本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
在本系列之前的文章中我们主要讨论了geopandas及其相关库在数据可视化方面的应用,各个案例涉及的数据预处理过程也仅仅涉及到基础的矢量数据处理。在实际的空间数据分析过程中,数据可视化只是对最终分析结果的发布与展示,在此之前,根据实际任务的不同,需要衔接很多较为进阶的空间操作,本文就将对geopandas中的部分空间计算进行介绍。
本文是基于geopandas的空间数据分析系列文章的第8篇,通过本文你将学习到geopandas中的空间计算(由于geopandas中的空间计算内容较多,故拆分成上下两篇发出,本文是上篇)。
2 基于geopandas的空间计算
geopandas中的矢量计算根据性质的不同可分为以下几类:
2.1 构造型方法
geopandas中的构造型方法(Constructive Methods)指的是从单个GeoSeries或GeoDataFrame中创建新的矢量数据的过程,譬如早在系列第一篇文章数据结构篇中就介绍过的bounds、exterior、interiors、boundary、centroid、convex_hull、envelope等属性就基于GeoSeries计算出对应的边界、内外轮廓线、重心等新的矢量数据,这些本文不再赘述,下面我们来学习geopandas中常用的其他构造方法。
- buffer()
geopandas中的buffer()方法源于shapely,用于缓冲区的创建,这里给非GIS专业的读者朋友解释一下什么是空间意义上的缓冲区,缓冲区用于表示点、线、面等矢量数据的影响范围或服务范围,思想很简单,即为矢量数据拓展出一定宽度的边,图1展示了点、线以及面分别对应的缓冲区的示意:
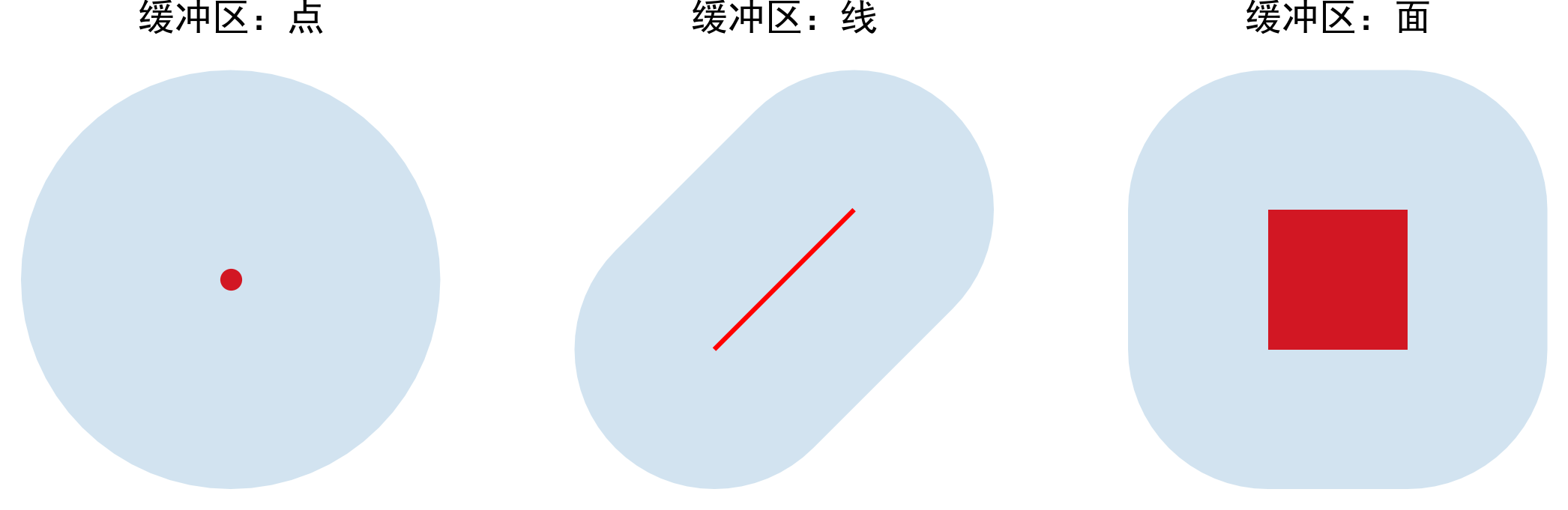
而创建缓冲区时也需要遵循一定的参数,从而决定怎样向几何对象外进行缓冲,geopandas中buffer()和shapely中的buffer()方法参数一致,主要参数如下:
distance:用于指定向外缓冲的距离,单位与矢量数据自带单位保持一致,在常见的投影坐标系如Web Mercator(EPSG:3857)下就是以米为单位,因此需要注意一定要先将矢量数据转换为合适的投影坐标系之后,再进行缓冲区分析才是合理有效的
resolution:因为在创建缓冲区时,对于构成矢量对象的每一个点,都会以对应点为中心向外创建半径=缓冲区距离的圆,而Polygon类型始终是由有限个点所构成的,因此需要近似拼接出圆形的轮廓,resolution参数就用于决定每个四分之一圆弧上使用多少段连续的线段来近似拼接以表示圆的形状,默认参数值为16,足以近似模拟圆面积的99.8%
下面我们分别对点、线以及面绘制不同resolution参数取值下缓冲前后的对比图:
