一、简介
循环神经网络(recurrent neural network,RNN),是一类专门用于处理序列数据(时间序列、文本语句、语音等)的神经网络,尤其是可以处理可变长度的序列;在与传统的时间序列分析进行比较的过程之中,RNN因为其梯度弥散等问题对长序列表现得不是很好,而据此提出的一系列变种则展现出很明显的优势,最具有代表性的就是LSTM(long short-term memory),而本文就从标准的循环神经网络结构和原理出发,再到LSTM的网络结构和原理,对其有一个基本的认识和阐述;
二、关于基本的RNN
基本结构:
循环神经网络又叫递归神经网络,因为其向前传播过程中折叠了一个循环计算的重复结构,这里我们先观察一个经典的动态系统,即:
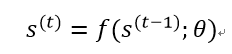
其中s(t)为系统在t时刻的状态,和传统时间序列分析中的模型类似,在有限时间步τ的条件下,经过τ-1次上述展开过程就可以完全展开这个有限时间步内的过程,以τ=3为例:
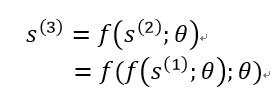
上述过程可以用图论中的有向无环计算图来表示:

每一个时刻的状态都经由函数f映射到下一个时刻,而这是仅有自我状态驱动的系统,我们再考虑引入外部信号x(t)的系统:
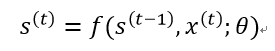
即对于一个序列,其当前状态包含了过去所有时刻状态对其的影响,以及当前时刻外部信号的影响,我们的循环神经网络就是建立在上述知识的基础上,因为RNN中的状态即是网络的隐藏单元,我们用h来重新定义上式:

则一个最简单典型的RNN架构如下(未包含输出层部分),左边是循环计算部分未展开的结构,右边是展开后的结构:
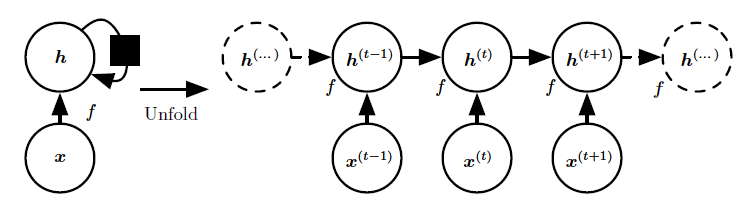
其中左边的黑色方块表示单个时间步的延迟,可以类比时间序列分析中的n阶延迟,接着我们添加上输出层以及不同层之间的连接权信息,便得到下面这张经典RNN的结构示意图:
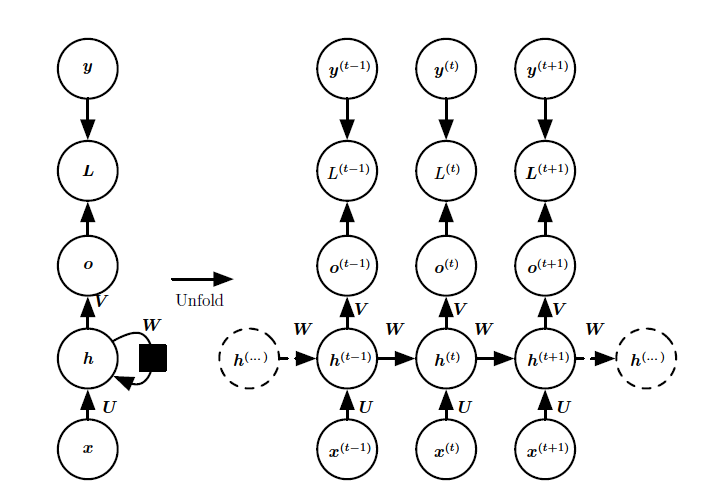
由上图,在这个将输入序列x映射到输出值o的过程中,层与层之间通过连接权进行映射,并在功能神经元内部进行激活(通常是tanh激活函数),其中在分类任务时,h到o的映射由softmax完成,接着与真实的label,即y进行比较计算出损失L,总结一下经典RNN结构的特点;
1、每个时间步完成后都有输出,且时间步之间有按照时序顺序的循环连接,这也决定了RNN的向后传播过程不同于传统BP算法可以并行,RNN在一个未展开的时间步内部只能按顺序调整参数,即通过时间反向传播算法(back-propagation through time,BPTT);
2、不同的任务决定了不同的输出方式,如翻译就是序列到序列,分类或时序预测就是在最后一次得到输出;
3、参数共享
前向传播:
在输出为离散的情况下,上述经典RNN的前向传播过程如下:
1、时刻t的隐藏状态h(t):
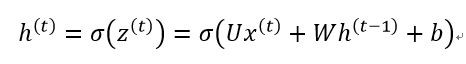
2、时刻t的输出o(t):
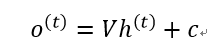
3、时刻t的预测类别输出:
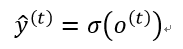
4、损失函数,离散分类任务时通常为对数似然函数,连续预测任务通常是均方误差:
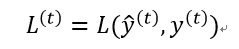
三、关于LSTM
RNN在实际使用过程中,在处理较长序列输入时,难以传递相隔较远的信息,究其原因,我们先回想一下RNN的基本结构,其真正的输入有两部分——来自序列第t个位置的输入xt,和来自上一个隐层的输出ht-1,考虑隐层的信息往后传导的过程,这里令RNN中隐层连接下一个时刻隐层的权重为Whh,不考虑每一次隐层的非线性激活时,从初始状态h0到第t时刻状态ht,其信息传递的过程如下,其中对Whh的连乘部分做了特征分解:

当特征值小于1时,连续相乘的结果是特征值向0方向衰减;当特征值大于1时,连续相乘的结果是特征值向∞方向增长。这两种情况都会导致较远时刻状态的信息消失(vanish)或爆炸(explode),无法有效地反馈到t时刻;
上述情况导致的结果是我们的RNN网络难以通过梯度下降进行有效的学习,为了有效地利用梯度下降法来进行学习,我们需要控制传递过程中梯度的积在1左右,目前最有效的方式是gated RNNs,而LSTM就是其中的一个代表;
再次回想前面的RNN中的t时刻状态计算过程,其中σ为激活函数,通常为tanh:

而LSTM就是在RNN的基础上施加了若干个门(gate)来控制,我们先看LSTM的示意图即网络结构中涉及的计算内容,然后在接下来的过程中逐一解释:
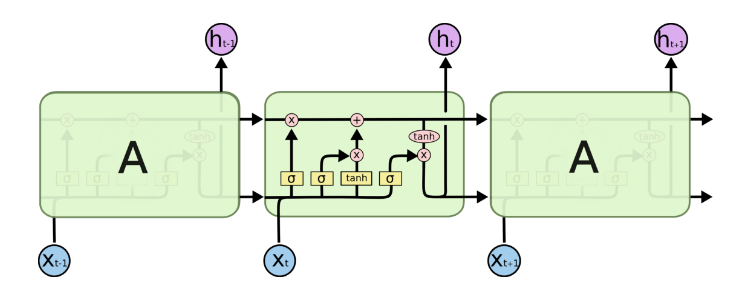

且这些门均由Sigmoid型函数激活,具体如下:
1、遗忘门(forget gate)

这个gate控制对上一层的cell状态ct-1中的信息保留多少,它流入当前时刻xt与上一时刻传递过来的状态ht-1,通过对应的所有事件步共享的权重Wxf,Whf,偏移bf来进行线性组合,并通过sigmoid函数进行处理后得到当前时刻遗忘门输出ft,即下式: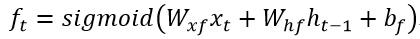
2、输入门(input gate)

输入门控制了有多少信息可以流入cell,即上图中it的部分(所谓at的部分其实就是经典RNN中的输入层)它对应了下式:
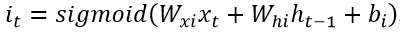
3、输出门(output gate)
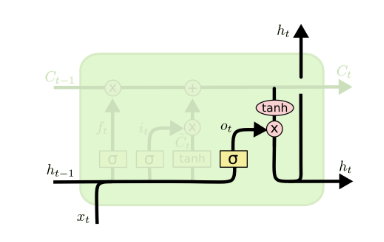
输出门顾名思义,控制了有多少当前时刻的cell中的信息可以流向当前隐藏状态ht,与经tanh处理的ct进行哈达玛相乘得到ht,对应下式:

4、t时刻ct的更新

如上图,我们这一个时间步的cell中的ct为遗忘门处理后的上一时刻中的ct-1、输入门控制流入的信息it、经典RNN中的输入层信息at等信息的汇总,计算过程对应着:
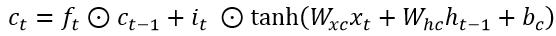
5、t时刻ht的更新

如上图所示,LSTM新加的这些结构的作用就是为了调整ht使其在长时间步的传递过程中减少信息失效的可能,对应的新的ht:
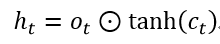
而其他部分的计算内容就同RNN,即LSTM就是一个扩充了数倍调整过滤参数的RNN,以上就是本篇文章的基本内容,如有笔误,望指出。
参考文献:
《深度学习》
《Yjango的循环神经网络》https://zhuanlan.zhihu.com/p/25518711