1 下载安装包

2 上传并解压(不需要修改配置文件)

tar -zxvf spark-1.6.2-bin-hadoop2.6.tgz mv spark-1.6.2-bin-hadoop2.6 spark

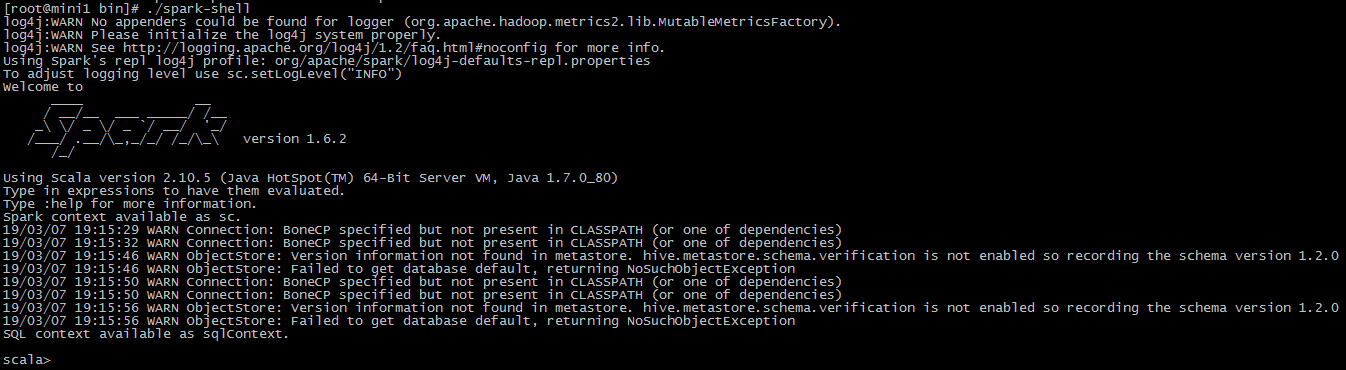
3 启动
进入spark/bin
./spark-shell
计算单词出现次数
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

按照单词出现次数降序排列
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect

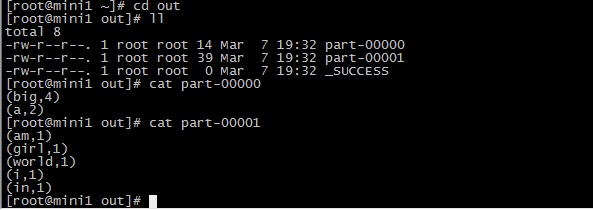
把计算结果保存
sc.textFile("/root/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile("/root/out")