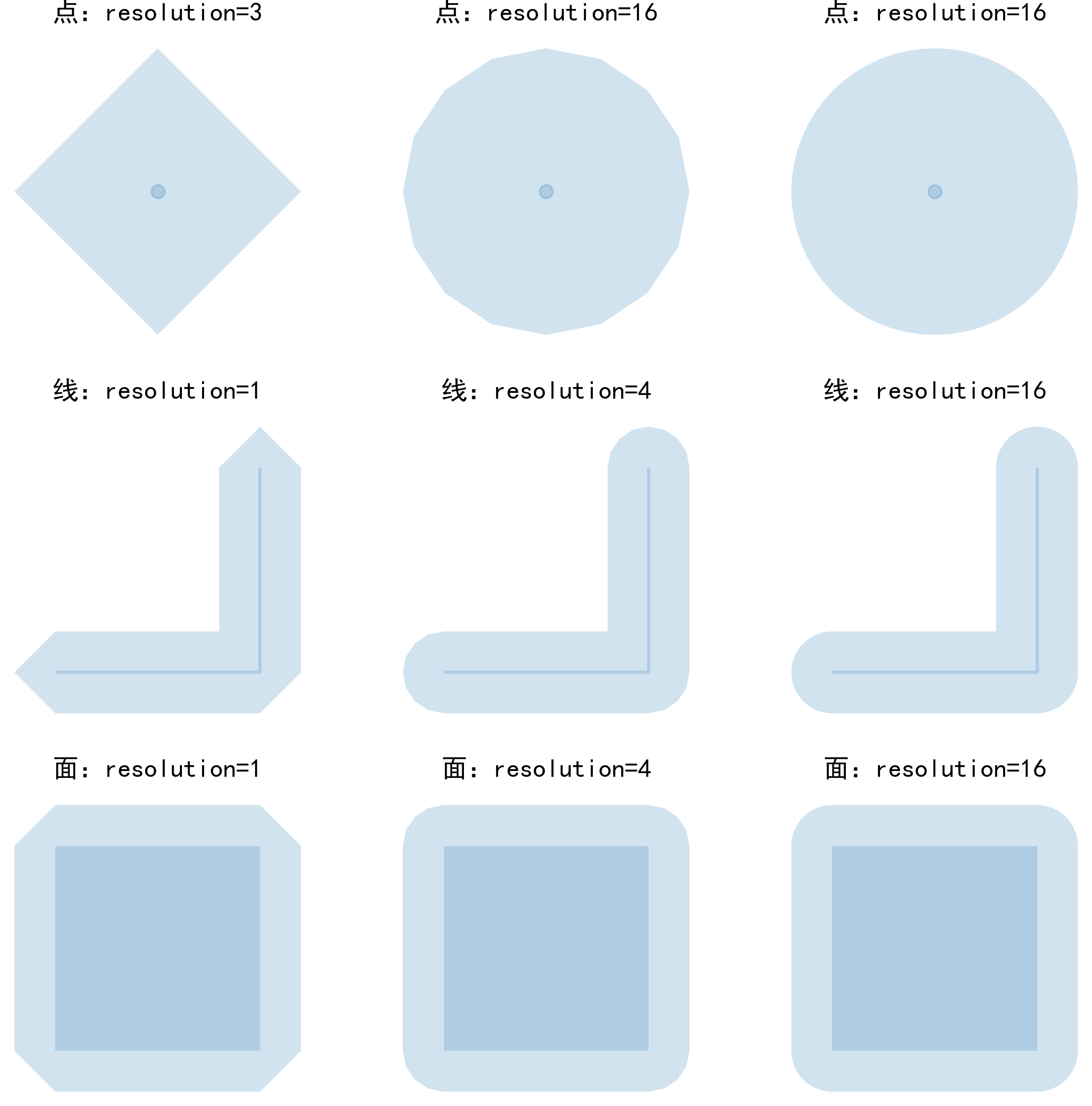
可以看出,resolution参数对最终形成的缓冲区形态影响较大,但默认16的参数下已经可以较准确地逼近圆形,且缓冲距离还可以设置为负数,即几何对象向内收缩:
# 分别绘制多边形、多边形正向缓冲区、多边形负向缓冲区
ax = gpd.GeoSeries([polygon,
polygon.buffer(distance=1),
polygon.buffer(distance=-0.25)])
.plot(alpha=0.2)
ax.axis('off')
plt.savefig('图3.png', dpi=300, bbox_inches='tight', pad_inches=0)

在本系列文章第一篇中介绍过shapely对矢量数据格式的合法性有一定规定,如多边形不能自交叉,可以通过is_valid()方法判断几何对象是否合法,而buffer()有一个隐藏功能就是其可以通过对非法的几何对象创建距离为0的缓冲区来修正构成矢量对象的点的不合理连接顺序,从而使得矢量对象变为合法的:
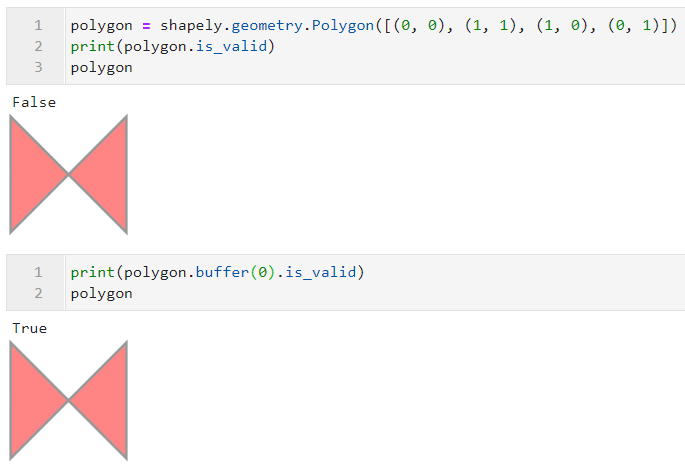
- total_bounds
total_bounds你应该不会感到陌生,在前面很多篇文章中我们都使用到它来限定图像的画幅范围,其返回依次记录了整列矢量数据所在最小矩形区域左下角x、左下角y、右上角x以及右上角y的numpy数组:
geom = gpd.GeoSeries([shapely.geometry.Point([0, 0]),
shapely.geometry.Point([0, 1]),
shapely.geometry.Polygon([(1, 1), (1.5, 1), (1.25, 1.25)])])
ax = geom.plot(alpha=0.4)
# 绘制total_bounds范围
ax = gpd.GeoSeries([shapely.geometry.box(*geom.total_bounds.tolist())])
.plot(ax=ax,
alpha=0.1,
color='red')
ax.axis('off')
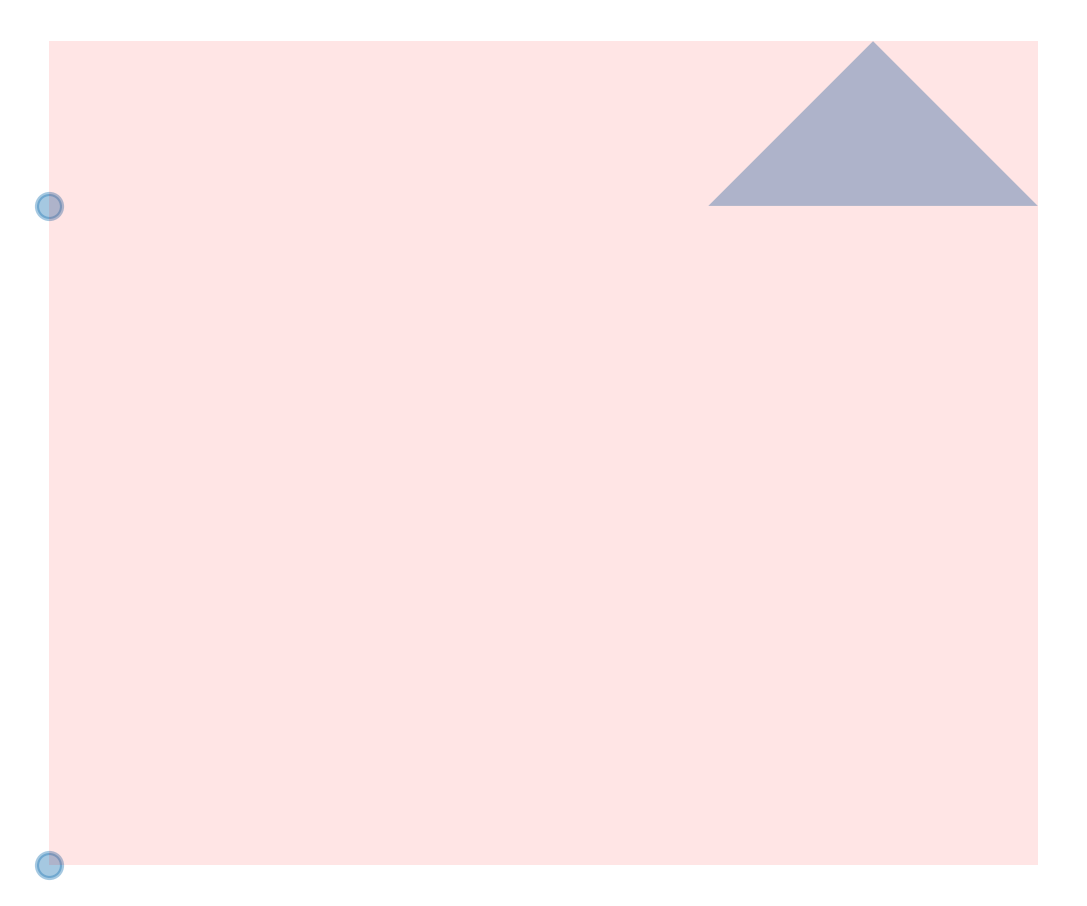
- simplify()
当原始的矢量数据因为形状复杂,包含的点较多时,会导致其文件体积较大,如果我们需要在在线地图上叠加它们,太大体积的矢量数据不仅会拖慢网络传输速度,也会给图形的渲染带来更大的压力,这时对矢量数据进行简化就非常有必要,geopandas中沿用shapely中的simplify()方法,帮助我们对过于复杂的线和面进行简化,和QGIS中简化矢量的方法一样,simplify()使用了科学的Douglas-Peucker算法,基于预先设定的阈值(epsilon),在递归判断的过程中删掉所有小于(epsilon)的点,其过程示意如图6:
