是由空格分隔开的字段名组成的字符串。
- 存放在对应字段里的数据要以一串参数的形式传入到构造函数中(注意: 元组的构造函数却只接受单一的可迭代对象)
- 可以通过字段名或位置来获取一个字段的信息
具名元组还有一些自己专有的属性,比如: _fileds类属性、类方法_make(iterable)和实例方法)_asdict()
print(City._fields) LatLong = namedtuple('LatLong', 'lat long') delhi_data = ('Delhi NCR', 'IN', 21.935, LatLong(28.613889, 77.208889)) delhi = City._make(delhi_data) print(delhi._asdict()) for key, value in delhi._asdict().items(): print(key + ':' + format(value))
说明:
- _fields属性是一个包含这个类所有字段名称的元组
- 用_make()通过接受一个可迭代对象来生成这个类的一个实例。它的作用跟City(*delhi_data)是一样的。(拆包)
- _asdict()把具名元组以collections.OrderDict的形式返回。
作为不可变列表的元组
除了增减元素相关的方法之外,元组支持列表的其他所有方法。还有一个例外,元组没有__reversed__方法,但是这个方法只是一个优化而已,reversed(my_tuple)这个用法在没有__reversed__的情况下也是合法的。
切片
为什么切片和区间会忽略最后一个元素?
- 当只有最后一个位置信息时,我们也可以快速看出切片和区间有几个元素: range(3)和my_list[:3]都返回3个元素
- 当起止位置信息都可见时,我们可以快速计算出切片和区间的长度,用后一个数减去第一个下标(stop-start)即可。
- 这样做也让我们可以利用任意一个下标来把序列分割成不重叠的两部分, 只要写出my_list[:x]和my_list[x:]就可以了
l = [10, 20, 30, 40, 50, 60] print(l[:2]) # 在下标2的地方分割 print(l[2:]) print(l[:3]) # 在下标3的位置分割 print(l[3:])
对对象切片
我们还可以用s[a:b:c]的形式对s在a和b之间以c为间隔去值。c还可以为负,负值意味着反向取值。
s = 'bicycle' print(s[::3]) print(s[::-1]) print(s[::-2])
a:b:c这种用法只能作为索引或者下标用在[]中来返回一个切片对象: slice(a, b, c)、对seq[start:stop:step]进行求值的时候,Python会调用seq.__getitem__(slice(start, stop, step))。
多维切片和省略
[]运算符里还可以使用以逗号分开的多个索引或者是切片。外部库NumPy里就用到这个特性,二维的numpy.ndarray就可以用a[i, j]这种形式来获取。抑或是用a[m:n, k:j]的方式来得到二维切片。
要正确处理这种[]运算符的话,对象的特殊方法__getitem__和__setitem__需要以元组的形式来接收a[i, j]中的索引。也就是说, 如果要得到a[i, j]的值,Python会调用a.__getitem__((i, j))。
Python内置的序列类型都是一维的,因此它们只支持单一的索引,成对出现的索引是没有用的。
省略(ellipsis)的正确书写方法是三个英文句号(...)。省略在Python解释器里是一个符号,而实际上它是Ellipsis对象的别名,而Ellipsis对象又是ellipsis类的单一实例。它可以作为切片规范的一部分,也可以用在函数的参数清单中。比如f(a, ..., z),或a[i:...]。在NumPy中, ...用作多维数组切片的快捷方式。如果x是四维数组,那么x[i: ...]就是x[i, :, :, :]的缩写
除了用来提取序列里的内容,切片还可以用来就地修改可变序列,也就是说修改的时候不需要重新组建序列。
给切片赋值
如果把切片放在赋值语句的左边,或把它作为del操作的对象,我们就可以对序列进行嫁接、切除或就地修改操作。
l = list(range(10)) print(l) l[2:5] = [20, 30] print(l) del l[5:7] print(l) l[3::2] = [11, 12] print(l) # 报错,如果赋值的对象是一个切片,那么赋值语句的右侧也必须是一个可迭代对象。即使只有单独一个值,也要把它转换成可迭代的序列 l[2:5] = 100 print(l)
对序列使用+和*
+和*都不会修改原有的操作对象,而是构建一个全新的序列
l = [1, 2, 3] print(l * 5) print(5 * 'abcd')
注意: 如果在a * n这个语句中, 序列a里的元素是对其他可变变量的引用的话, 需要格外注意, 比如my_list=[[]] * 3来初始化一个由列表组成的列表。但是得到的列表里包含的3个元素其实3个引用。而且这3个引用都是同一个列表。