一、简介
xpath作为对网页、对xml文件进行定位的工具,速度快,语法简洁明了,在网络爬虫解析内容的过程中起到很大的作用,除了xpath的基础用法之外(可参考我之前写的(数据科学学习手札50)基于Python的网络数据采集-selenium篇),xpath中还存在着非常之多的进阶用法,本文将对笔者日常使用中积累的xpath进阶用法进行总结并举例说明:
二、xpath进阶用法
本文以http://quotes.toscrape.com/示例页面,首先抓取网页源码并利用etree解析:
import requests
from lxml import etree html = requests.get('http://quotes.toscrape.com/') tree = etree.HTML(html.text)
2.1 获取某一节点的上一级节点
在xpath中/..表示向上一级,这里我们用xpath按照下图中的路径提取a标签里的内容:
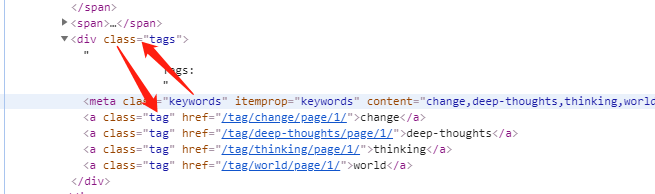
'''提取页面中符合下列位置规则的所有keyword''' tree.xpath("//meta[@class='keywords']/../a[@class='tag']/text()")
或者利用parent来向上一级跳转,效果是一样的:
'''提取页面中符合下列位置规则的所有keyword''' tree.xpath("//meta[@class='keywords']/parent::*/a[@class='tag']/text()")

2.2 定位指定属性以某个特定字符开头的标签
在xpath中有函数starts-with(属性名称,开始字符),可用于定位指定属性以某个特定字符开头的标签,如下例,实现与2.1中相同功能:
'''提取href属性以/tag开头的a标签内容''' tree.xpath("//a[starts-with(@href,'/tag')]/text()")
2.3 定位指定属性值包含特定字符片段的标签
在xpath中函数contains(属性名称,包含字符)可用于定位指定属性值包含特定字符片段的标签内容,比如我们想要找到所有text()内容中带有know的名人名言,就可以像下面这样做:
'''提取text()内容包含know的span标签对应的text()内容''' tree.xpath("//span[contains(text(),'know')]/text()")

2.4 匹配具有某属性的所有标签
比如说我们想获取页面中所有的href超链接,就可以用下面的方式:
'''获取整个页面内所有href属性''' tree.xpath("//@href")
2.5 同时定位多个内容
比如说我们想在一行代码里同时取得两种不同的规则下匹配的内容,可以在xpath语句中将不同的多个xpath语句用|连接起来,最终返回的结果在同一个列表里,所以使用这种语法时需要考虑取得的内容是否适合放在一起:
'''同时取得多个定位规则下的内容''' tree.xpath("//span[contains(text(),'know')]/text() | //span[contains(text(),'world')]/text()")

2.6 选取指定节点下所有子元素
有时候我们想要快捷的获取某一节点下一级所有标签的某一属性内容,可以使用child来表示下一级节点:
'''选取class为quote的div节点下所有span子节点的text()内容''' tree.xpath("//div[@class='quote']/child::span/text()")

