自己的另外一篇:稳定性 耗时 gc 过长问题排查 和工具 http://www.cnblogs.com/fei33423/p/7800395.html
老的思考:稳定性 监控 业务后期 - 架构师 https://www.cnblogs.com/fei33423/p/7169590.html
总结:
新的指标概念: 1. cpu 节区间 2. 耗时*请求量 3. 耗时 diff*请求量/平均耗时*总>1/5 provider 请求量 4.对方 provider (rpc 或者是)耗时统计 5.provider 线程池满拒绝异常 5. consumer- provider 耗时- ping 耗时(这样雪崩时,本系统不会报错) 6. 类似 traceId,有个全局的traceMethod. 这样就能知道是谁调用过来的.
层级概念:
去除报警指标: 1. provider 耗时,errno异常 2. consumer errno [下游系统provider_errno=consumer_errno] 3.consumer 耗时异常 4.割裂 traceId 的统计是无效的. 丢弃小米监控系统. 还要根据分位, 正态分布叠加还确立定位合适的traceId.
动静,统计和 case 结合.
指标: 耗时,请求量,错误量
静: 绝对值.
动: 环比,同比
报警因果推断. 1. 只要有 trace 分段了. 耗时因果推断就简单了. 2.请求量 只要有了 traceMethod 就知道diff来源了. 3. 有个 traceError 就知道 appName_errCode
背景介绍:
一次雪崩时: 查问题毫无头绪,到处都是抛错. 查来查去可能都是某个系统的问题. 那个系统呢,抽样查很多 flag ,很多都是调用外部的问题.
原因: 下游系统从1ms 变成2ms, 就引发雪崩了. 说明该接口调用占比占整个入口占比的60%了. 调用该接口又用了一个无限队列线程池,快饱和了, 2倍后饱和,排队, 最终导致 dubbo provider 的线程池满. 导致其他接口无法调用该核心系统.
后期防范: 系统占比较高的耗时节区间,需要特别注意. 排名: 耗时段的耗时 diff*次数/总 provider 耗时. [耗时节区间段概念见下文]
问题梳理+案例说明:
核心问题(梳理完知识体系后想到的): 带有 flag 的监控数据缺失.现有监控数据擦除了大量信息.
新方案知识体系:
节区间:
zipkin 监控中的节区间.
复合节区间: 是指包含多个原子节区间的节点. 例如dubbo provider . 注意复合节区间的监控统计是宏观上考察用的,对问题分析排查无太大的意义.还有就是 consumer 的耗时. 这个耗时首先要关注provider 提供方的耗时,对方也是高的,那就是对方的责任.如果对方低,我方高,那么就应该好好研究研究了.
对于 consumer 还有外部 io 节点: 1. 耗时增加异常 2. 耗时不增加但是非 success 调用.(fast-failure)
节区间上承载的的信息种类(zipkin只有耗时信息):
1. 耗时
2. 接口调用量.
3. error code .
其他为用于分析原因的异常:
1. 数量. cpu 占比 . 磁盘 io 数量. 网络 io 数量. 当时 swap 次数.
异常比较方式:
1. 同比
耗时多用同比,
2. 环比
数量多用环比.
3. 绝对值
调用量远超过业务量,耗时也是远超正常值. cpu : 10ms consumer: 5000ms
统计层级:
1. 接口层级
模块交互时的相关问题
两个 rpc 调用之间包含中间件代码,网络io.
常规日志手段无法检测的
1.1 隐匿在接口层,但是你获取不到时间的.例如: dubbo单连接复用 dubbo 连接池分发耗时. 可以通过代码注入改造. 现有的 java 性能耗时分析工具已经很多.
接口监控可能需要改造的点,获得更多的节区间数据:
- 中间件间切面flag 日志
- 系统级切面 flag
- 中间件和系统级日志查看. 如果未收到监控系统中,就需要专家主动查看. 监控 list check表单.
- gc日志监控
2. 比接口层级还低的层级. 只能通过非业务系统来调用监控了.
比如通过ping,得到网络耗时情况. route .
低层级的影响的是全局. 如果有这些数据,就可以反证全局影响不是这些因素照成的.有些"节区间"包含了 网络传输 和 中间件等无法监控统计的点.
2.1 基于 byte 的 传输. 通过纯净无影响的ping来确定网络耗时. jvm 内,jvm 外. 2种. jvm 外的统计都有运维自己搞定.
2.2 基于 byte 的 cpu 执行. 通过一段每隔10毫秒执行一次的纯净. jvm 内,jvm 外. 2种.
2.2 基于 byte 的文件 io. 通过一段定时写入磁盘的 logger + file 操作.来统计纯洁的 io耗时表现. jvm 内,jvm 外. 4种.
2.3 基于 byte的netty 的粘包,拆包.