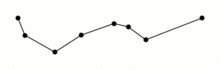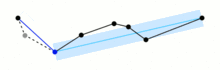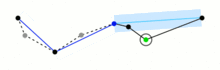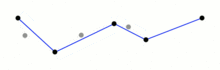
譬如我们这里基于-1到1之间的均匀分布,创建一条上下波动的折线,再用simplify()来简化它:
import numpy as np
import matplotlib.patches as mpatches
np.random.seed(10) # 固定随机数种子
# 创建线
line = shapely.geometry.LineString([(_, np.random.uniform(-1, 1)) for _ in range(10)])
# 绘制简化前
ax = gpd.GeoSeries([line]).plot(color='red')
# 绘制简化后
ax = gpd.GeoSeries([line]).simplify(tolerance=0.5).plot(color='blue',
ax=ax,
linestyle='--')
# 制作图例映射对象列表
LegendElement = [plt.Line2D([], [], color='red', label='简化前'),
plt.Line2D([], [], color='blue', linestyle='--', label='简化后')]
# 将制作好的图例映射对象列表导入legend()中,并配置相关参数
ax.legend(handles = LegendElement,
loc='lower left',
fontsize=10)
ax.set_ylim((-2.5, 1))
ax.axis('off')
plt.savefig('图7.png', dpi=300, bbox_inches='tight', pad_inches=0)
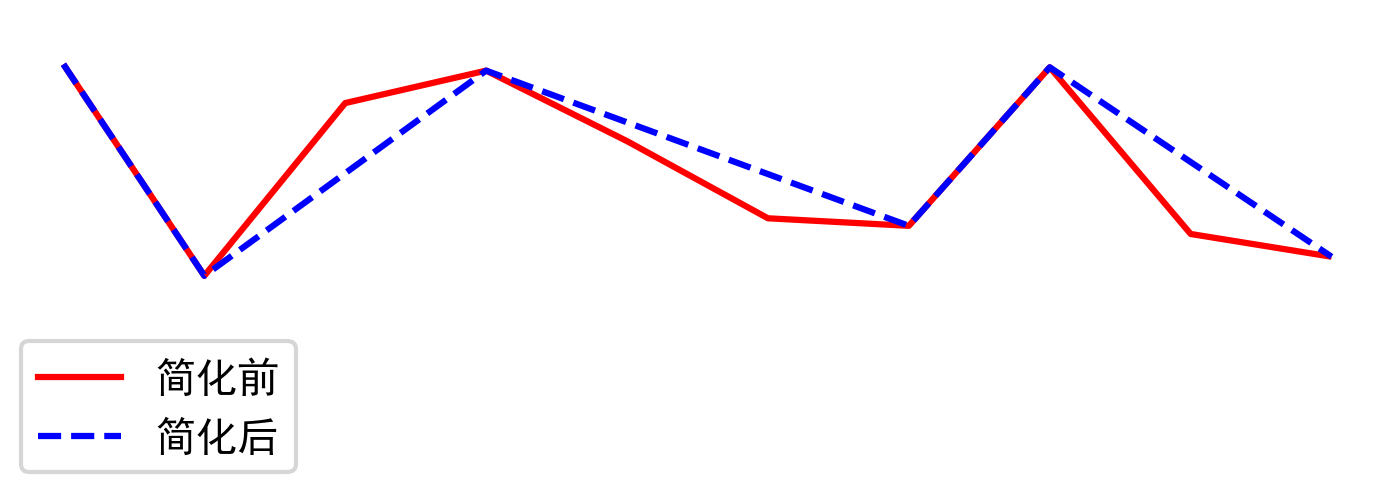
可以看到在预设的阈值下,对应simplify()中的参数tolerance=0.5,折线得到有效地简化,这在搭建web GIS平台要渲染矢量数据时非常有效,有效简化后的矢量数据可以在不损失太多视觉感知到的准确度的同时,带来巨大的性能提升。
- unary_union
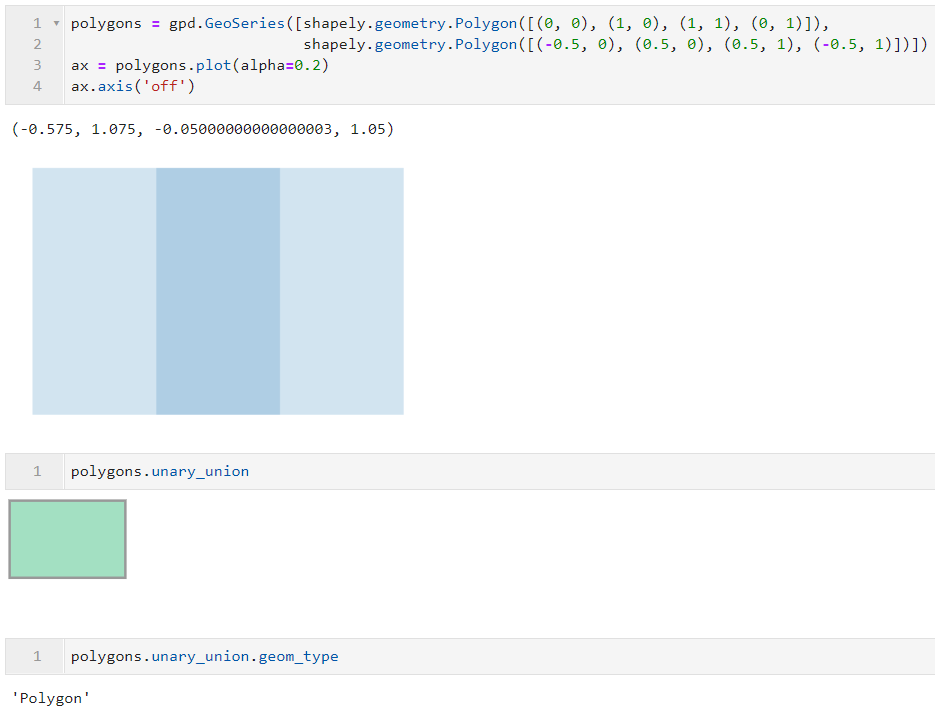
我们都知道,不管是GeoSeries还是GeoDataFrame,其每一行数据都代表独立的shapely矢量要素,而通过unary_union属性,我们可以将一整列矢量合并为单独的一个shapely矢量对象,从而方便我们进行一些其他的操作:
并且如果原始数据中存在互相存在重叠的矢量对象,通过unary_union之后,返回的shapely对象会自动对存在重叠的矢量对象进行融合,这一点可以方便我们的很多日常操作:
2.2 仿射变换
geopandas中封装了几种常见的仿射变换操作,如旋转等:
- rotate()
rotate()对矢量列中的每个要素分别进行旋转操作,其主要参数如下:
angle:数值型,用于指定需要旋转的角度
origin:用于指定旋转操作的中心,默认为
center,是矢量对象bbox矩形范围的中心,centroid表示矢量对象的重心,或者也可以传入格式如(x0, y0)的坐标元组来自定义旋转中心
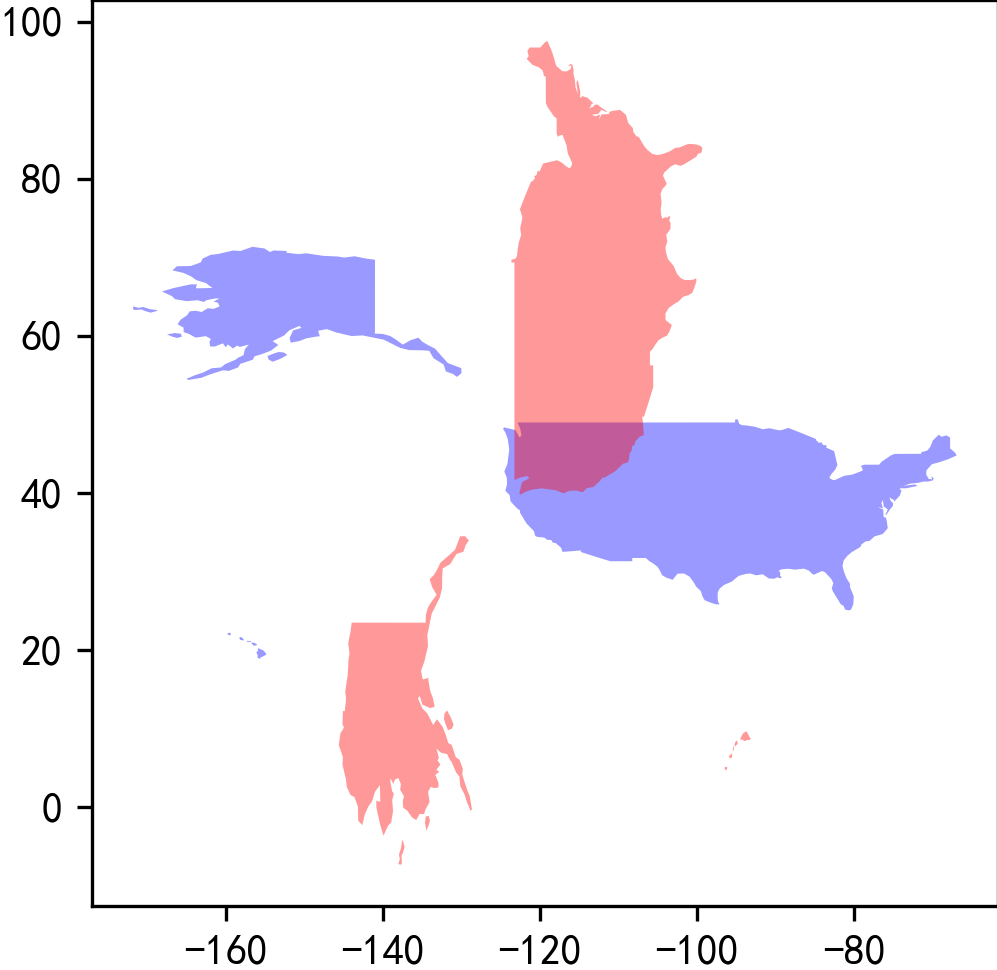
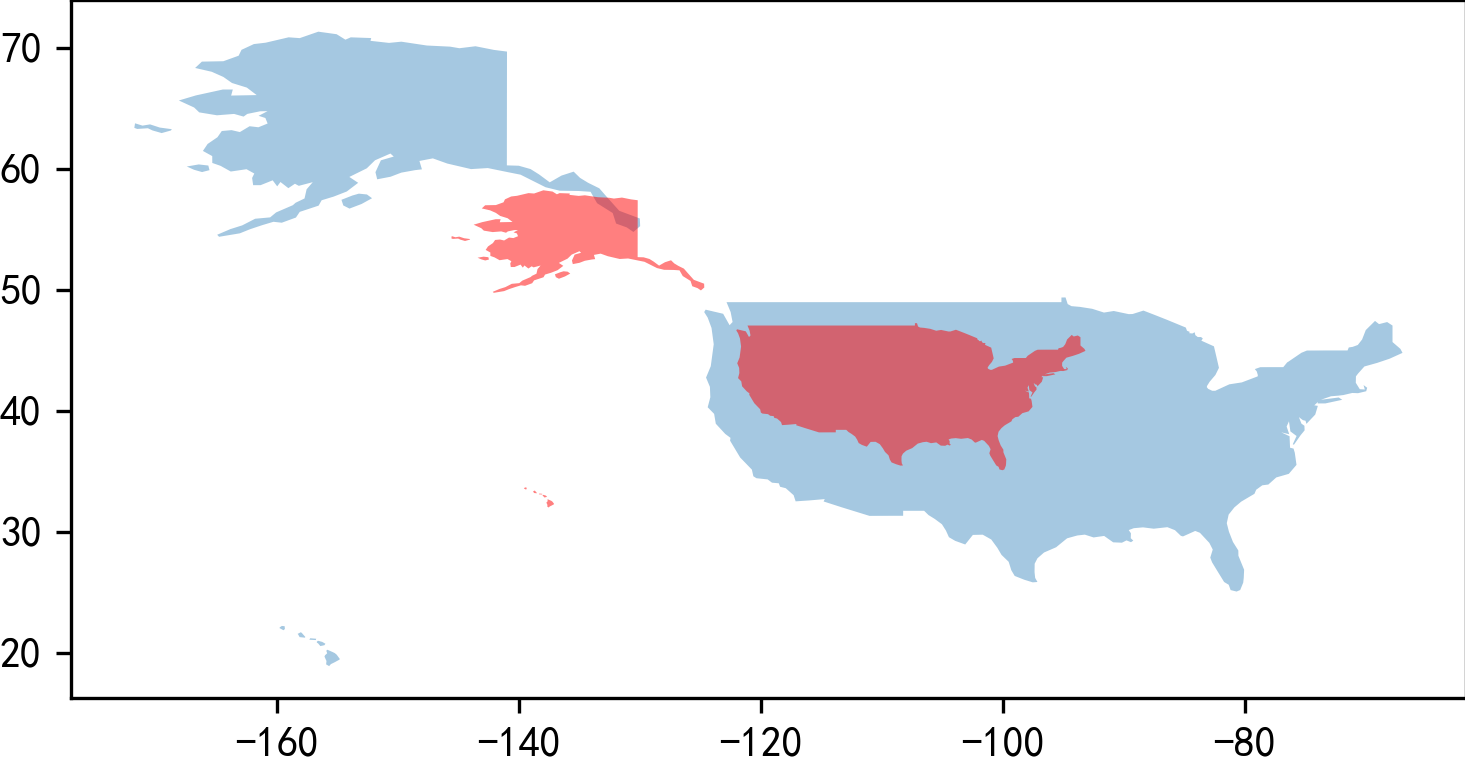
要注意的是rotate()旋转方向是逆时针,如下面的例子,红色是旋转90度之后的美国:
ax = world.query("iso_a3 == 'USA'").plot(color='blue',
alpha=0.4)
ax = world.query("iso_a3 == 'USA'").rotate(angle=90,
origin='center')
.plot(color='red',
ax=ax,
alpha=0.4)
plt.savefig('图10.png', dpi=300, bbox_inches='tight', pad_inches=0)
- scale()
scale()方法用于对矢量对象进行各个维度上的放缩操作,其主要参数如下:
xfact:数值型,表示对x维度上进行放缩的因子,默认为1即不放缩,小于1则缩放,大于1则放大
yfact:同xfact,控制y维度上的放缩因子
origin:同
scale()中的origin,用于确定缩放中心
如下面的例子,我们在x以及y维度上对美国进行0.5倍放缩,红色代表缩放之后:
ax = world.query("iso_a3 == 'USA'").plot(alpha=0.4)
ax = world.query("iso_a3 == 'USA'").scale(xfact=0.5, yfact=0.5)
.plot(color='red',
alpha=0.5,
ax=ax)
plt.savefig('图11.png', dpi=300, bbox_inches='tight', pad_inches=0)
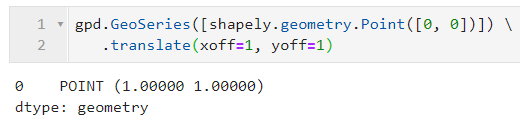
- translate()
translate()用于实现矢量对象的平移操作,其主要参数有xoff和yoff,分别控制在x维度和y维度上的平移距离(与对应的投影单位保持一致):