当不指定标签名称而使用*代替时,代表匹配所有子节点:
'''选取class为quote的div节点下所有子节点的text()内容''' tree.xpath("//div[@class='quote']/child::*/text()")
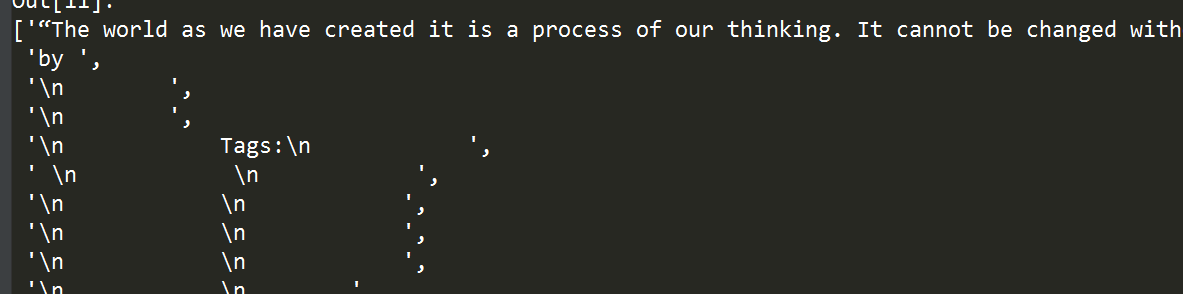
2.7 选取某一节点所有的属性值
有时候我们想要获取满足条件的节点下所有的属性值:
'''选取class为quote的div标签下所有的属性值''' tree.xpath("//div[@class='quote']/attribute::*")
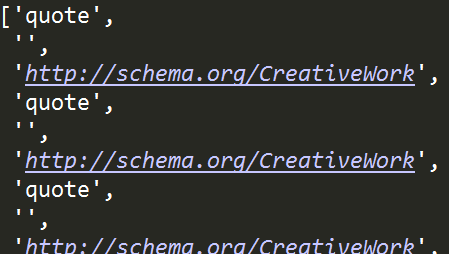
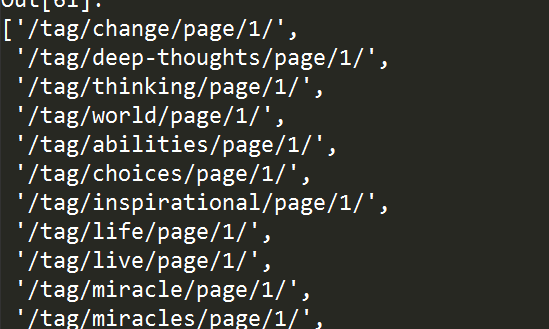
也可以指定要提取的具体属性值,如这里我们只提取href,只需要将*替换成href即可:
'''选取class为tag的a标签下所有的href属性值''' tree.xpath("//a[@class='tag']/attribute::href")
2.8 定位某一节点的祖先节点
比如我们想要获取class为keywords的meta标签之上所有标签的class属性内容,可以像下面这样:
tree.xpath("//meta[@class='keywords']/ancestor::*/@class")
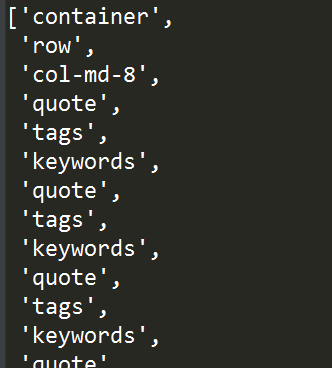
若想同时包含所有祖先节点及自己本身,则可使用ancestor-or-self:
tree.xpath("//meta[@class='keywords']/ancestor-or-self::*/text()")
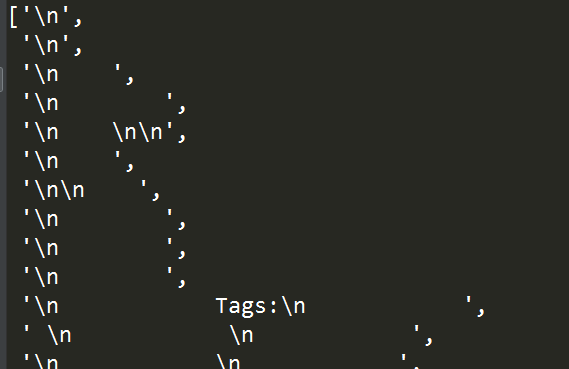
2.9 定位某一节点的后代节点
类似2.8,只不过这里我们来定位某一节点之下的所有后代节点,使用descendant:
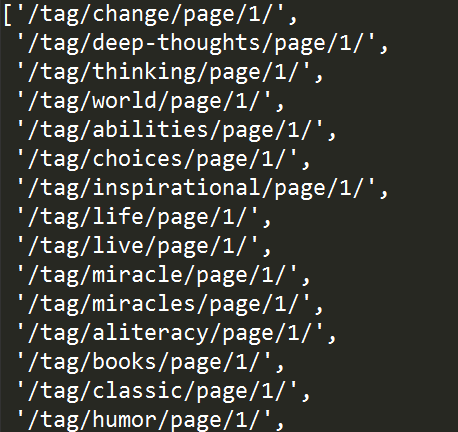
'''获取class为tags的标签下所有后代节点中a标签的href信息''' tree.xpath("//div[@class='tags']/descendant::a/@href")
2.10 条件与或非
在xpath中使用逻辑运算来定位的方法如下:
与:
'''定位class为text且itemprop为text的span标签''' tree.xpath("//span[@class='text' and @itemprop='text']/text()")