监控展现:
报警展现(有最小流量限制,统计样本有限不报警):
两种展现类型 1.耗时异常展现 2.数量异常展现:
展现方式
拓扑图展现法:
整体拓扑图节区间( 可以用TWaver实现 )展现. 有节区间报警就显示在某个应用上,点击进去进入下一层级拓扑图. 如果是 consumser 的调用发起节区间. 那么就展现对应的机器连 接拓扑图.
任何zipkin节区间都能属于最终整体拓扑图的点或者线.
列表展现法: 从大到小. 可以层层点入( 如果拓扑图有难度的话 ):
接口级的展现: 如果节区间报警,把对应的 provider 的整体节区间展现出来. [对应拓扑图方式的是你得知道这个报警是属于哪个拓扑节点的]
从面到点展现报警图. 点击某个最细粒度监控节后,
1. 纵向对比,和自己比, 展现与之相关的各种统计数据,同比,环比量.
2. 横向对比 和别人比, 同level 的其他节区间情况. 即同一个节点的其他 cpu 区间. [可能有些流量变化不大,但已经到了边界点, 要看具体代码来理解思考. 是否有阻塞,排队等.]
note: 拓扑报警切记对复合节区间报警. 这是目前现有报警系统的大坑.
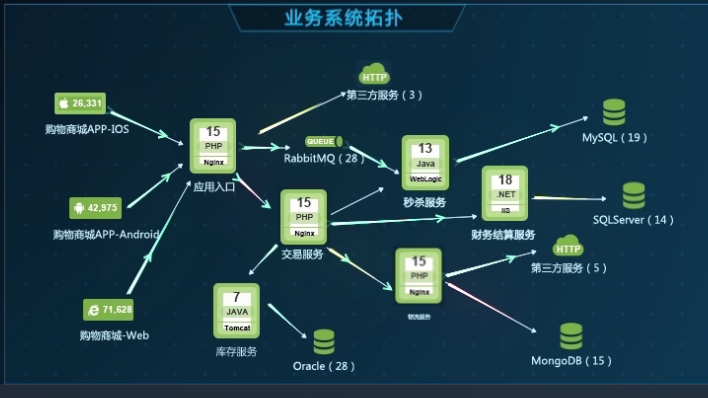
如何打印 zipkin 日志:
1. 如果接口种不同的参数导致的耗时差别很大. 那么就需要根据不同的 type 来打印不同的日志,区分 consumer 接口.
2.
Q&A
1. 如果遇到某个接口本身不同的分支导致耗时差别很大怎么办?
1.1 可以通过接口参数区分出来
1.2 无法通过接口参数区分. 不同的 userId 有不同的参数. 这种就没办法了. 不过问题也不是很大,只要数据量够大,平均值就比较稳定. 一旦异常,也会影响相关问题.
2.如何确定两个节区间是相同的节区间?
例如 a b c c d 和 a c d . 这种需要技术处理内在子序列的概念. 其中 cd 就是重叠的. 或者大序列严格相等,子节区间从认为是相同的子节区间.这个不太好. 特别是在 service 层也打上 zipkin 标记的时候.
监控衍生产品:
1. 通过现有数据库
2. 通过状态变更时的日志
(日志,采集,展示)监控,参照系异常抽取,关联清洗,优化,报警,报警关联清洗,定位五部曲. [目前监控系统,在日志,关联清洗上是缺失的]
从表到里的分析过程.