2.3 叠加分析
geopandas基于shapely中的overlay(),为GeoDataFrame赋予了同样的可以作用到整个矢量列的overlay(),使得我们可以对两个GeoDataFrame中全部的矢量对象两两之间进行基于集合关系的叠加分析(如图13):
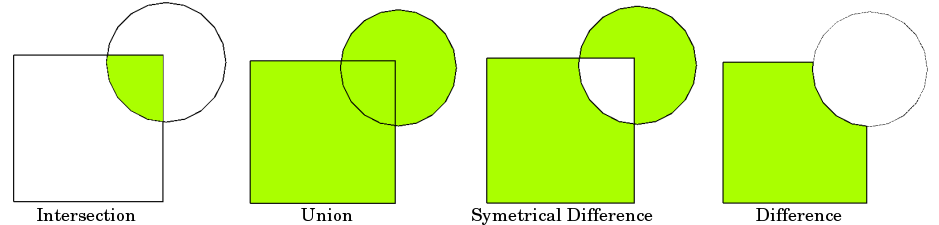
overlay()中的主要参数如下:
df1:GeoDataFrame,作为输入的第一个矢量数据集
df2:GeoDataFrame,作为输入的第二个矢量数据集
how:字符型,用于声明空间叠加的类型,对应图13,有
'intersection','union'、'symmetric_difference'、'difference',以及额外的'identity',他们之间的区别下文会进行详细介绍keep_geom_type:bool型,当df1与df2矢量类型不同时(譬如面与线数据之间进行叠加分析),用于决定在叠加分析产生结果中,是否只保留与df1矢量类型相同的记录,默认为True
首先我们构造示例矢量数据,以方便演示overlay()不同参数下结果的区别:
polygon1 = gpd.GeoDataFrame({
'value1': [1, 2],
'geometry': [shapely.geometry.Polygon([(1, 0), (3, 0), (3, 10), (1, 10)]),
shapely.geometry.Polygon([(6, 0), (8, 0), (8, 10), (6, 10)])]
})
polygon2 = gpd.GeoDataFrame({
'value2': [3, 4],
'geometry': [shapely.geometry.Polygon([(-1, 3), (-1, 5), (10, 5), (10, 3)]),
shapely.geometry.Polygon([(-1, 6), (-1, 8), (10, 8), (10, 6)])]
})
ax = polygon1.plot(color='red', alpha=0.4)
ax = polygon2.plot(color='grey', alpha=0.4, ax=ax)
ax.axis('off')
plt.savefig('图14.png', dpi=300, bbox_inches='tight', pad_inches=0)

接下来我们将其中红色部分对应的GeoDataFrame作为df1,灰色部分作为df2,来比较overlay()中不同参数对应的效果:
- how='union'
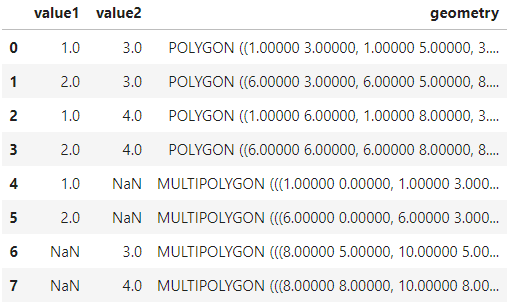
首先我们设置how='union',对polygon1与polygon2进行叠加分析:
overlay_result = gpd.overlay(df1=polygon1,
df2=polygon2,
how='union')
overlay_result
得到的结果如图15:
可以发现,有些行存在缺失值而有些行又是完整的,我们分别绘制出这两类记录行:
# 存在缺失值的行
ax = overlay_result[overlay_result.isna().any(axis=1)]
.plot(color='grey')
# 不存在缺失值的行
ax = overlay_result[~overlay_result.isna().any(axis=1)]
.plot(color='blue',
ax=ax)
ax.set_xlim((-1, 10))
ax.set_ylim((0, 10))
plt.savefig('图16.png', dpi=300, bbox_inches='tight', pad_inches=0)
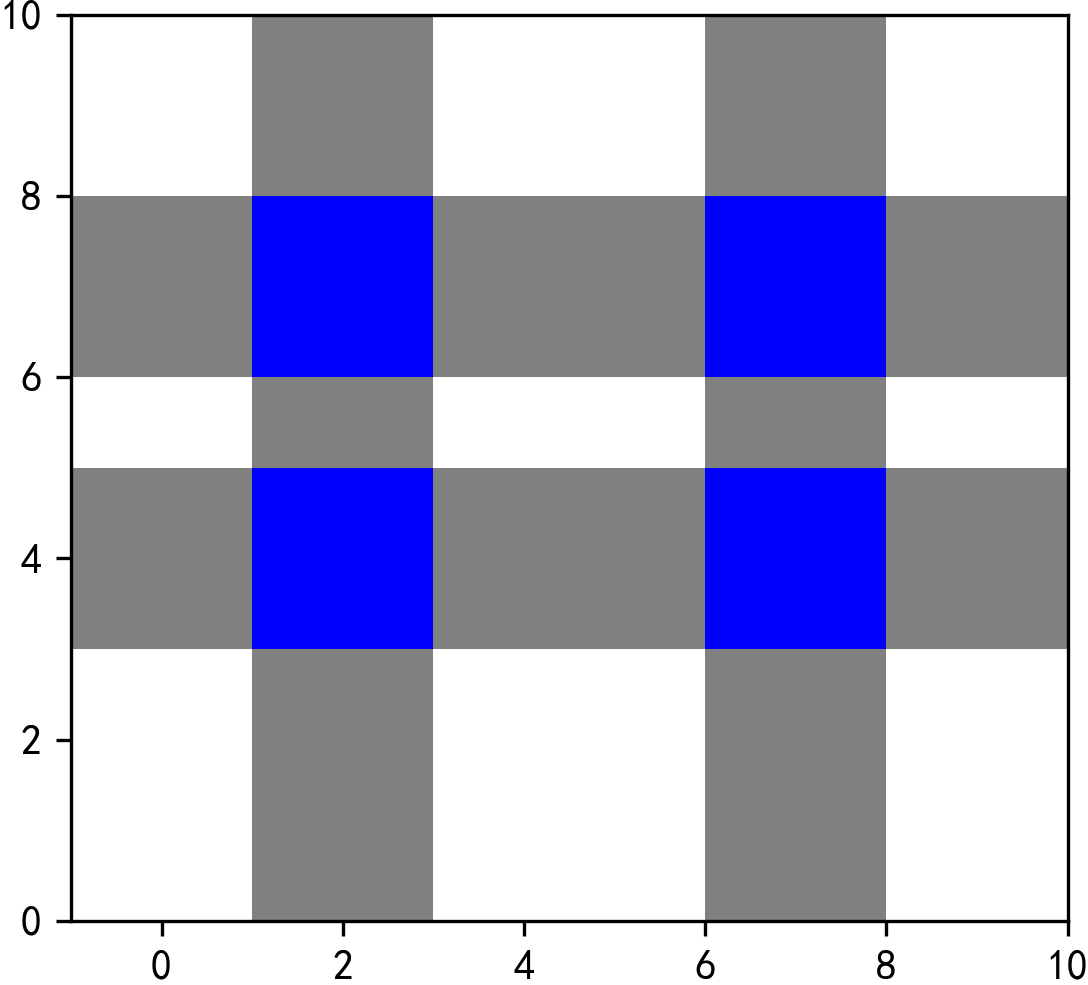
在how='union'下,叠加分析的结果会包含所有存在相交的部分,以及df1与df2各自剩下的不相交的部分,如图中蓝色部分即为df1与df2相交从而不存在缺失值的部分,而剩余的灰色部分因为没有相交,无法获得来自另一个GeoDataFrame的属性值,所以返回出来的结果会在对应的字段下填充为缺失值。
- how='intersection'
在how='intersection'参数下对polygon1和polygon2进行叠加分析:
overlay_result = gpd.overlay(df1=polygon1,
df2=polygon2,
how='intersection')
overlay_result

这时返回的结果中不再带有缺失值,因为intersection只保留df1和df2彼此相交的部分:
ax = overlay_result.plot()
ax.set_xlim((-1, 10))
ax.set_ylim((0, 10))
plt.savefig('图18.png', dpi=300, bbox_inches='tight', pad_inches=0)
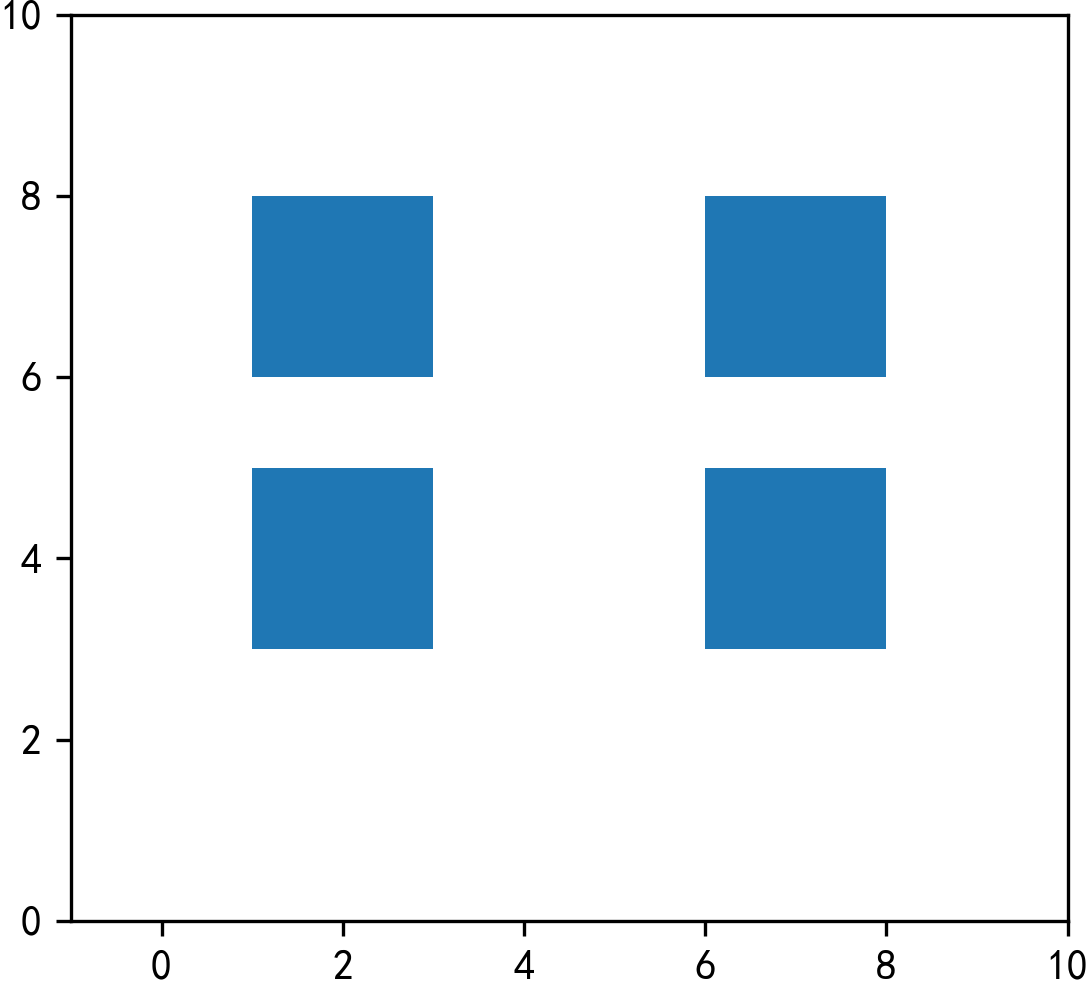
- how='difference'
在how='difference'参数下对polygon1和polygon2进行叠加分析:
overlay_result = gpd.overlay(df1=polygon1,
df2=polygon2,
how='difference')
overlay_result
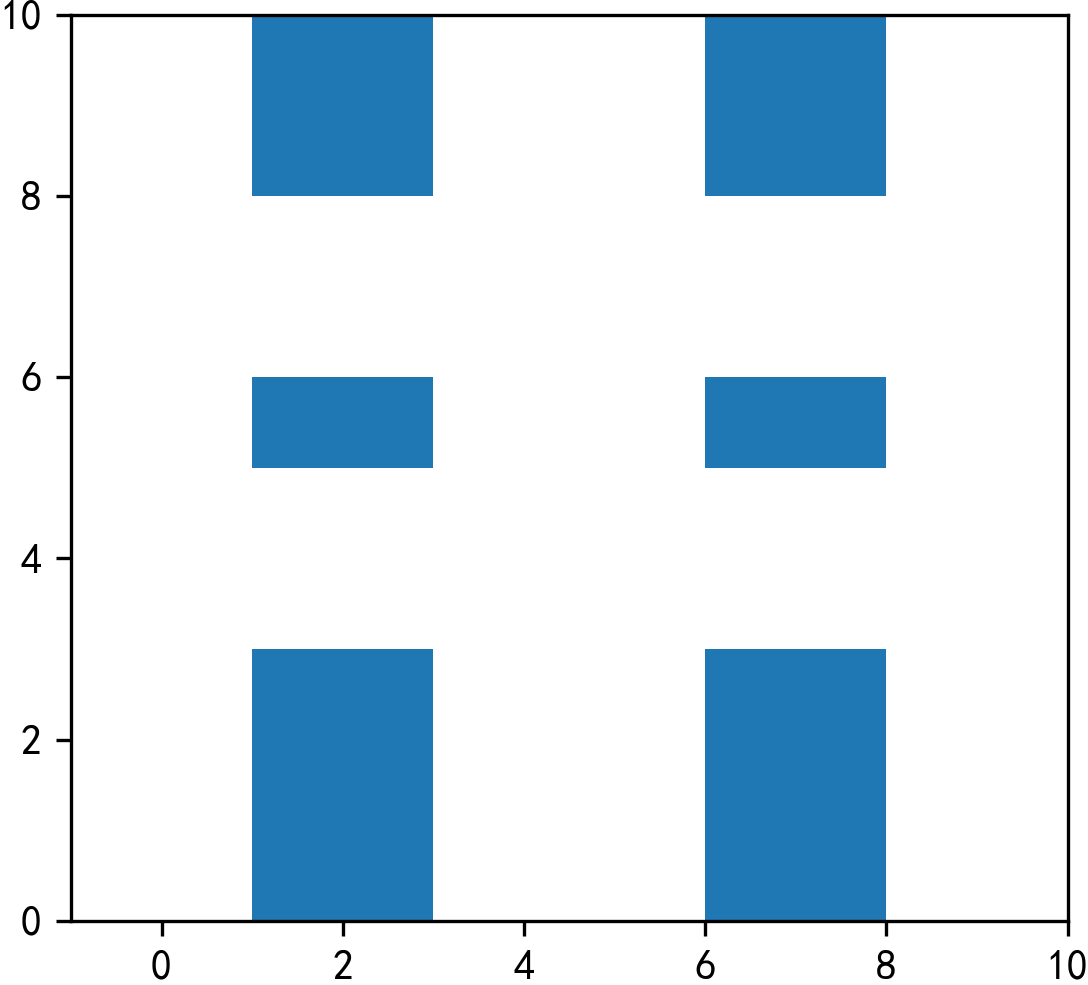
