GIL介绍
GIL的定义
GIL的官方定义如下:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
在CPython解释器中GI是一把互斥锁, 用来阻止同一个进程下的多个线程同时执行。因为CPython中的内存管理不是线程安全的。即垃圾回收机制不是线程安全的。
Python解释器有很多个版本: CPython、JPython、PyPython。但是普遍使用的都是CPython。
由定义, 可以得出
- GIL不是Python的特点, 而是CPython解释器的特点
- GIL是保证解释器级别的数据安全
- GIL会导致同一个进程下的多个线程无法同时执行即无法利用多核优势
- 针对不同的数据还是需要加不同的锁处理
GIL的介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
在一个Python的进程内,不仅有py文件运行的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内
1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的
2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
那么多线程的执行流程为:
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
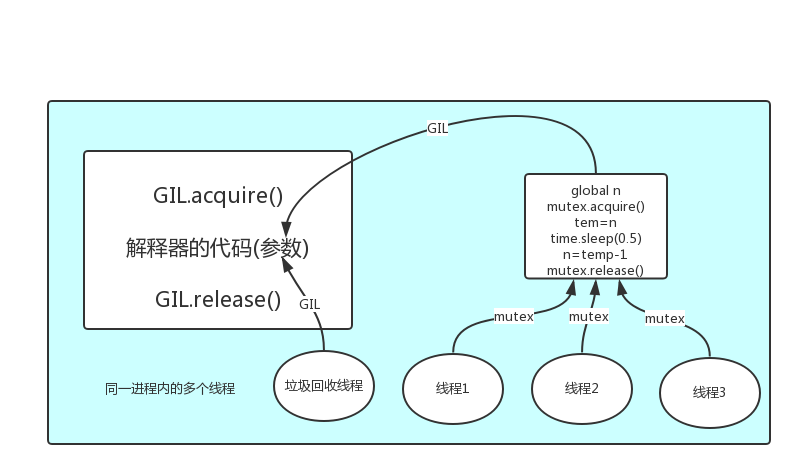
GIL与Lock
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理
多线程的应用场景
有了GIL的存在,同一时刻同一进程中只有一个线程被执行。那么
验证多进程与多线程的应用场景
多进程
计算密集型
def work(): res = 0 for i in range(1000000): res *= i if __name__ == '__main__': p_list = [] print(os.cpu_count()) # 获取当前计算机CPU个数 process_start_time = time.time() for i in range(12): p = Process(target=work) p.start() p_list.append(p) for p in p_list: p.join() print('多进程的运行时间为:', time.time() - process_start_time) # 多进程的运行时间为: 0.09932708740234375 t_list = [] thread_start_time = time.time() for i in range(12): t = Thread(target=work) t.start() t_list.append(t) for t in t_list: t.join() print('多线程的运行时间为:', time.time() - thread_start_time) # 多线程的运行时间为: 0.4195849895477295
多线程
IO密集型
def work(): time.sleep(2) if __name__ == '__main__': p_list = [] print(os.cpu_count()) # 获取当前计算机CPU个数 process_start_time = time.time() for i in range(4000): p = Process(target=work) p.start() p_list.append(p) for p in p_list: p.join() print('多进程的运行时间为:', time.time() - process_start_time) # 多进程的运行时间为: 20.892397165298462 t_list = [] thread_start_time = time.time() for i in range(4000): t = Thread(target=work) t.start() t_list.append(t) for t in t_list: t.join() print('多线程的运行时间为:', time.time() - thread_start_time) # 多线程的运行时间为: 2.7849910259246826