原文链接:https://blog.csdn.net/weixin_42518879/article/details/83959319
主要内容:机器学习中常见的几种评价指标,它们各自的含义和计算(注意本文针对二元分类器!)
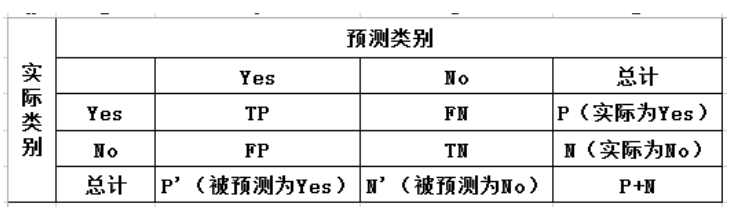
1、混淆矩阵
True Positive(真正,TP):将正类预测为正类的数目
True Negative(真负, TN):将负类预测为负类的数目
False Positive(假正,FP):将负类预测为正类的数目(Type I error)
False Negative(假负,FN):将正类预测为负类的数目(Type II error)
2、精确率(Precision)
精确率表示被分为正例的实例中实际为里正例的比例。
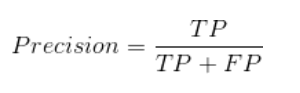
3、召回率(Recall)
召回率表示所有实际为正例的实例被预测为正例的比例,等价于灵敏度(Sensitive)
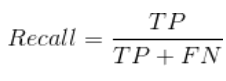
4、综合评价指标(F-Measure)
Precision和Recall有时会出现矛盾的情况,为了综合考虑他们,我们常用的指标就是F-Measure,F值越高证明模型越有效。
F-Measure是Precision和Recall的加权调和平均。
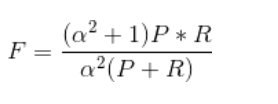
当参数α=1时,就是我们最常见的F1。
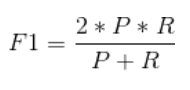
5、ROC曲线和AUC(Area Under Curve)
在二分类中,我们通常会对每个样本计算一个概率值,再根据概率值判断该样本所属的类别,那么这时就需要设定一个阈值来划定正负类。这个阈值的设定会直接影响到Precision和Recall,但是对于AUC的影响较小,因此我们通过做ROC曲线并计算AUC的值来对模型进行更加综合的评价。
ROC曲线的作图原理如下:假设我们的测试集一共有n个样本,那么我们会对每个样本得到一个概率,以每个概率为阈值计算此时的"True Positive Rate"和"False Positive Rate"值,共得到n对值(n个点)。然后以"True Positive Rate"作为纵轴,"False Positive Rate"作为横轴,以这n个点的数据作图画出ROC曲线。
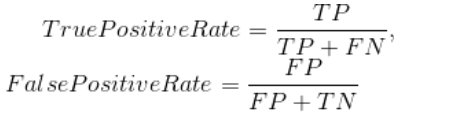
AUC(Area Under Curve)即为ROC曲线下的面积。
6、准确率(Accuracy)
准确率是我们最常用的评价指标,就是所有实例中被预测正确的比例,但是当数据存在不平衡时,准确率不能很全面地评价模型表现的好坏。
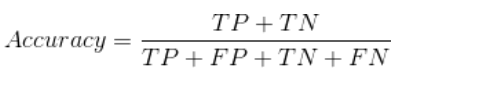
7、具体计算
以上各种评价指标的计算都可以通过sklearn.metrics中的相关功能实现,参考链接:sklearn.metrics中的评估方法介绍