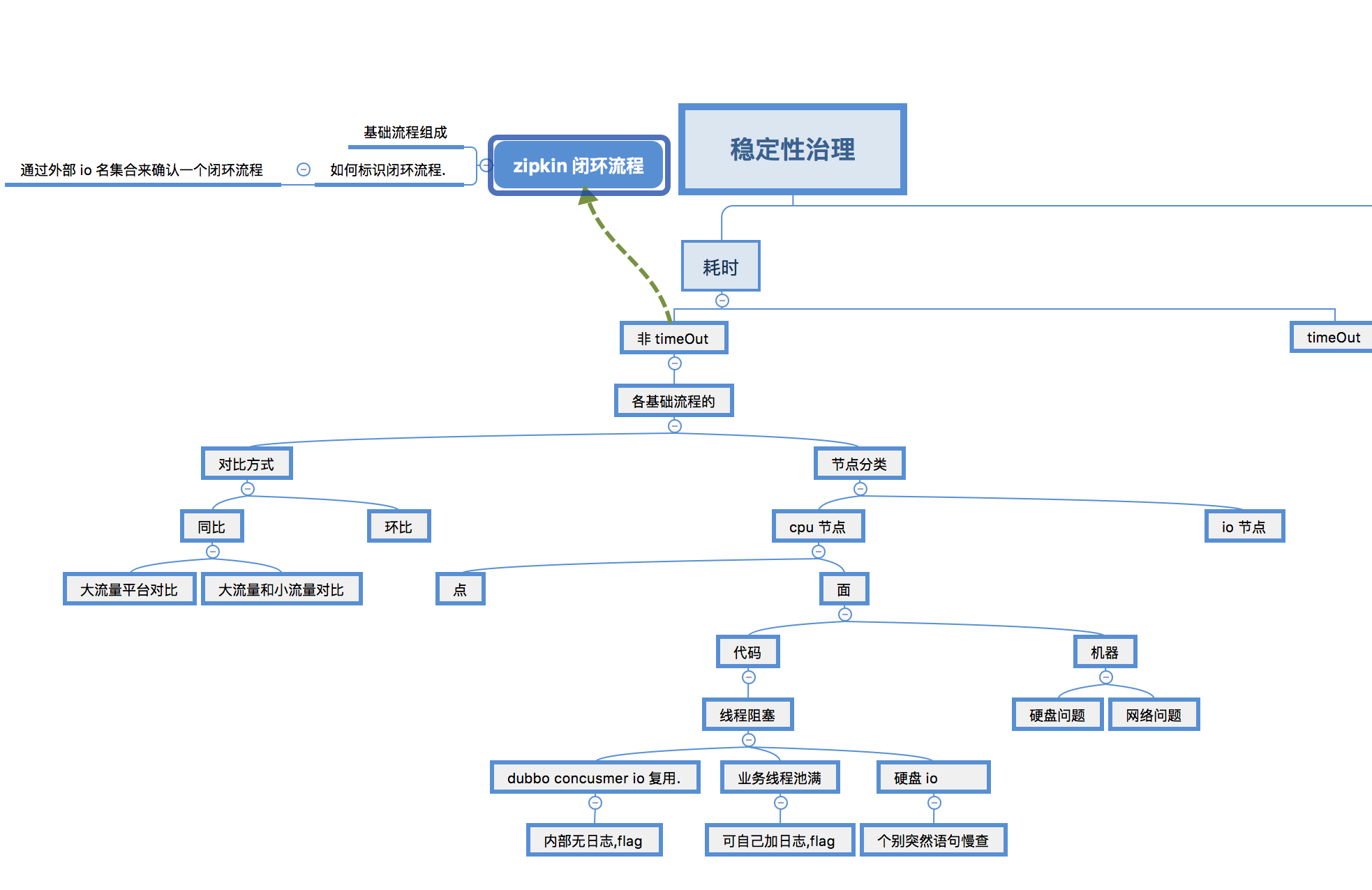
何为异常:
前提: 大流量下,稳定性才显得重要.否则不用关心. 这种业务平台也要有机会遇到.
作用: 现有数据收集,展示,再有智能数据处理,最终告警,形成告警时间轴,并分析同时间内[分钟级]的告警点在整体监控点下的关系,排除非因告警点.
1. 业务异常. - 简单.
2. 稳定性因素导致的异常.特别是雪崩时,很难排查.
2.1 耗时对比增加. 同比增加, 环比增加, 同期平均值增加,小流量平台对比. [ ]
2.2 耗时超时变成 error
按严重程度:
1. 大量error异常 [这个是老的监控平台优点,通过error查看flag,太迟了]
2. 无error异常 [ 接口耗时增加,io总量增加提前暴露性能问题,新监控平台小米优点. 通过报警时间轴去定位问题,最好报警阈值时时可调 ] 有时候只有几台机器异常.
这种极有可能 1. 某些 io 调用耗时增加(未监控) 2. 线程池满等待 3. dubbo tcp 复用等待 4.swap 耗时等待 5.gc 耗时 6. 线程加锁等待
参照系: 大流量自身同期, 大流量自身环期. 正常的小流量平台下自身同期,自身环期. 两个比例. 1.平均放大比 放大比异常的.
2.1 同比环比对比
同平台: 同比,环比;
大小平台: 先取个平均放大值,然后放大值异常的报警]
如果本身就抖动,那就先把抖动问题解决掉, 0.有些内部没有问题,来源于外部不同输入,数据库响应抖动,偶发性的请求冷数据. 1. 根据业务场景的业务配置 例如gc 2. 例如更换引擎 , 随机读太多,改用ssd 硬件架构. 3. 有些是外部系统导致的, 那就没办法了. 比如外部支付网络 只能取值40-60%这部分统计值作为平均考量. 或者换用供应商,多渠道控制. 也可以辅助外部人员本质上也要查,要看对应提供方的代码和日志,点问题,面问题, 可能需要服务提供方提供对应的数据,对应的 flag 的接收和返回的时间点. 并且要保证机器时钟的准确性.
所以好的设计是不依赖外部方,让外部放依赖我们. 限制调用量. 通知总是需要的,限制timeOut 时间.