这时返回的结果中不再有value2字段,结合图13可以知晓在how='difference'下的返回结果与Arcgis中的擦除功能一样,返回的是df1中不与df2相交的部分,且以Multi的形式保留被切割开来的碎片矢量:
ax = overlay_result.plot()
ax.set_xlim((-1, 10))
ax.set_ylim((0, 10))
plt.savefig('图20.png', dpi=300, bbox_inches='tight', pad_inches=0)
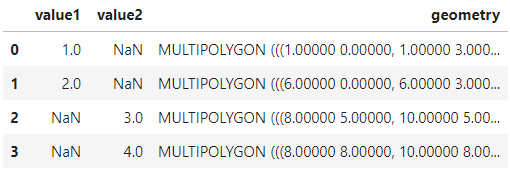
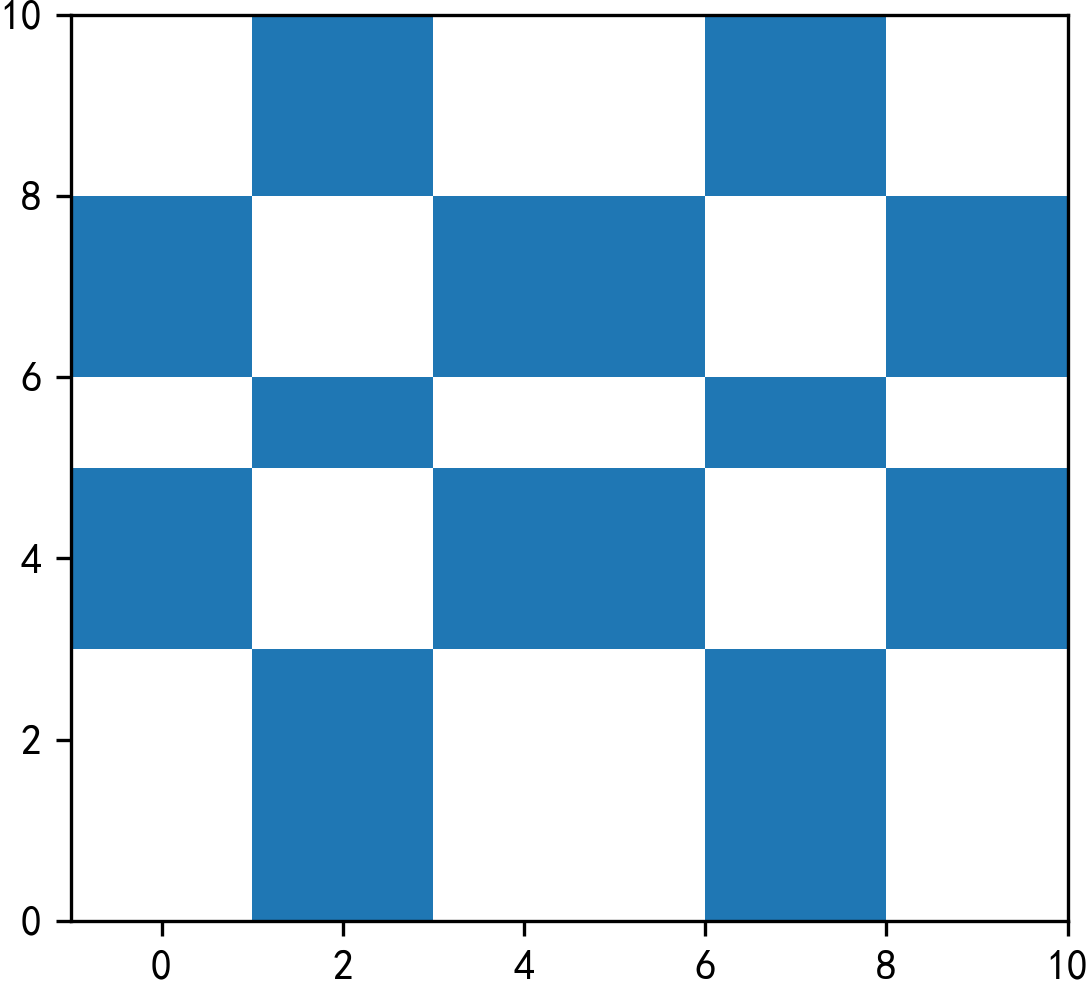
- how='symmetric_difference'
'symmetric的意思是对称的,而在how='symmetric_difference'条件下,与Arcgis中的交集取反功能相同,两个df中不相交的部分都会被返回:
overlay_result = gpd.overlay(df1=polygon1,
df2=polygon2,
how='symmetric_difference')
overlay_result
- how='identity'
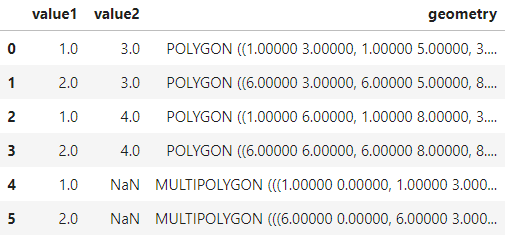
最后我们来看看how='identity',对应Arcgis中的标识功能:
overlay_result = gpd.overlay(df1=polygon1,
df2=polygon2,
how='identity')
overlay_result
为了方便理解,我们同样分别绘制出存在缺失值的行以及不存在缺失值的行:
# 存在缺失值的行
ax = overlay_result[overlay_result.isna().any(axis=1)]
.plot(color='grey')
# 不存在缺失值的行
ax = overlay_result[~overlay_result.isna().any(axis=1)]
.plot(color='blue',
ax=ax)
ax.set_xlim((-1, 10))
ax.set_ylim((0, 10))
plt.savefig('图24.png', dpi=300, bbox_inches='tight', pad_inches=0)
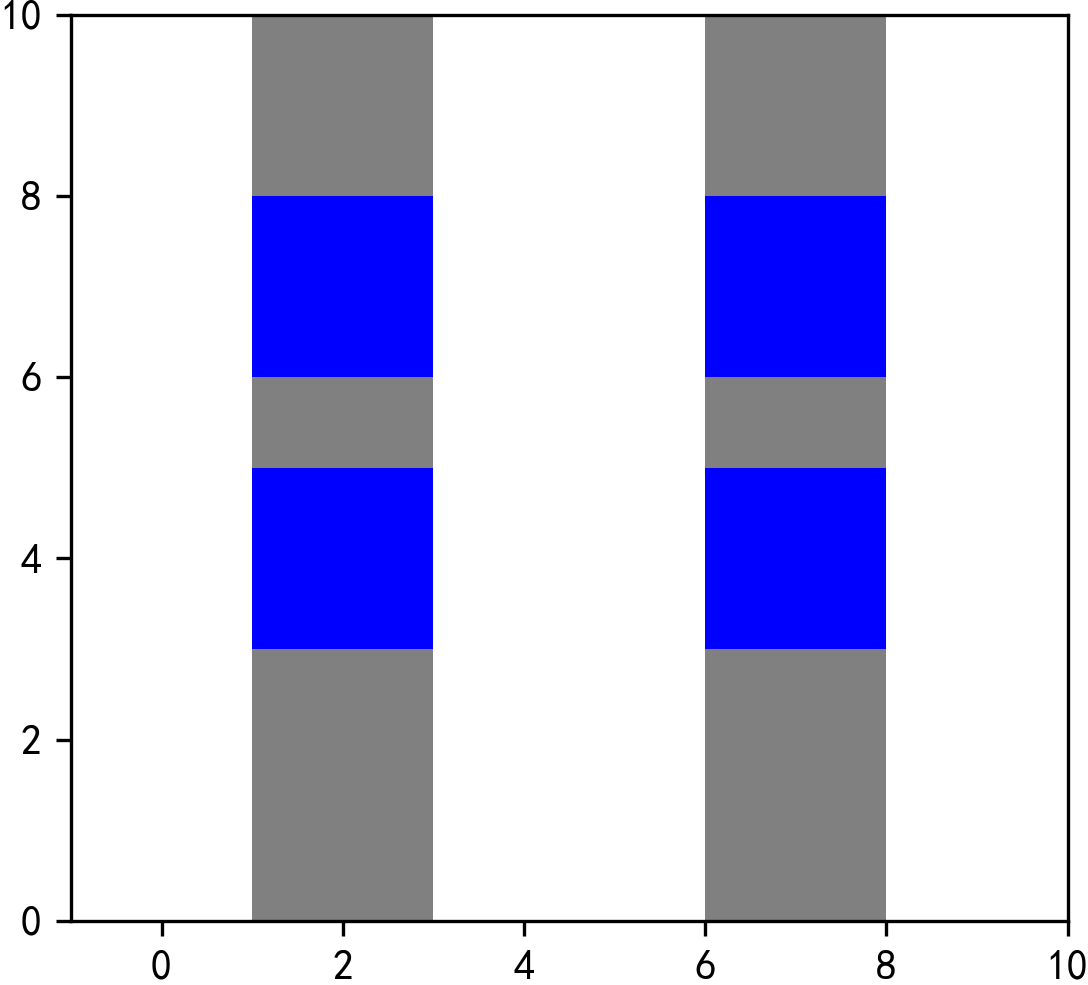
从图24中可以看出,在how='identity'条件下,所有df1中不与df2相交的部分,以及两者相交的部分作为返回结果,且每个相交的部分都变为单独的要素带上所有涉及的属性字段,而df1中不涉及相交的部分则仍然以Multi的形式被返回。
- keep_geom_type
