一、中文分词的介绍
中文分词就是通过计算机将句子转化成词的表示,自动识别句子中的词,在词与词之间加入边界分隔符,分割出各个词汇。
中文分词有两大难点:
1.歧义
原文:以前喜欢一个人,现在喜欢一个人
这里有两个「一个人」,但是代表的意思完全不一样。
2.分词界限
原文:这杯水还没有冷
分词一: 这 / 杯 / 水 / 还 / 没有 / 冷
分词二: 这 / 杯 / 水 / 还没 / 有 / 冷
分词三: 这 / 杯 / 水 / 还没有 / 冷
可以说中文分词没有标准的分词算法,只有对应不同场景更适合的分词算法。
二、中文分词的方法
主要可以分为三个方法:机械分词方法,统计分词方法,以及两种结合起来的分词
机械分词方法又叫做基于规则的分词方法:这种分词方法按照一定的规则将待处理的字符串与一个词表词典中的词进行逐一匹配,若在词典中找到某个字符串,则切分,否则不切分。
按照匹配规则的方式,又可以分为:正向最大匹配法,逆向最大匹配法和双向匹配法三种
机械分词方法
1.正向最大匹配法(Maximum Match Method,MM 法)是指从左向右按最大原则与词典里面的词进行匹配。假设词典中最长词是 mm 个字,那么从待切分文本的最左边取 mm 个字符与词典进行匹配,如果匹配成功,则分词。
如果匹配不成功,那么取 m−1m−1 个字符与词典匹配,一直取直到成功匹配为止。流程图如下:
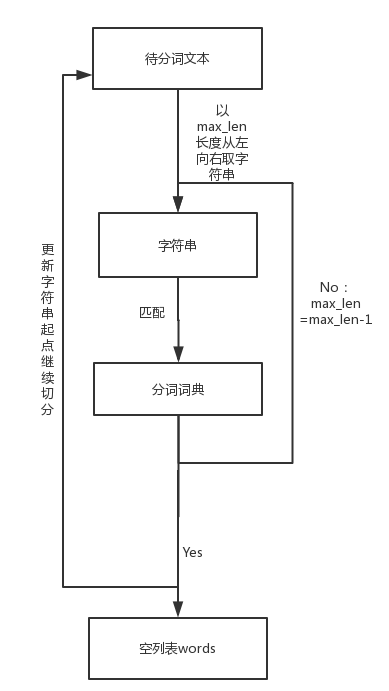
算法步骤:
- 导入分词词典
dic,待分词文本text,创建空集words。 - 遍历分词词典,找到最长词的长度,
max_len_word。 - 将待分词文本从左向右取
max_len=max_len_word个字符作为待匹配字符串word。 - 将
word与词典dic匹配 - 若匹配失败,则
max_len = max_len - 1,然后 - 重复 3 - 4 步骤
- 匹配成功,将
word添加进words当中。 - 去掉待分词文本前
max_len个字符 - 重置
max_len值为max_len_word - 重复 3 - 8 步骤
- 返回列表
words
2.逆向最大匹配法( Reverse Maximum Match Method, RMM 法)的原理与正向法基本相同,唯一不同的就是切分的方向与 MM 法相反。逆向法从文本末端开始匹配,每次用末端的最长词长度个字符进行匹配。
另外,由于汉语言结构的问题,里面有许多偏正短语,即结构是:
- 定语 + 中心词(名、代):(祖国)大地、(一朵)茶花、(前进)的步伐。
- 状语 + 中心词(动、形):(很)好看、(独立)思考、(慢慢)地走。
因此,如果采用逆向匹配法,可以适当提高一些精确度。换句话说,使用逆向匹配法要比正向匹配法的误差要小。
3.双向最大匹配法(Bi-direction Matching Method ,BMM)则是将正向匹配法得到的分词结果与逆向匹配法得到的分词结果进行比较,然后按照最大匹配原则,选取次数切分最少的作为结果。
基于统计规则的中文分词
基于统计规则的中文分词算法逐渐成为现在的主流分词方法。其目的是在给定大量已经分词的文本的前提下,利用统计机器学习的模型学习词语切分的规律。
统计分词可以这样理解:我们已经有一个由很多个文本组成的的语料库 D ,现在有一个文本需要我们分词, 我有一个苹果 ,其中两个相连的字 苹 果 在不同的文本中连续出现的次数越多,就说明这两个相连字很可能构成一个词 苹果。与此同时 个 苹 这两个相连的词在别的文本中连续出现的次数很少,就说明这两个相连的字不太可能构成一个词 个苹 。所以,我们就可以利用这个统计规则来反应字与字成词的可信度。当字连续组合的概率高过一个临界值时,就认为该组合构成了一个词语。
- 建立统计语言模型。
- 对句子进行单词划分,然后对划分结果进行概率计算,获得概率最大的分词方式。这里就需要用到统计学习算法,如隐马可夫,条件随机场等。
1.语言模型
语言模型又叫做 N 元文法模型(N-gram)。按照书面解释来说,以长度为 m 的字符串,目的是确定其概率分布 P(w1,w2,⋯,wm),其中 w1到 wm 依次为文本中的每个词语。
这个概率可以用链式法则来求:即
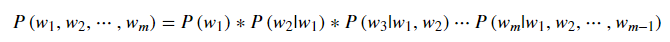
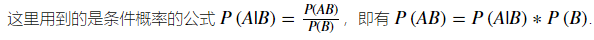
因为我们是基于语料库的统计模型,所以上面的所有概率都可以通过对语料库的统计计算获得。但是,虽然采用的方法简单粗暴,但是观察上面的式子可以知道,当语料很大的时候,公式从第三项开始计算量就已经十分庞大了。