即使同一个接口,也要比对参数是否相同. 不同的人属性不同,走的逻辑和外部 io 路径不同. 可以对有限值的参数和耗时进行聚类,聚类完之后进行监控,然后进行监控.这就没法监控了. 这个 type 值最好是结构化的,有业务来确定,通过注解等方式,而不是从文本来解析出来.这种解析太多了.
3. 压测异常. 压测突破边界点, 耗时边界点,导致增加的请求流量,全部变成了 error 异常, 故流量增加,但是正常返回反而下降.
那么zipkin整个时间轴上的统计纬度有多少.
说耗时: A --> B 接口名. from纬度比较 其他参数相同, to纬度比较, time纬度比较(同比,环比) 大流量和小流量比较.
不同的接口名比较没意义,不同的 内存执行区间比较也没意义(而且重构了,有可能变化很大. 只能同一时间点比较,前后比较)
同期比异常: 流量异常, 耗时异常,请求数量异常
原因: gc导致偶发[和swap一起时耗时更长, 大内存耗时也长], 营销活动导致偶发.
边界: 1. 内部线程池边界[订单因为下游耗时增加,导致线程池耗尽,新的请求排队 fastError ], 2.有效耗时边界[ timeOut , 直接fastError], 3. io边界[dubbo 连接共用,导致定时任务时,突然导致连接满额, 导致无法可用] 4. mysql线程池耗满 [ 有慢查,就挂了. ]
环比异常: 定时任务,gc,定点营销,催款短信
方法论:
监控+及早报警:
-
- 通过zipkin耗时优化问题. 及早发现及早优化.
- 通过调用数量优化问题
- 通过压测发现问题.
- 压测能突破边际,本来只是耗时增加的,后来演变成 exception 抛出
- bean 数量也能极大放大,便于定位
最细粒度报警. fromIp 接口 toIp. 内存执行报警. 对gc监控有用. 外部都不变,但是内部变化了. 有时候监控报警不全,需要自己在去排查.
1. 大面积报警
报警顺序排放.
2. 少部分报警
场景 :
1. 观察线上耗时统计, 发现间歇性耗时抖动? [之前写的例子,犯了 复合节区间的大忌. ]
2. 更甚至直接导致oom
雪崩分析时要看异常报警时间轴, 和平时抖动性分析 需要看 异常报警时间轴,异常同比/环比抖动超过20%的图.
压测,稳定性建设分析看整个链路耗时情况. 特别是异常抖动点的耗时情况,流量情况,io 情况.
分析:
* 报警信息
报警计算方式:
同比(雪崩等),环比(抖动,毛刺,斜率超过多少就算毛刺. 何为毛刺?,稳定性排查 )
报警计算阈值动态配置:
这些信息可以时时调整报警额度值,动态计算一遍,然后展现) 按同粒度+上下游的时间轴展现
* 报警信息分类:
* 耗时抖动报警
* 流量抖动报警
* io 超量报警
* 异常码 error 报警
* 点
接口维度: 流量大小,耗时,次数. 且要有流量入口 type,这个最好有前缀是app_入口_app 名_接口名[].
zipkin 时间轴,能够很快的识别出 网络耗时, 内部执行耗时,外部 io 耗时 这些都是关键的 耗时 key. [所以一定要把 mysql, dubbo, 文件操作都监控起来. 不然有些耗时 key 可能是混合了 内存执行+外部io执行]
内部的内存耗时如何统计?
通过 zipkin 的sr (server 接受) 和 cs(客户端发送)的时间差来定义. cs-cr (两个流量中间)这个需要有框架来完成. 特别是内部出现多线程的情况.
一个大系统由 N 个小业务系统组成, 虽然大系统找原因,拆解到各个小业务系统上. 雪崩时定位出各个系统的初始异常原因. 然后切换到下游系统或者面原因定位. ( 所以不如整体定位, 不对粗粒度的分析.)
优点: 以往只有系统级的监控(), 有了接口级的以后就好定位很多. 但是内存操作怎么定位?
* 面
外部网络, 内部gc ,磁盘问题,网络
* 另外一种是达到耗时边界, 耗时可能只增加了20ms,但是已经超过1s 中. 导致 error 报警.这种需要平时稳定性治理,耗时从高到低排查问题.耗时到底在哪里?
* 时间点刚好是定时任务执行点
排查代码,看是否有优化空间
* 规律性不明显
查看是否 gc 导致? gc 耗时过长原因是 swap http://lovesoo.org/linux-sar-command-detailed.html sar -W https://blog.csdn.net/rlhua/article/details/24669037
相关工具和命令:
可视化 gc 和耗时时间轴.
效果 :
1. jmap -histo 46454 | head -n 20
要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看