有些时候我们需要做的不仅仅是面与面之间的叠加分析。比如在计算路网相关的指标时,我们可能会需要与目标区域存在叠置关系的部分路网,这就存在面与线之间的叠加分析。参数keep_geom_type就用于设定最终返回的矢量数据类型是否必须与df1对应的类型相同,下面我们构造示例数据来学习keep_geom_type参数的作用:
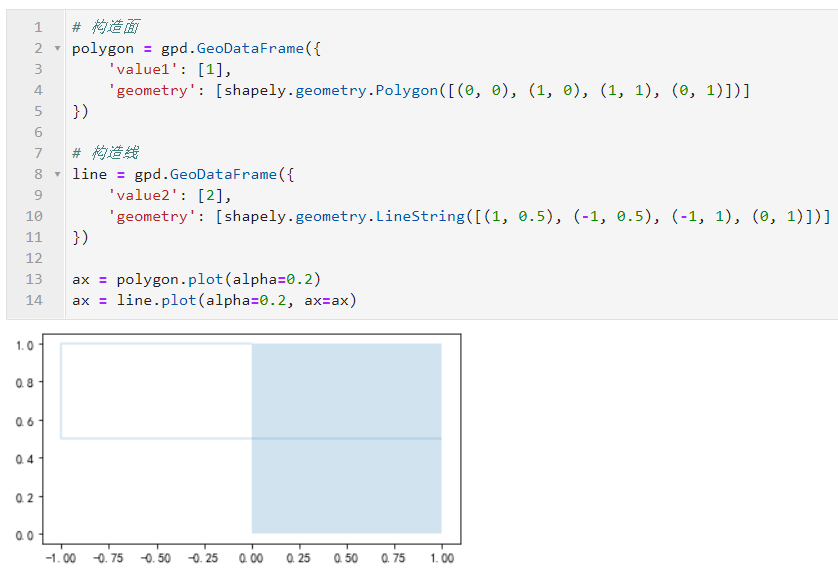
True和False下结果如图26所示:
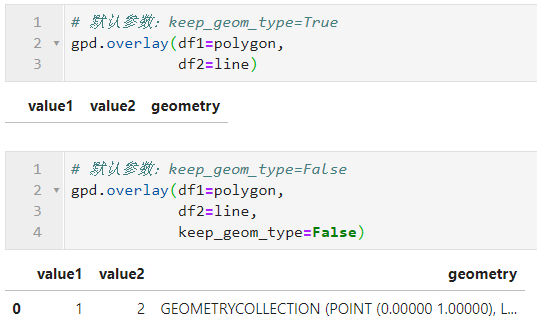
其中GeometryCollection类型代表多类型要素集合,比如这里叠加分析的结果包含了一条线和一个点:
在实际工作中,可以根据具体需要来选择使用对应的参数组合来进行叠加分析。
2.4 空间融合与拆分
有时候我们希望对矢量数据按照某些字段进行分组,再分别对非矢量列与矢量列进行聚合及合并,类似于pandas中的groupby.agg();而有些时候我们希望把矢量类型为Multi-xxx的记录行拆分成独立要素行,譬如将Multi-Polygon拆分成Polygon组成的若干行。通过geopandass中的dissolve()和explode()方法,我们就可以实现上述功能:
- dissolve()
dissolve()用于对矢量数据进行融合,可以理解为对矢量数据进行groupby+agg操作,即指定的单个或多个字段值相等的分到一组,对非矢量字段进行指定规则的聚合计算,对矢量列进行融合,其主要参数如下:
by:用于指定分组所依据的字段,单个字段传入列名字符串,多个字段传入列名列表
aggfunc:对分组字段外的其他非矢量列采取的聚合方式,与
pandas中的agg一致,默认为first,也可以像agg那样传入字段和函数一一对应的字典来分别聚合不同的列as_index:bool型,用于设定是否在返回的结果中将分组依据列作为索引,默认为True
我们以world数据集为例,为了方便演示我们首先新增字段less_than_median_gdp,用于判断对应的国家GDP是否小于世界中位数水平:
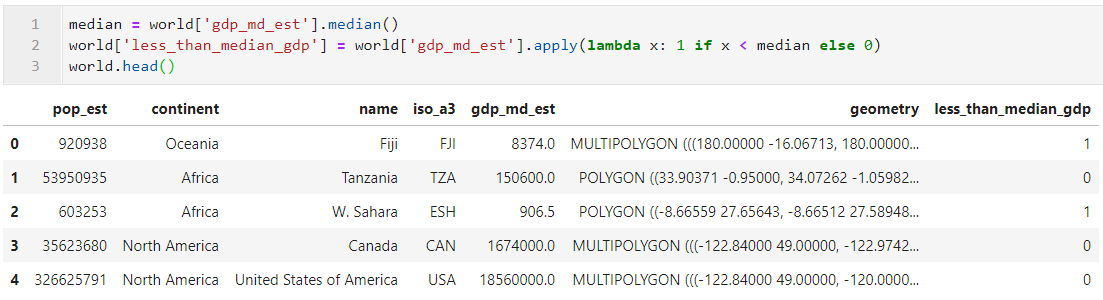
接着我们以国家对应大洲列continent为分组依据,并对人口和GDP列进行求和,如图29所示,在非矢量列得到对应的聚合计算之后,矢量列也被融合为Multi-Polygon:
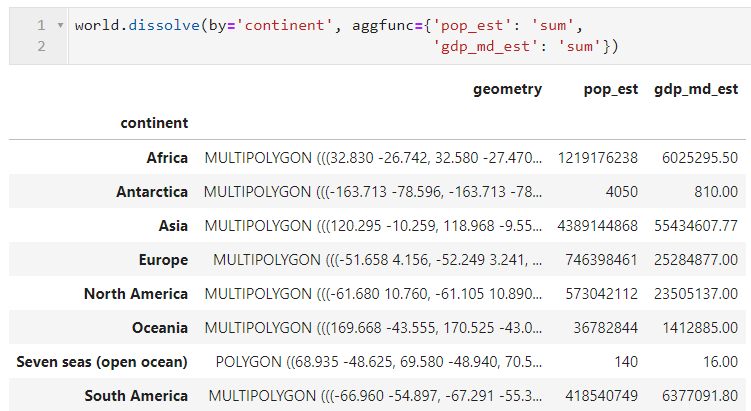
- explode()
explode()功能与dissolve()相反,用于将Multi-xxx或Geometry-Collection类型的数据从一行拆分到多行,如下面的例子,非矢量字段会自动填充到每一行:
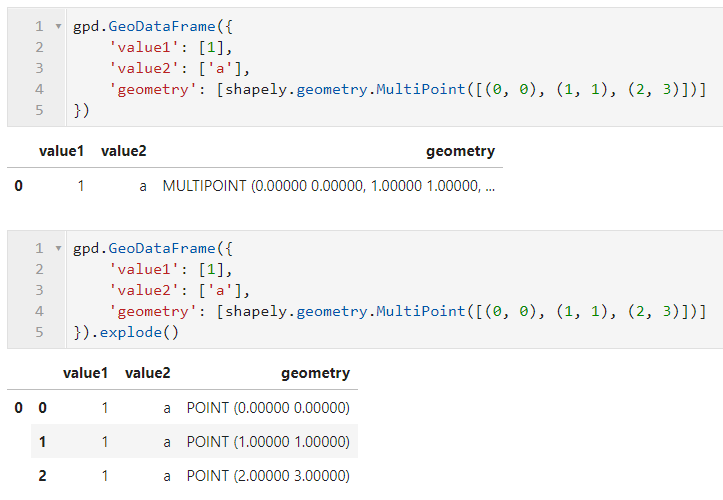
以上就是本文的全部内容,关于更多geopandas中空间计算的内容,我们将在下一篇中继续讨论。