或:
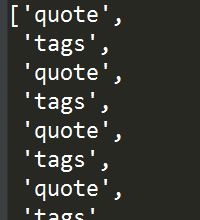
tree.xpath("//div[@class='quote' or @class='tags']/@class")
非:
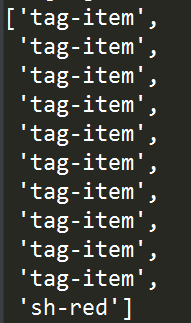
'''提取所有span标签class属性不为text的class属性值''' tree.xpath("//span[not(@class='text')]/@class")
2.11 选取指定标签结束之后的所有指定标签
在xpath中我们可以使用following来定位以某个标签在文档中的位置为起点的所有指定标签:
'''提取所有class为keywords的meta标签结束标签之后出现的标签a的text()内容''' tree.xpath("//meta[@class='keywords']/following::a/text()")

2.12 选取指定标签开始之前的所有指定标签
与following的功能截然相反,在xpath中使用preceding可以定位指定标签之前的所有标签:
'''选取body标签之前的所有标签的text()内容''' tree.xpath("//body/preceding::*/text()")

2.13 选取指定标签结束之后的所有同级指定标签
在following的基础上,若想定位所有指定标签之后且与指定标签同一级别的标签,可使用following-sibling:
'''提取所有class为keywords的meta标签结束标签之后出现的同级别标签a的text()内容''' tree.xpath("//meta[@class='keywords']/following-sibling::a/text()")

2.14 选取指定标签开始之前的所有同级指定标签
类似following-sibling,使用preceding-sibling可以实现相反的效果:
'''选取body标签之前的所有同级标签的text()内容''' tree.xpath("//body/preceding-sibling::*/text()")

2.15 对提取内容中的空格进行规范化处理
在xpath中我们可以使用normalize-space对目标内容中的多余空格进行清洗,其作用是删除文本内容之前和之后的所有s类的内容,并将文本中夹杂的两个及以上空格转化为单个空格,下面比较使用normalize-space前后对提取结果的影响:
'''清洗前''' tree.xpath("//p[@class='text-muted']/text()")

'''清洗后''' tree.xpath("normalize-space(//p[@class='text-muted']/text())")

使用normalize-space之后得到的结果更加的规整,可以提高爬取数据的效率。
2.16 在xpath中使用正则表达式
有时候一些任务情况比较特殊,在xpath中可能没有对应的函数直接可以使用,这时可以在xpath语句中穿插正则表达式,比如我们想要提取class为tag且href属性符合.*?-.*?page.*?规则的a标签中的href与text()内容,就可以在传入规范的正则命名空间,并利用match来匹配自定义的正则语句,如下:
tree.xpath(r"//a[@class='tag' and ns:match(@href, '.*?-.*?page.*?')]/text() | //a[@class='tag' and ns:match(@href, '.*?-.*?page.*?')]/@href", namespaces={"ns": "http://exslt.org/regular-expressions"})
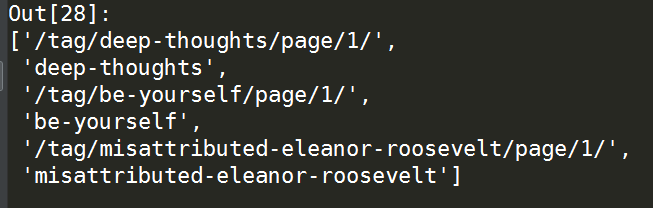
以上就是本文的全部内容,实际上xpath中还有更多方便使用的功能,本文仅根据笔者的日常使用积累做了片面的总结,如有笔误之处望斧正!