因此,在语言模型的基础上,衍生出了 nn 元模型。所谓的 nn 元就是在估算条件概率时,忽略掉大于 nn 个或者等于 nn 个上文词的的影响。即将上式子中的每一项简化

可以看到,当 n=1n=1 时,词与词之间基本没有关系。随着 nn 逐渐增大,每个模型与上文的关系越密切,包含的次序信息也越丰富,但是与此同时计算量也随之大大增加。所以常用的一般为二元模型,三元模型。
2.马可夫模型
在天气预测时候,假如我们知道晴雨云天气之间的相互转换概率,如下图:
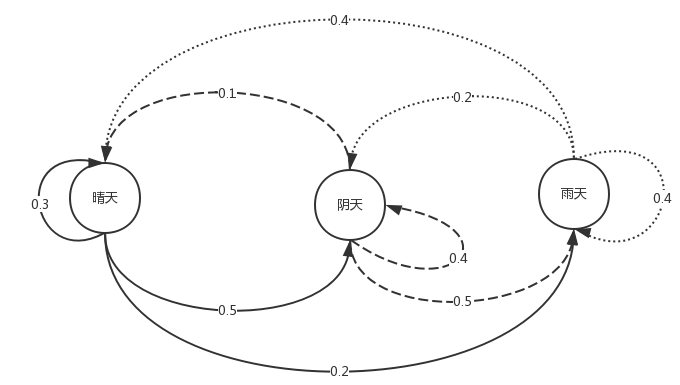
有了这个转移概率图,假如我们知道今天的天气情况的时候,我们就能推测出明天的天气状况。若今天为晴,那么明天推测为阴天(取其中概率最大的)。这样一种类型就是马可夫模型。
3.隐马可夫模型
隐马可夫(Hidden Markov Method , HMM)模型是在马可夫模型的特殊情况,更进一步的,我们在上面马尔可夫的模型中,添加更多的限制条件。
- 假若我们不知道未来几天的天气情况。
- 我们知道未来几天的空气湿度情况。
- 我们知道第一天天气各种情况的概率。
- 为我们知道某种天气状态条件下,空气湿度的概率。
- 我们知道前一天天气情况转移到下一个天气情况的概率。
在这个例子当中,未来几天天气状态的序列就叫做隐藏状态序列。而我们唯一能观测到的是,未来几天空气中的湿度,这些湿度状态就叫做可观测状态。
因为空气湿度与天气有关,因此我们想要通过可以观测到的空气湿度这一可观测状态序列来推测出未来三天的天气状态这一隐藏状态序列。这类型的问题,就叫做隐马可夫模型。
4.jieba中文分词
Python 的第三方的中文分词工具 jieba,省去我们在实际应用中省掉训练分词马可夫模型的繁琐步骤。并且,jieba 工具用的 HMM算 法与数据结构算法结合使用的方法,比直接单独使用 HMM 来分词效率高很多,准确率也高很多。
首先需要下载第三方的 jieba 工具库:https://github.com/fxsjy/jieba
下面我们就来通过例子看下 jieba 分词的方法:
- 全模式
- 精确模式
- 搜索引擎模式
import jieba #全模式 string = '我来到北京清华大学' seg_list = jieba.cut(string, cut_all=True) #无法直接显示,若想要显示,可以下面这样。用 ‘/’ 把生成器中的词串起来显示。这个方法在下面提到的精确模式和搜索引擎模式中同样适用。 '/'.join(seg_list) #精确模式 seg_list = jieba.cut(string, cut_all=False) #搜索引擎模式 seg_list = jieba.cut_for_search(string)
jieba 在某些特定的情况下来分词,可能表现不是很好。比如一篇非常专业的医学论文,含有一些特定领域的专有名词。
不过,为了解决此类问题, jieba 允许用户自己添加该领域的自定义词典,我们可以提前把这些词加进自定义词典当中,来增加分词的效果。调用的方法是:jieba.load_userdic()。
自定义词典的格式要求每一行一个词,有三个部分,词语,词频(词语出现的频率),词性(名词,动词……)。其中,词频和词性可省略。用户自定义词典可以直接用记事本创立即可,但是需要以 utf-8 编码模式保存。 格式像下面这样:
除了使用 jieba.load_userdic() 函数在分词开始前加载自定义词典之外,还有两种方法在可以在程序中动态修改词典。
-
使用
add_word(word, freq=None, tag=None)和del_word(word)可在程序中动态修改词典。 -
使用
suggest_freq(segment, tune=True)可调节单个词语的词频,使其能(或不能)被分出来。
使用自定义词典,有时候可以取得更好的效果,例如「今天天气不错」这句话,本应该分出「今天」、「天气」、「不错」三个词,而来看一下直接使用结巴分词的结果:
string = '今天天气不错' #添加自己的词 jieba.suggest_freq(('今天', '天气'), True) seg_list = jieba.cut(string, cut_all=False) #从词典中删除词语 jieba.del_word('今天天气') #强制调高词频,使其分为一个词 jieba.add_word('台中')